 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElectioneering the Network: Dynamic Multi-Step Adversarial Attacks for Community Canvassing
Mar 19, 2024



The problem of online social network manipulation for community canvassing is of real concern in today's world. Motivated by the study of voter models, opinion and polarization dynamics on networks, we model community canvassing as a dynamic process over a network enabled via gradient-based attacks on GNNs. Existing attacks on GNNs are all single-step and do not account for the dynamic cascading nature of information diffusion in networks. We consider the realistic scenario where an adversary uses a GNN as a proxy to predict and manipulate voter preferences, especially uncertain voters. Gradient-based attacks on the GNN inform the adversary of strategic manipulations that can be made to proselytize targeted voters. In particular, we explore $\textit{minimum budget attacks for community canvassing}$ (MBACC). We show that the MBACC problem is NP-Hard and propose Dynamic Multi-Step Adversarial Community Canvassing (MAC) to address it. MAC makes dynamic local decisions based on the heuristic of low budget and high second-order influence to convert and perturb target voters. MAC is a dynamic multi-step attack that discovers low-budget and high-influence targets from which efficient cascading attacks can happen. We evaluate MAC against single-step baselines on the MBACC problem with multiple underlying networks and GNN models. Our experiments show the superiority of MAC which is able to discover efficient multi-hop attacks for adversarial community canvassing. Our code implementation and data is available at https://github.com/saurabhsharma1993/mac.
Learning Prototype Classifiers for Long-Tailed Recognition
Feb 01, 2023The problem of long-tailed recognition (LTR) has received attention in recent years due to the fundamental power-law distribution of objects in the real-world. Most recent works in LTR use softmax classifiers that have a tendency to correlate classifier norm with the amount of training data for a given class. On the other hand, Prototype classifiers do not suffer from this shortcoming and can deliver promising results simply using Nearest-Class-Mean (NCM), a special case where prototypes are empirical centroids. However, the potential of Prototype classifiers as an alternative to softmax in LTR is relatively underexplored. In this work, we propose Prototype classifiers, which jointly learn prototypes that minimize average cross-entropy loss based on probability scores from distances to prototypes. We theoretically analyze the properties of Euclidean distance based prototype classifiers that leads to stable gradient-based optimization which is robust to outliers. We further enhance Prototype classifiers by learning channel-dependent temperature parameters to enable independent distance scales along each channel. Our analysis shows that prototypes learned by Prototype classifiers are better separated than empirical centroids. Results on four long-tailed recognition benchmarks show that Prototype classifier outperforms or is comparable to the state-of-the-art methods.
Unposed: Unsupervised Pose Estimation based Product Image Recommendations
Jan 19, 2023



Product images are the most impressing medium of customer interaction on the product detail pages of e-commerce websites. Millions of products are onboarded on to webstore catalogues daily and maintaining a high quality bar for a product's set of images is a problem at scale. Grouping products by categories, clothing is a very high volume and high velocity category and thus deserves its own attention. Given the scale it is challenging to monitor the completeness of image set, which adequately details the product for the consumers, which in turn often leads to a poor customer experience and thus customer drop off. To supervise the quality and completeness of the images in the product pages for these product types and suggest improvements, we propose a Human Pose Detection based unsupervised method to scan the image set of a product for the missing ones. The unsupervised approach suggests a fair approach to sellers based on product and category irrespective of any biases. We first create a reference image set of popular products with wholesome imageset. Then we create clusters of images to label most desirable poses to form the classes for the reference set from these ideal products set. Further, for all test products we scan the images for all desired pose classes w.r.t. reference set poses, determine the missing ones and sort them in the order of potential impact. These missing poses can further be used by the sellers to add enriched product listing image. We gathered data from popular online webstore and surveyed ~200 products manually, a large fraction of which had at least 1 repeated image or missing variant, and sampled 3K products(~20K images) of which a significant proportion had scope for adding many image variants as compared to high rated products which had more than double image variants, indicating that our model can potentially be used on a large scale.
