 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGravity-Aware Monocular 3D Human-Object Reconstruction
Aug 19, 2021

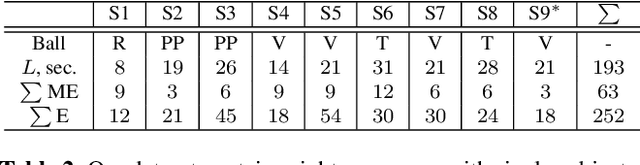
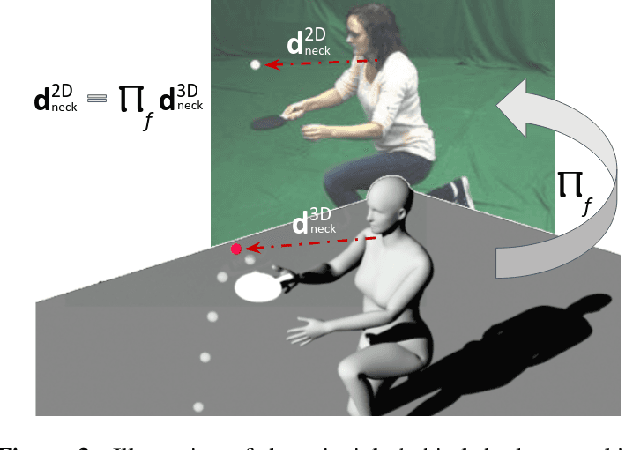
This paper proposes GraviCap, i.e., a new approach for joint markerless 3D human motion capture and object trajectory estimation from monocular RGB videos. We focus on scenes with objects partially observed during a free flight. In contrast to existing monocular methods, we can recover scale, object trajectories as well as human bone lengths in meters and the ground plane's orientation, thanks to the awareness of the gravity constraining object motions. Our objective function is parametrised by the object's initial velocity and position, gravity direction and focal length, and jointly optimised for one or several free flight episodes. The proposed human-object interaction constraints ensure geometric consistency of the 3D reconstructions and improved physical plausibility of human poses compared to the unconstrained case. We evaluate GraviCap on a new dataset with ground-truth annotations for persons and different objects undergoing free flights. In the experiments, our approach achieves state-of-the-art accuracy in 3D human motion capture on various metrics. We urge the reader to watch our supplementary video. Both the source code and the dataset are released; see http://4dqv.mpi-inf.mpg.de/GraviCap/.
* 12 pages, six figures, five tables; project webpage: http://4dqv.mpi-inf.mpg.de/GraviCap/
Multi-Person 3D Human Pose Estimation from Monocular Images
Sep 24, 2019
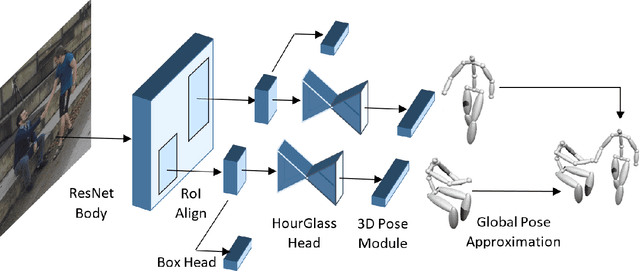

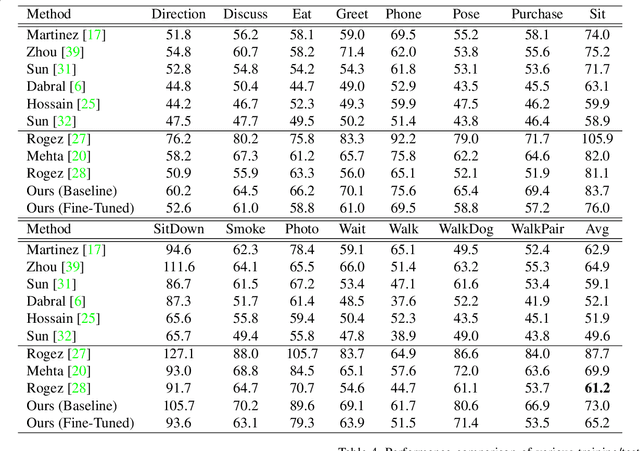
Multi-person 3D human pose estimation from a single image is a challenging problem, especially for in-the-wild settings due to the lack of 3D annotated data. We propose HG-RCNN, a Mask-RCNN based network that also leverages the benefits of the Hourglass architecture for multi-person 3D Human Pose Estimation. A two-staged approach is presented that first estimates the 2D keypoints in every Region of Interest (RoI) and then lifts the estimated keypoints to 3D. Finally, the estimated 3D poses are placed in camera-coordinates using weak-perspective projection assumption and joint optimization of focal length and root translations. The result is a simple and modular network for multi-person 3D human pose estimation that does not require any multi-person 3D pose dataset. Despite its simple formulation, HG-RCNN achieves the state-of-the-art results on MuPoTS-3D while also approximating the 3D pose in the camera-coordinate system.
