 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular 3D Human Pose Estimation by Generation and Ordinal Ranking
Paper and Code
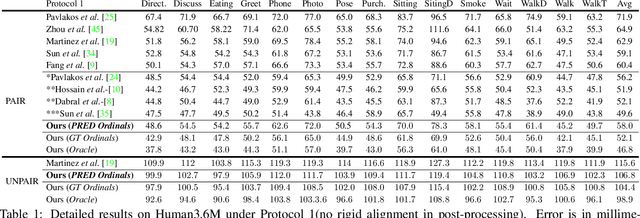
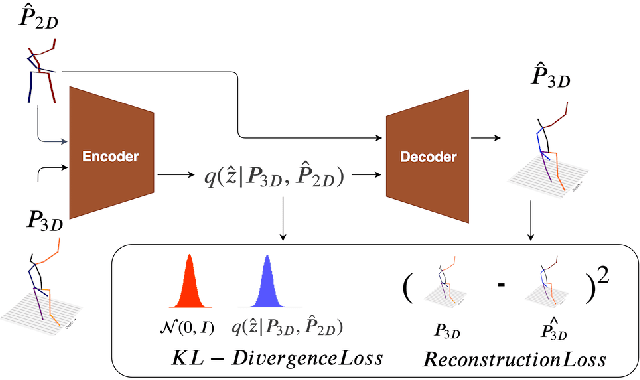
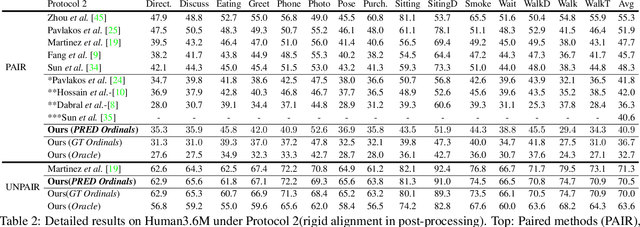
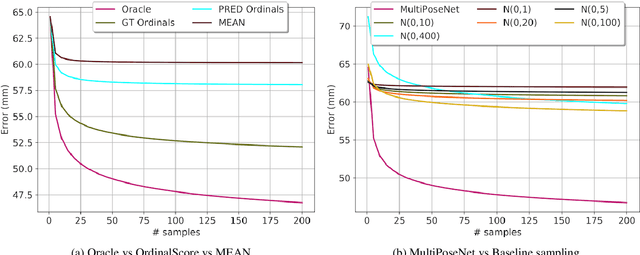
Monocular 3D Human Pose Estimation from static images is a challenging problem, due to the curse of dimensionality and the ill-posed nature of lifting 2D to 3D. In this paper, we propose a Deep Conditional Variational Autoencoder based model that synthesizes diverse 3D pose samples conditioned on the estimated 2D pose. Our experiments reveal that the CVAE generates significantly diverse 3D samples that are consistent with the 2D pose, thereby reducing the ambiguity in lifting from 2D-to-3D. We use two strategies for predicting the final 3D pose - (a) depth-ordering/ordinal relations to score and aggregate the final 3D pose, or OrdinalScore, and (b) with supervision from an Oracle. We report close to state of the art results on two benchmark datasets using OrdinalScore, and state-of-the-art results using the Oracle. We also show our pipeline gives competitive results without paired 3D supervision. We shall make the training and evaluation code available at https://github.com/ssfootball04/generative_pose.