Long-Tailed Recognition Using Class-Balanced Experts
Apr 07, 2020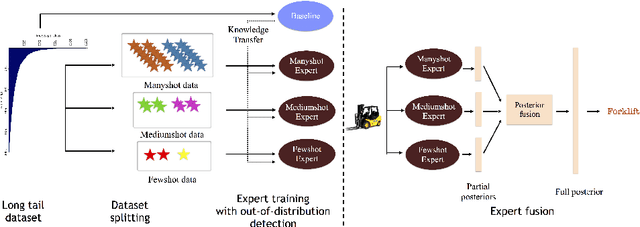
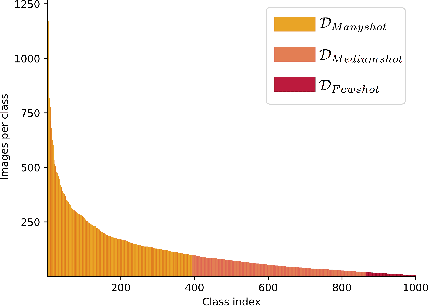

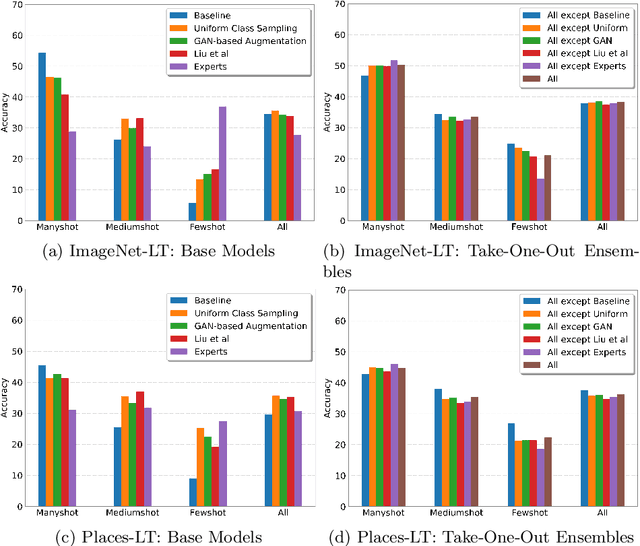
Classic deep learning methods achieve impressive results in image recognition over large-scale artificially-balanced datasets. However, real-world datasets exhibit highly class-imbalanced distributions. In this work we address the problem of long tail recognition wherein the training set is highly imbalanced and the test set is kept balanced. The key challenges faced by any long tail recognition technique are relative imbalance amongst the classes and data scarcity or unseen concepts for mediumshot or fewshot classes. Existing techniques rely on data-resampling, cost sensitive learning, online hard example mining, reshaping the loss objective and complex memory based models to address this problem. We instead propose an ensemble of experts technique that decomposes the imbalanced problem into multiple balanced classification problems which are more tractable. Our ensemble of experts reaches close to state-of-the-art results and an extended ensemble establishes new state-of-the-art on two benchmarks for long tail recognition. We conduct numerous experiments to analyse the performance of the ensemble, and show that in modern datasets relative imbalance is a harder problem than data scarcity.
Monocular 3D Human Pose Estimation by Generation and Ordinal Ranking
Apr 02, 2019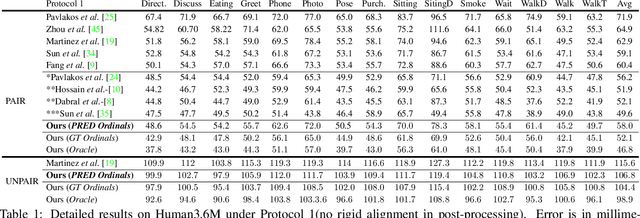
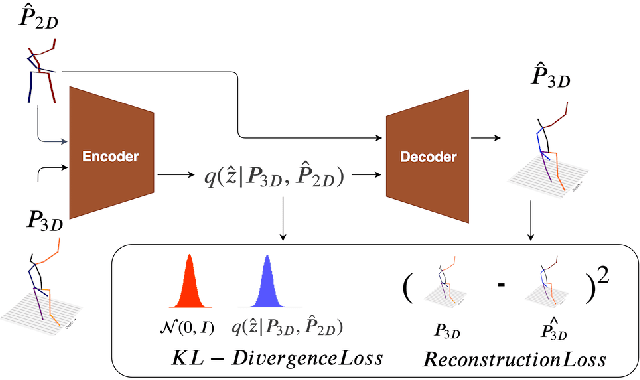
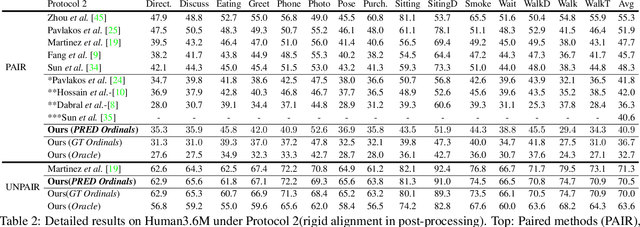
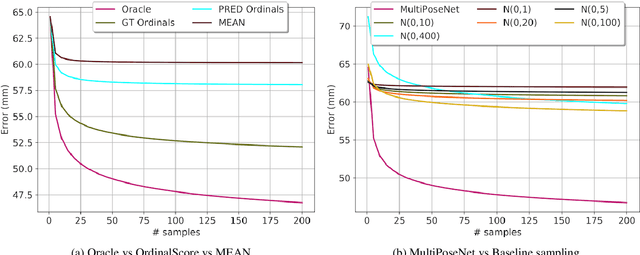
Monocular 3D Human Pose Estimation from static images is a challenging problem, due to the curse of dimensionality and the ill-posed nature of lifting 2D to 3D. In this paper, we propose a Deep Conditional Variational Autoencoder based model that synthesizes diverse 3D pose samples conditioned on the estimated 2D pose. Our experiments reveal that the CVAE generates significantly diverse 3D samples that are consistent with the 2D pose, thereby reducing the ambiguity in lifting from 2D-to-3D. We use two strategies for predicting the final 3D pose - (a) depth-ordering/ordinal relations to score and aggregate the final 3D pose, or OrdinalScore, and (b) with supervision from an Oracle. We report close to state of the art results on two benchmark datasets using OrdinalScore, and state-of-the-art results using the Oracle. We also show our pipeline gives competitive results without paired 3D supervision. We shall make the training and evaluation code available at https://github.com/ssfootball04/generative_pose.