ProtoGAN: Towards Few Shot Learning for Action Recognition
Sep 17, 2019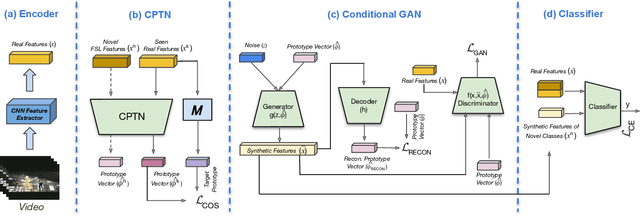
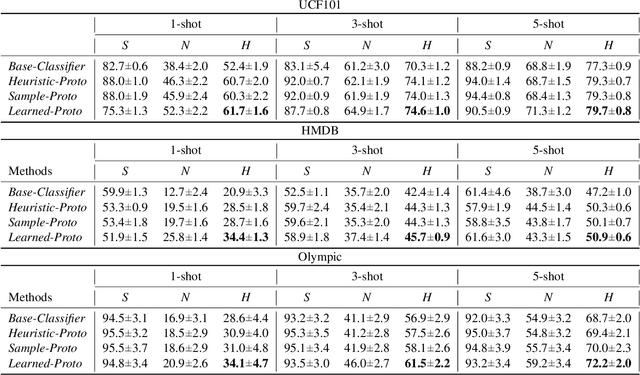
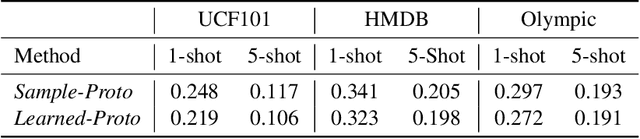
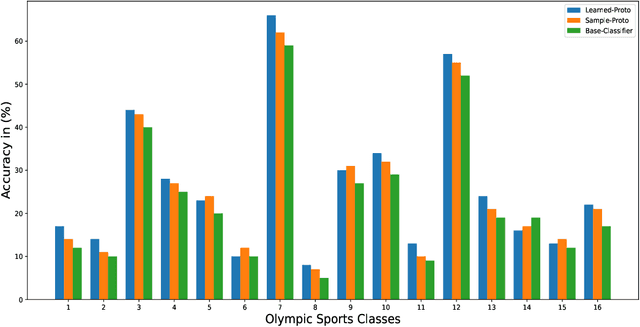
Few-shot learning (FSL) for action recognition is a challenging task of recognizing novel action categories which are represented by few instances in the training data. In a more generalized FSL setting (G-FSL), both seen as well as novel action categories need to be recognized. Conventional classifiers suffer due to inadequate data in FSL setting and inherent bias towards seen action categories in G-FSL setting. In this paper, we address this problem by proposing a novel ProtoGAN framework which synthesizes additional examples for novel categories by conditioning a conditional generative adversarial network with class prototype vectors. These class prototype vectors are learnt using a Class Prototype Transfer Network (CPTN) from examples of seen categories. Our synthesized examples for a novel class are semantically similar to real examples belonging to that class and is used to train a model exhibiting better generalization towards novel classes. We support our claim by performing extensive experiments on three datasets: UCF101, HMDB51 and Olympic-Sports. To the best of our knowledge, we are the first to report the results for G-FSL and provide a strong benchmark for future research. We also outperform the state-of-the-art method in FSL for all the aforementioned datasets.
