 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEXIS: LatEnt ProXimal Interaction Signatures for 3D HOI from an Image
Apr 22, 2026Reconstructing 3D Human-Object Interaction from an RGB image is essential for perceptive systems. Yet, this remains challenging as it requires capturing the subtle physical coupling between the body and objects. While current methods rely on sparse, binary contact cues, these fail to model the continuous proximity and dense spatial relationships that characterize natural interactions. We address this limitation via InterFields, a representation that encodes dense, continuous proximity across the entire body and object surfaces. However, inferring these fields from single images is inherently ill-posed. To tackle this, our intuition is that interaction patterns are characteristically structured by the action and object geometry. We capture this structure in LEXIS, a novel discrete manifold of interaction signatures learned via a VQ-VAE. We then develop LEXIS-Flow, a diffusion framework that leverages LEXIS signatures to estimate human and object meshes alongside their InterFields. Notably, these InterFields help in a guided refinement that ensures physically-plausible, proximity-aware reconstructions without requiring post-hoc optimization. Evaluation on Open3DHOI and BEHAVE shows that LEXIS-Flow significantly outperforms existing SotA baselines in reconstruction, contact, and proximity quality. Our approach not only improves generalization but also yields reconstructions perceived as more realistic, moving us closer to holistic 3D scene understanding. Code & models will be public at https://anticdimi.github.io/lexis.
EgoPoseFormer v2: Accurate Egocentric Human Motion Estimation for AR/VR
Mar 04, 2026Egocentric human motion estimation is essential for AR/VR experiences, yet remains challenging due to limited body coverage from the egocentric viewpoint, frequent occlusions, and scarce labeled data. We present EgoPoseFormer v2, a method that addresses these challenges through two key contributions: (1) a transformer-based model for temporally consistent and spatially grounded body pose estimation, and (2) an auto-labeling system that enables the use of large unlabeled datasets for training. Our model is fully differentiable, introduces identity-conditioned queries, multi-view spatial refinement, causal temporal attention, and supports both keypoints and parametric body representations under a constant compute budget. The auto-labeling system scales learning to tens of millions of unlabeled frames via uncertainty-aware semi-supervised training. The system follows a teacher-student schema to generate pseudo-labels and guide training with uncertainty distillation, enabling the model to generalize to different environments. On the EgoBody3M benchmark, with a 0.8 ms latency on GPU, our model outperforms two state-of-the-art methods by 12.2% and 19.4% in accuracy, and reduces temporal jitter by 22.2% and 51.7%. Furthermore, our auto-labeling system further improves the wrist MPJPE by 13.1%.
PICO: Reconstructing 3D People In Contact with Objects
Apr 24, 2025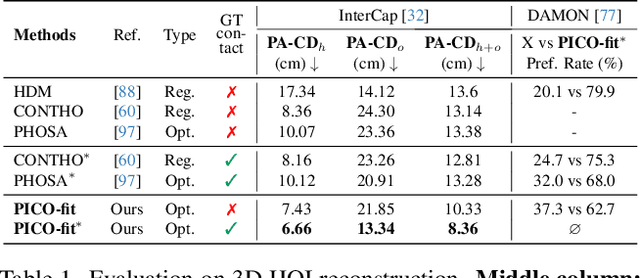


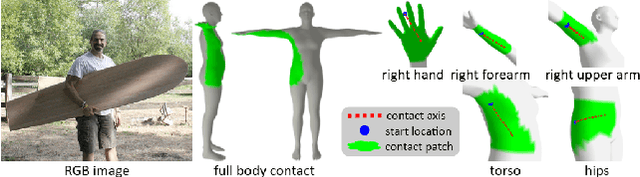
Recovering 3D Human-Object Interaction (HOI) from single color images is challenging due to depth ambiguities, occlusions, and the huge variation in object shape and appearance. Thus, past work requires controlled settings such as known object shapes and contacts, and tackles only limited object classes. Instead, we need methods that generalize to natural images and novel object classes. We tackle this in two main ways: (1) We collect PICO-db, a new dataset of natural images uniquely paired with dense 3D contact on both body and object meshes. To this end, we use images from the recent DAMON dataset that are paired with contacts, but these contacts are only annotated on a canonical 3D body. In contrast, we seek contact labels on both the body and the object. To infer these given an image, we retrieve an appropriate 3D object mesh from a database by leveraging vision foundation models. Then, we project DAMON's body contact patches onto the object via a novel method needing only 2 clicks per patch. This minimal human input establishes rich contact correspondences between bodies and objects. (2) We exploit our new dataset of contact correspondences in a novel render-and-compare fitting method, called PICO-fit, to recover 3D body and object meshes in interaction. PICO-fit infers contact for the SMPL-X body, retrieves a likely 3D object mesh and contact from PICO-db for that object, and uses the contact to iteratively fit the 3D body and object meshes to image evidence via optimization. Uniquely, PICO-fit works well for many object categories that no existing method can tackle. This is crucial to enable HOI understanding to scale in the wild. Our data and code are available at https://pico.is.tue.mpg.de.