f-VAEGAN-D2: A Feature Generating Framework for Any-Shot Learning
Mar 25, 2019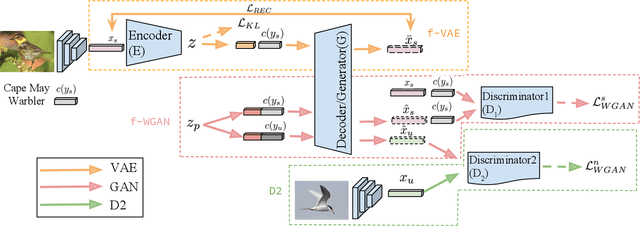
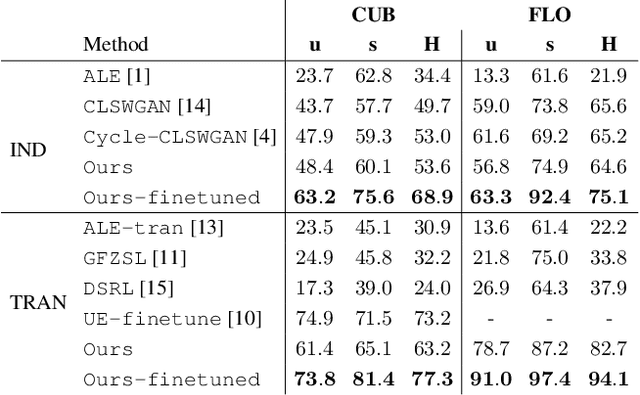
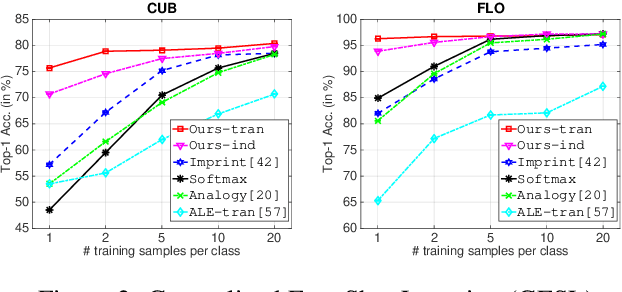
When labeled training data is scarce, a promising data augmentation approach is to generate visual features of unknown classes using their attributes. To learn the class conditional distribution of CNN features, these models rely on pairs of image features and class attributes. Hence, they can not make use of the abundance of unlabeled data samples. In this paper, we tackle any-shot learning problems i.e. zero-shot and few-shot, in a unified feature generating framework that operates in both inductive and transductive learning settings. We develop a conditional generative model that combines the strength of VAE and GANs and in addition, via an unconditional discriminator, learns the marginal feature distribution of unlabeled images. We empirically show that our model learns highly discriminative CNN features for five datasets, i.e. CUB, SUN, AWA and ImageNet, and establish a new state-of-the-art in any-shot learning, i.e. inductive and transductive (generalized) zero- and few-shot learning settings. We also demonstrate that our learned features are interpretable: we visualize them by inverting them back to the pixel space and we explain them by generating textual arguments of why they are associated with a certain label.
Pre-processing of Domain Ontology Graph Generation System in Punjabi
Nov 21, 2014



This paper describes pre-processing phase of ontology graph generation system from Punjabi text documents of different domains. This research paper focuses on pre-processing of Punjabi text documents. Pre-processing is structured representation of the input text. Pre-processing of ontology graph generation includes allowing input restrictions to the text, removal of special symbols and punctuation marks, removal of duplicate terms, removal of stop words, extract terms by matching input terms with dictionary and gazetteer lists terms.
* 6 pages, 17 figures, 1 table, "Published with International Journal of Engineering Trends and Technology (IJETT)"