Progression Modelling for Online and Early Gesture Detection
Sep 14, 2019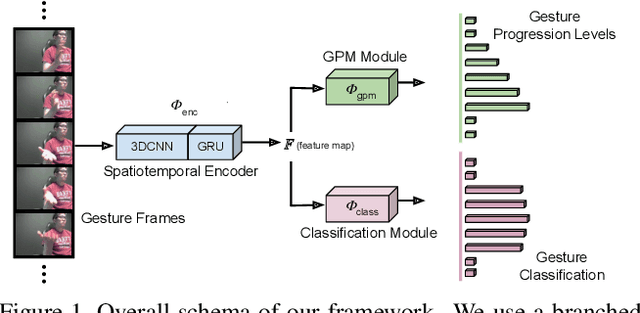
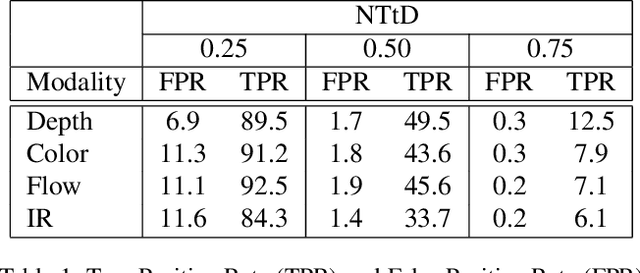

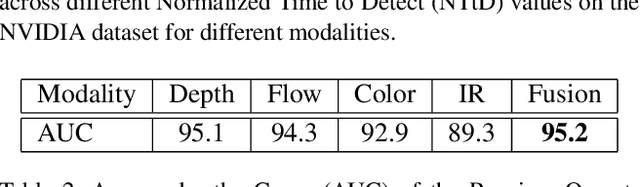
Online and Early detection of gestures is crucial for building touchless gesture based interfaces. These interfaces should operate on a stream of video frames instead of the complete video and detect the presence of gestures at an earlier stage than post-completion for providing real time user experience. To achieve this, it is important to recognize the progression of the gesture across different stages so that appropriate responses can be triggered on reaching the desired execution stage. To address this, we propose a simple yet effective multi-task learning framework which models the progression of the gesture along with frame level recognition. The proposed framework recognizes the gestures at an early stage with high precision and also achieves state-of-the-art recognition accuracy of 87.8% which is closer to human accuracy of 88.4% on the NVIDIA gesture dataset in the offline configuration and advances the state-of-the-art by more than 4%. We also introduce tightly segmented annotations for the NVIDIA gesture dataset and setup a strong baseline for gesture localization for this dataset. We also evaluate our framework on the Montalbano dataset and report competitive results.