InteractVLM: 3D Interaction Reasoning from 2D Foundational Models
Apr 07, 2025We introduce InteractVLM, a novel method to estimate 3D contact points on human bodies and objects from single in-the-wild images, enabling accurate human-object joint reconstruction in 3D. This is challenging due to occlusions, depth ambiguities, and widely varying object shapes. Existing methods rely on 3D contact annotations collected via expensive motion-capture systems or tedious manual labeling, limiting scalability and generalization. To overcome this, InteractVLM harnesses the broad visual knowledge of large Vision-Language Models (VLMs), fine-tuned with limited 3D contact data. However, directly applying these models is non-trivial, as they reason only in 2D, while human-object contact is inherently 3D. Thus we introduce a novel Render-Localize-Lift module that: (1) embeds 3D body and object surfaces in 2D space via multi-view rendering, (2) trains a novel multi-view localization model (MV-Loc) to infer contacts in 2D, and (3) lifts these to 3D. Additionally, we propose a new task called Semantic Human Contact estimation, where human contact predictions are conditioned explicitly on object semantics, enabling richer interaction modeling. InteractVLM outperforms existing work on contact estimation and also facilitates 3D reconstruction from an in-the wild image. Code and models are available at https://interactvlm.is.tue.mpg.de.
SDFit: 3D Object Pose and Shape by Fitting a Morphable SDF to a Single Image
Sep 24, 2024
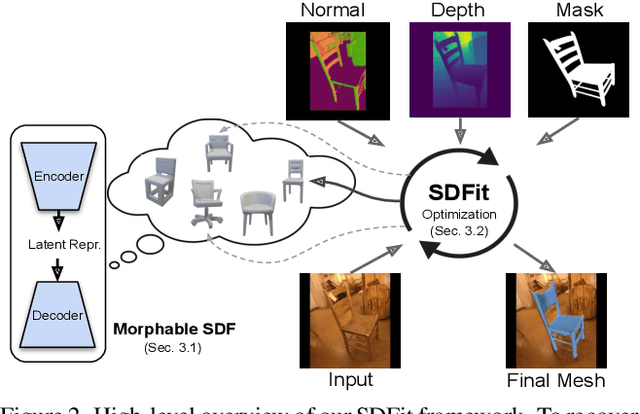


We focus on recovering 3D object pose and shape from single images. This is highly challenging due to strong (self-)occlusions, depth ambiguities, the enormous shape variance, and lack of 3D ground truth for natural images. Recent work relies mostly on learning from finite datasets, so it struggles generalizing, while it focuses mostly on the shape itself, largely ignoring the alignment with pixels. Moreover, it performs feed-forward inference, so it cannot refine estimates. We tackle these limitations with a novel framework, called SDFit. To this end, we make three key observations: (1) Learned signed-distance-function (SDF) models act as a strong morphable shape prior. (2) Foundational models embed 2D images and 3D shapes in a joint space, and (3) also infer rich features from images. SDFit exploits these as follows. First, it uses a category-level morphable SDF (mSDF) model, called DIT, to generate 3D shape hypotheses. This mSDF is initialized by querying OpenShape's latent space conditioned on the input image. Then, it computes 2D-to-3D correspondences, by extracting and matching features from the image and mSDF. Last, it fits the mSDF to the image in an render-and-compare fashion, to iteratively refine estimates. We evaluate SDFit on the Pix3D and Pascal3D+ datasets of real-world images. SDFit performs roughly on par with state-of-the-art learned methods, but, uniquely, requires no re-training. Thus, SDFit is promising for generalizing in the wild, paving the way for future research. Code will be released
TokenHMR: Advancing Human Mesh Recovery with a Tokenized Pose Representation
Apr 25, 2024We address the problem of regressing 3D human pose and shape from a single image, with a focus on 3D accuracy. The current best methods leverage large datasets of 3D pseudo-ground-truth (p-GT) and 2D keypoints, leading to robust performance. With such methods, we observe a paradoxical decline in 3D pose accuracy with increasing 2D accuracy. This is caused by biases in the p-GT and the use of an approximate camera projection model. We quantify the error induced by current camera models and show that fitting 2D keypoints and p-GT accurately causes incorrect 3D poses. Our analysis defines the invalid distances within which minimizing 2D and p-GT losses is detrimental. We use this to formulate a new loss Threshold-Adaptive Loss Scaling (TALS) that penalizes gross 2D and p-GT losses but not smaller ones. With such a loss, there are many 3D poses that could equally explain the 2D evidence. To reduce this ambiguity we need a prior over valid human poses but such priors can introduce unwanted bias. To address this, we exploit a tokenized representation of human pose and reformulate the problem as token prediction. This restricts the estimated poses to the space of valid poses, effectively providing a uniform prior. Extensive experiments on the EMDB and 3DPW datasets show that our reformulated keypoint loss and tokenization allows us to train on in-the-wild data while improving 3D accuracy over the state-of-the-art. Our models and code are available for research at https://tokenhmr.is.tue.mpg.de.