On the Robustness of Human Pose Estimation
Aug 18, 2019
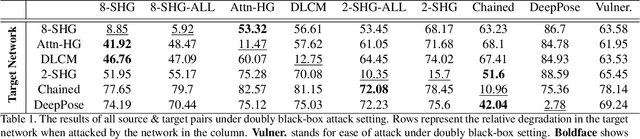

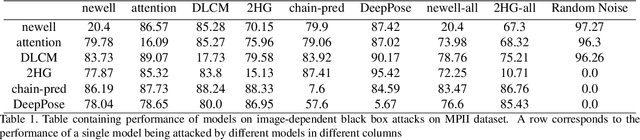
This paper provides, to the best of our knowledge, the first comprehensive and exhaustive study of adversarial attacks on human pose estimation. Besides highlighting the important differences between well-studied classification and human pose-estimation systems w.r.t. adversarial attacks, we also provide deep insights into the design choices of pose-estimation systems to shape future work. We compare the robustness of several pose-estimation architectures trained on the standard datasets, MPII and COCO. In doing so, we also explore the problem of attacking non-classification based networks including regression based networks, which has been virtually unexplored in the past. We find that compared to classification and semantic segmentation, human pose estimation architectures are relatively robust to adversarial attacks with the single-step attacks being surprisingly ineffective. Our study show that the heatmap-based pose-estimation models fare better than their direct regression-based counterparts and that the systems which explicitly model anthropomorphic semantics of human body are significantly more robust. We find that the targeted attacks are more difficult to obtain than untargeted ones and some body-joints are easier to fool than the others. We present visualizations of universal perturbations to facilitate unprecedented insights into their workings on pose-estimation. Additionally, we show them to generalize well across different networks on both the datasets.
3D Human Pose Estimation under limited supervision using Metric Learning
Aug 14, 2019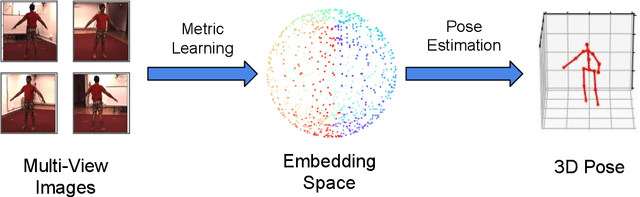
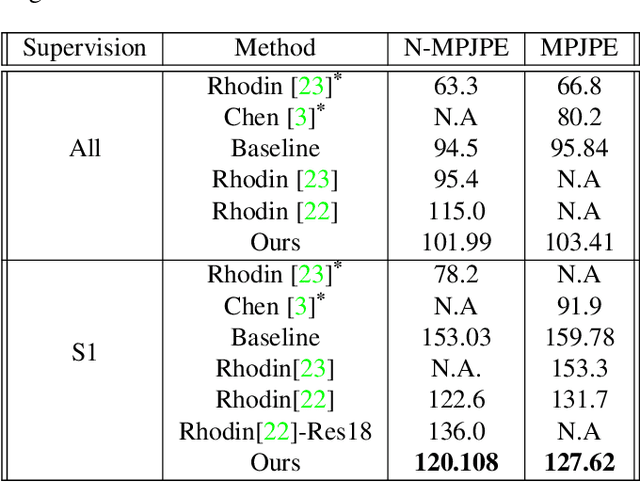

Estimating 3D human pose from monocular images demands large amounts of 3D pose and in-the-wild 2D pose annotated datasets which are costly and require sophisticated systems to acquire. In this regard, we propose a metric learning based approach to jointly learn a rich embedding and 3D pose regression from the embedding using multi-view synchronised videos of human motions and very limited 3D pose annotations. The inclusion of metric learning to the baseline pose estimation framework improves the performance by 21\% when 3D supervision is limited. In addition, we make use of a person-identity based adversarial loss as additional weak supervision to outperform state-of-the-art whilst using a much smaller network. Lastly, but importantly, we demonstrate the advantages of the learned embedding and establish view-invariant pose retrieval benchmarks on two popular, publicly available multi-view human pose datasets, Human 3.6M and MPI-INF-3DHP, to facilitate future research.
Monocular 3D Human Pose Estimation by Generation and Ordinal Ranking
Apr 02, 2019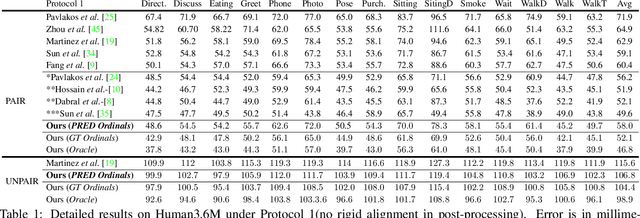
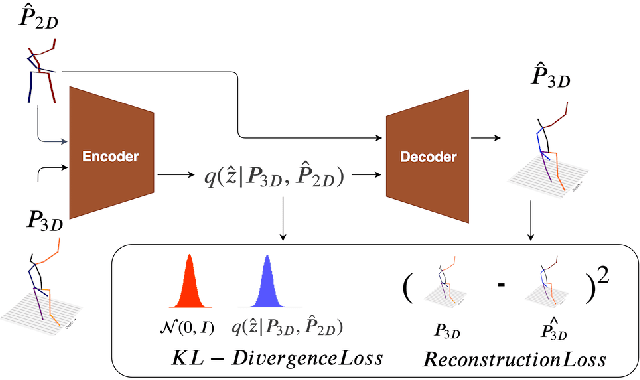
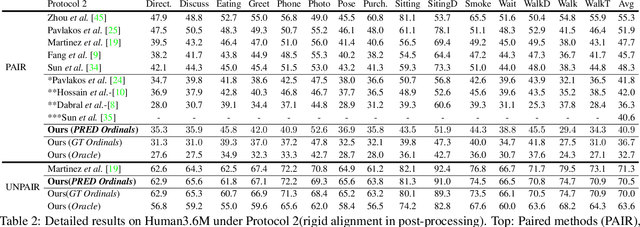
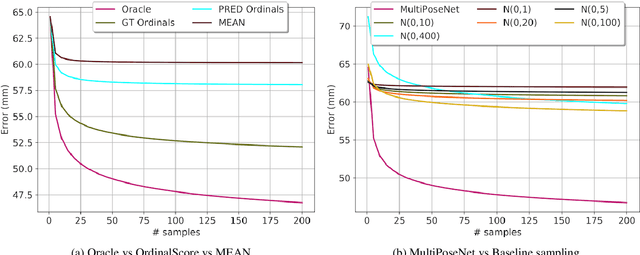
Monocular 3D Human Pose Estimation from static images is a challenging problem, due to the curse of dimensionality and the ill-posed nature of lifting 2D to 3D. In this paper, we propose a Deep Conditional Variational Autoencoder based model that synthesizes diverse 3D pose samples conditioned on the estimated 2D pose. Our experiments reveal that the CVAE generates significantly diverse 3D samples that are consistent with the 2D pose, thereby reducing the ambiguity in lifting from 2D-to-3D. We use two strategies for predicting the final 3D pose - (a) depth-ordering/ordinal relations to score and aggregate the final 3D pose, or OrdinalScore, and (b) with supervision from an Oracle. We report close to state of the art results on two benchmark datasets using OrdinalScore, and state-of-the-art results using the Oracle. We also show our pipeline gives competitive results without paired 3D supervision. We shall make the training and evaluation code available at https://github.com/ssfootball04/generative_pose.