PoseGPT: Chatting about 3D Human Pose
Nov 30, 2023



We introduce PoseGPT, a framework employing Large Language Models (LLMs) to understand and reason about 3D human poses from images or textual descriptions. Our work is motivated by the human ability to intuitively understand postures from a single image or a brief description, a process that intertwines image interpretation, world knowledge, and an understanding of body language. Traditional human pose estimation methods, whether image-based or text-based, often lack holistic scene comprehension and nuanced reasoning, leading to a disconnect between visual data and its real-world implications. PoseGPT addresses these limitations by embedding SMPL poses as a distinct signal token within a multi-modal LLM, enabling direct generation of 3D body poses from both textual and visual inputs. This approach not only simplifies pose prediction but also empowers LLMs to apply their world knowledge in reasoning about human poses, fostering two advanced tasks: speculative pose generation and reasoning about pose estimation. These tasks involve reasoning about humans to generate 3D poses from subtle text queries, possibly accompanied by images. We establish benchmarks for these tasks, moving beyond traditional 3D pose generation and estimation methods. Our results show that PoseGPT outperforms existing multimodal LLMs and task-sepcific methods on these newly proposed tasks. Furthermore, PoseGPT's ability to understand and generate 3D human poses based on complex reasoning opens new directions in human pose analysis.
POCO: 3D Pose and Shape Estimation with Confidence
Aug 24, 2023The regression of 3D Human Pose and Shape (HPS) from an image is becoming increasingly accurate. This makes the results useful for downstream tasks like human action recognition or 3D graphics. Yet, no regressor is perfect, and accuracy can be affected by ambiguous image evidence or by poses and appearance that are unseen during training. Most current HPS regressors, however, do not report the confidence of their outputs, meaning that downstream tasks cannot differentiate accurate estimates from inaccurate ones. To address this, we develop POCO, a novel framework for training HPS regressors to estimate not only a 3D human body, but also their confidence, in a single feed-forward pass. Specifically, POCO estimates both the 3D body pose and a per-sample variance. The key idea is to introduce a Dual Conditioning Strategy (DCS) for regressing uncertainty that is highly correlated to pose reconstruction quality. The POCO framework can be applied to any HPS regressor and here we evaluate it by modifying HMR, PARE, and CLIFF. In all cases, training the network to reason about uncertainty helps it learn to more accurately estimate 3D pose. While this was not our goal, the improvement is modest but consistent. Our main motivation is to provide uncertainty estimates for downstream tasks; we demonstrate this in two ways: (1) We use the confidence estimates to bootstrap HPS training. Given unlabelled image data, we take the confident estimates of a POCO-trained regressor as pseudo ground truth. Retraining with this automatically-curated data improves accuracy. (2) We exploit uncertainty in video pose estimation by automatically identifying uncertain frames (e.g. due to occlusion) and inpainting these from confident frames. Code and models will be available for research at https://poco.is.tue.mpg.de.