Removal of Batch Effects using Generative Adversarial Networks
Jan 20, 2019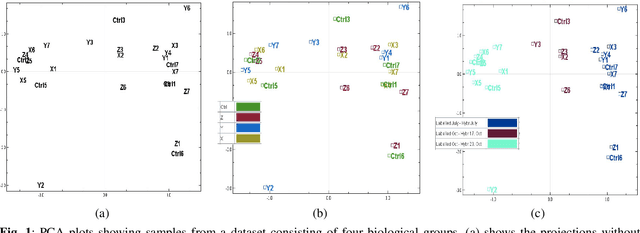
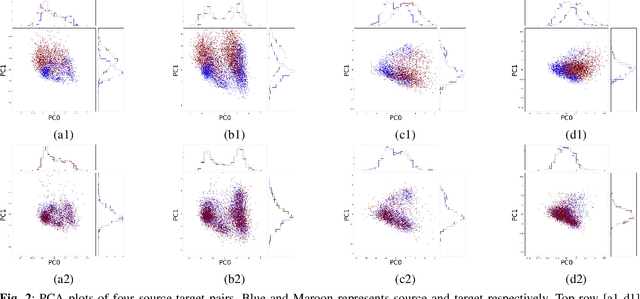
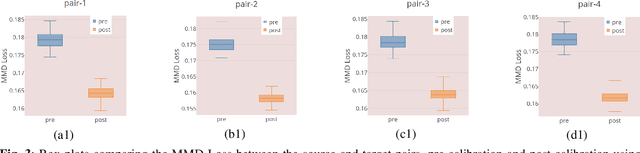
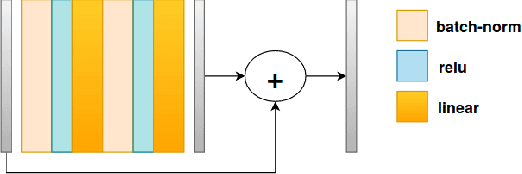
Many biological data analysis processes like Cytometry or Next Generation Sequencing (NGS) produce massive amounts of data which needs to be processed in batches for down-stream analysis. Such datasets are prone to technical variations due to difference in handling the batches possibly at different times, by different experimenters or under other different conditions. This adds variation to the batches coming from the same source sample. These variations are known as Batch Effects. It is possible that these variations and natural variations due to biology confound but such situations can be avoided by performing experiments in a carefully planned manner. Batch effects can hamper down-stream analysis and may also cause results to be inconclusive. Thus, it is essential to correct for these effects. Some recent methods propose deep learning based solution to solve this problem. We demonstrate that this can be solved using a novel Generative Adversarial Networks (GANs) based framework. The advantage of using this framework over other prior approaches is that here we do not require to choose a reproducing kernel and define its parameters.We demonstrate results of our framework on a Mass Cytometry dataset.
An Improved Learning Framework for Covariant Local Feature Detection
Nov 01, 2018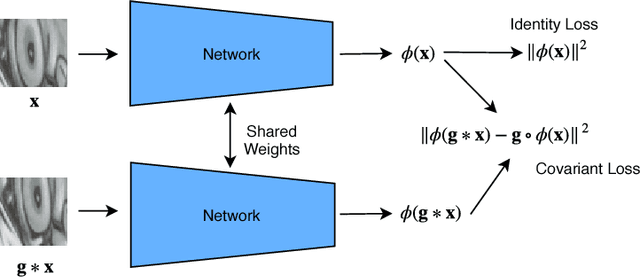
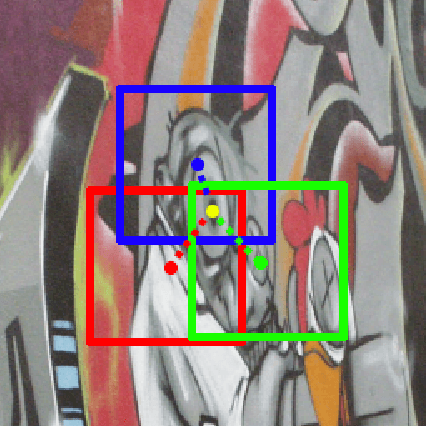
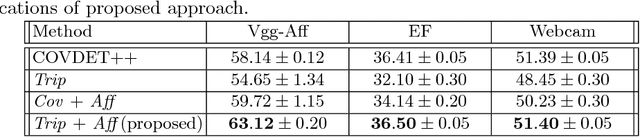

Learning feature detection has been largely an unexplored area when compared to handcrafted feature detection. Recent learning formulations use the covariant constraint in their loss function to learn covariant detectors. However, just learning from covariant constraint can lead to detection of unstable features. To impart further, stability detectors are trained to extract pre-determined features obtained by hand-crafted detectors. However, in the process they lose the ability to detect novel features. In an attempt to overcome the above limitations, we propose an improved scheme by incorporating covariant constraints in form of triplets with addition to an affine covariant constraint. We show that using these additional constraints one can learn to detect novel and stable features without using pre-determined features for training. Extensive experiments show our model achieves state-of-the-art performance in repeatability score on the well known datasets such as Vgg-Affine, EF, and Webcam.