Detecting Human-Object Contact in Images
Mar 06, 2023Humans constantly contact objects to move and perform tasks. Thus, detecting human-object contact is important for building human-centered artificial intelligence. However, there exists no robust method to detect contact between the body and the scene from an image, and there exists no dataset to learn such a detector. We fill this gap with HOT ("Human-Object conTact"), a new dataset of human-object contacts for images. To build HOT, we use two data sources: (1) We use the PROX dataset of 3D human meshes moving in 3D scenes, and automatically annotate 2D image areas for contact via 3D mesh proximity and projection. (2) We use the V-COCO, HAKE and Watch-n-Patch datasets, and ask trained annotators to draw polygons for the 2D image areas where contact takes place. We also annotate the involved body part of the human body. We use our HOT dataset to train a new contact detector, which takes a single color image as input, and outputs 2D contact heatmaps as well as the body-part labels that are in contact. This is a new and challenging task that extends current foot-ground or hand-object contact detectors to the full generality of the whole body. The detector uses a part-attention branch to guide contact estimation through the context of the surrounding body parts and scene. We evaluate our detector extensively, and quantitative results show that our model outperforms baselines, and that all components contribute to better performance. Results on images from an online repository show reasonable detections and generalizability.
Learning to Regress Bodies from Images using Differentiable Semantic Rendering
Oct 07, 2021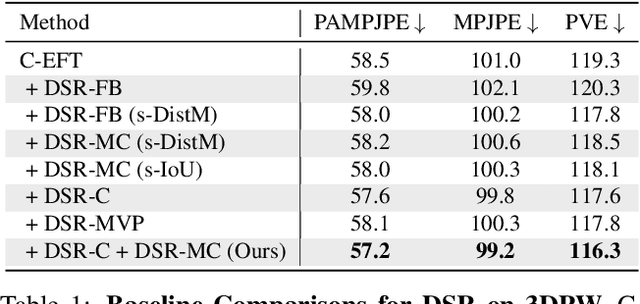
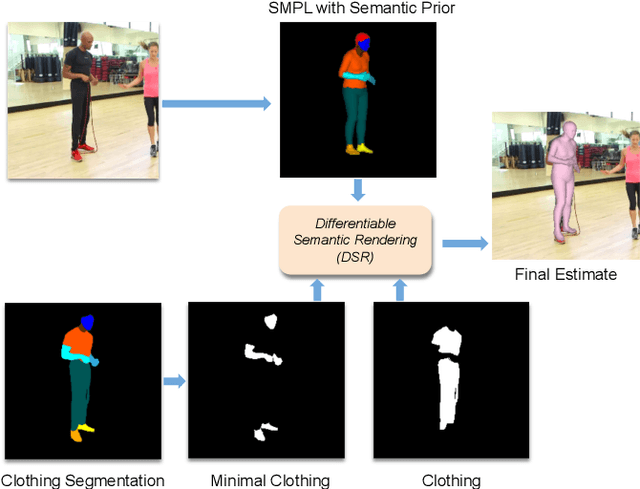

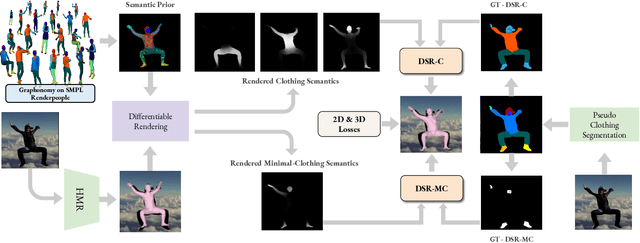
Learning to regress 3D human body shape and pose (e.g.~SMPL parameters) from monocular images typically exploits losses on 2D keypoints, silhouettes, and/or part-segmentation when 3D training data is not available. Such losses, however, are limited because 2D keypoints do not supervise body shape and segmentations of people in clothing do not match projected minimally-clothed SMPL shapes. To exploit richer image information about clothed people, we introduce higher-level semantic information about clothing to penalize clothed and non-clothed regions of the image differently. To do so, we train a body regressor using a novel Differentiable Semantic Rendering - DSR loss. For Minimally-Clothed regions, we define the DSR-MC loss, which encourages a tight match between a rendered SMPL body and the minimally-clothed regions of the image. For clothed regions, we define the DSR-C loss to encourage the rendered SMPL body to be inside the clothing mask. To ensure end-to-end differentiable training, we learn a semantic clothing prior for SMPL vertices from thousands of clothed human scans. We perform extensive qualitative and quantitative experiments to evaluate the role of clothing semantics on the accuracy of 3D human pose and shape estimation. We outperform all previous state-of-the-art methods on 3DPW and Human3.6M and obtain on par results on MPI-INF-3DHP. Code and trained models are available for research at https://dsr.is.tue.mpg.de/.