* 15 pages
Learning 3D Human Pose from Structure and Motion
Jul 03, 2018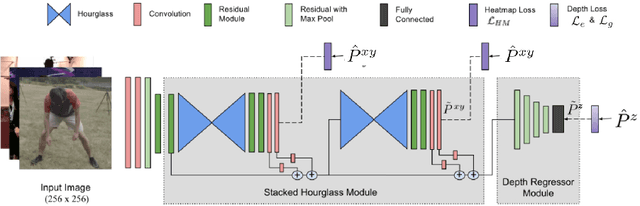
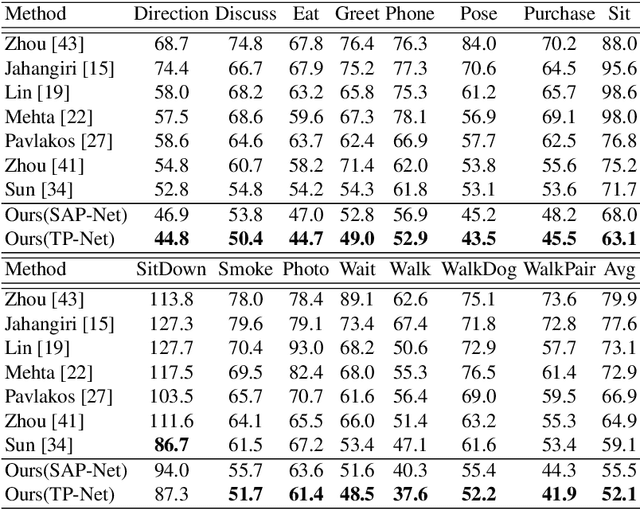
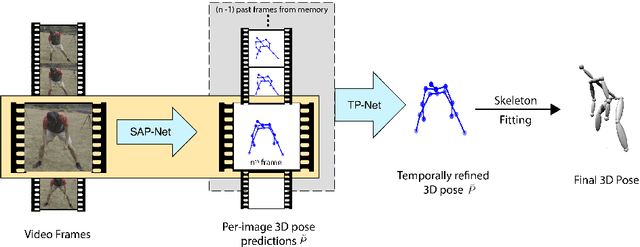
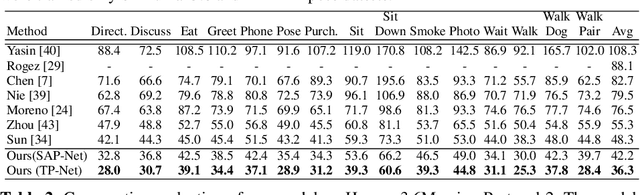
3D human pose estimation from a single image is a challenging problem, especially for in-the-wild settings due to the lack of 3D annotated data. We propose two anatomically inspired loss functions and use them with a weakly-supervised learning framework to jointly learn from large-scale in-the-wild 2D and indoor/synthetic 3D data. We also present a simple temporal network that exploits temporal and structural cues present in predicted pose sequences to temporally harmonize the pose estimations. We carefully analyze the proposed contributions through loss surface visualizations and sensitivity analysis to facilitate deeper understanding of their working mechanism. Our complete pipeline improves the state-of-the-art by 11.8% and 12% on Human3.6M and MPI-INF-3DHP, respectively, and runs at 30 FPS on a commodity graphics card.