 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthForge: Synthesizing High-Quality Face Dataset with Controllable 3D Generative Models
Jun 12, 2024



Recent advancements in generative models have unlocked the capabilities to render photo-realistic data in a controllable fashion. Trained on the real data, these generative models are capable of producing realistic samples with minimal to no domain gap, as compared to the traditional graphics rendering. However, using the data generated using such models for training downstream tasks remains under-explored, mainly due to the lack of 3D consistent annotations. Moreover, controllable generative models are learned from massive data and their latent space is often too vast to obtain meaningful sample distributions for downstream task with limited generation. To overcome these challenges, we extract 3D consistent annotations from an existing controllable generative model, making the data useful for downstream tasks. Our experiments show competitive performance against state-of-the-art models using only generated synthetic data, demonstrating potential for solving downstream tasks. Project page: https://synth-forge.github.io
VL4Pose: Active Learning Through Out-Of-Distribution Detection For Pose Estimation
Oct 12, 2022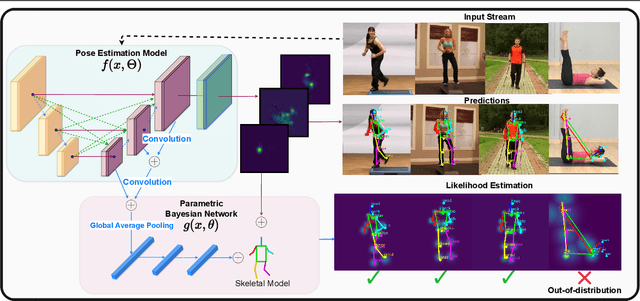
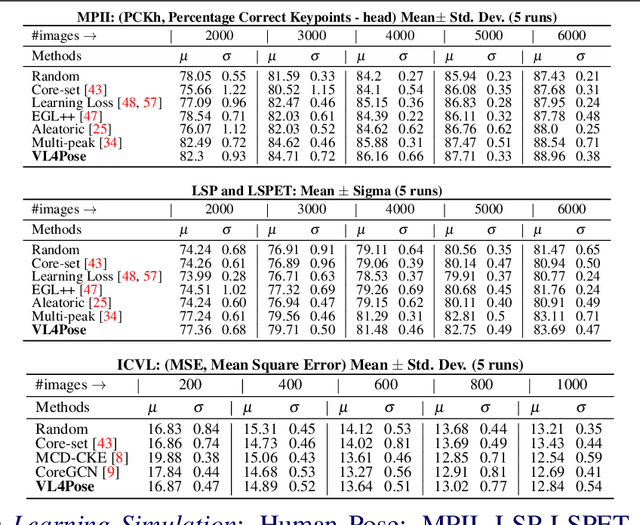

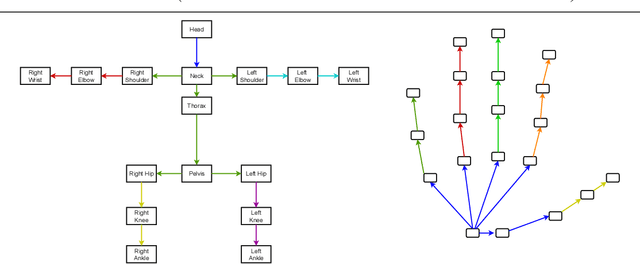
Advances in computing have enabled widespread access to pose estimation, creating new sources of data streams. Unlike mock set-ups for data collection, tapping into these data streams through on-device active learning allows us to directly sample from the real world to improve the spread of the training distribution. However, on-device computing power is limited, implying that any candidate active learning algorithm should have a low compute footprint while also being reliable. Although multiple algorithms cater to pose estimation, they either use extensive compute to power state-of-the-art results or are not competitive in low-resource settings. We address this limitation with VL4Pose (Visual Likelihood For Pose Estimation), a first principles approach for active learning through out-of-distribution detection. We begin with a simple premise: pose estimators often predict incoherent poses for out-of-distribution samples. Hence, can we identify a distribution of poses the model has been trained on, to identify incoherent poses the model is unsure of? Our solution involves modelling the pose through a simple parametric Bayesian network trained via maximum likelihood estimation. Therefore, poses incurring a low likelihood within our framework are out-of-distribution samples making them suitable candidates for annotation. We also observe two useful side-outcomes: VL4Pose in-principle yields better uncertainty estimates by unifying joint and pose level ambiguity, as well as the unintentional but welcome ability of VL4Pose to perform pose refinement in limited scenarios. We perform qualitative and quantitative experiments on three datasets: MPII, LSP and ICVL, spanning human and hand pose estimation. Finally, we note that VL4Pose is simple, computationally inexpensive and competitive, making it suitable for challenging tasks such as on-device active learning.
CLUDA : Contrastive Learning in Unsupervised Domain Adaptation for Semantic Segmentation
Aug 27, 2022
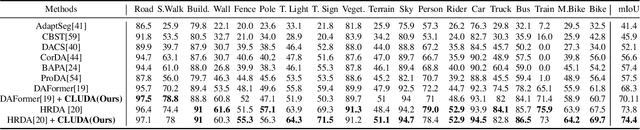
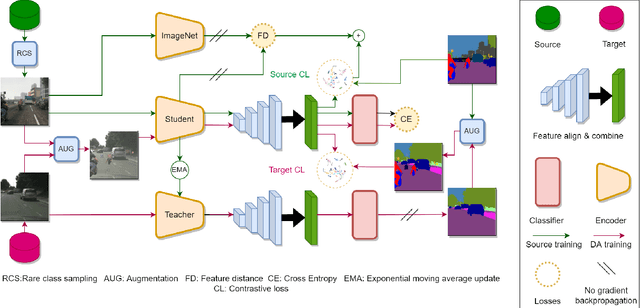
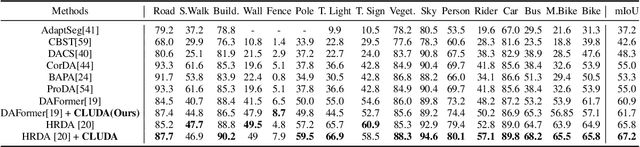
In this work, we propose CLUDA, a simple, yet novel method for performing unsupervised domain adaptation (UDA) for semantic segmentation by incorporating contrastive losses into a student-teacher learning paradigm, that makes use of pseudo-labels generated from the target domain by the teacher network. More specifically, we extract a multi-level fused-feature map from the encoder, and apply contrastive loss across different classes and different domains, via source-target mixing of images. We consistently improve performance on various feature encoder architectures and for different domain adaptation datasets in semantic segmentation. Furthermore, we introduce a learned-weighted contrastive loss to improve upon on a state-of-the-art multi-resolution training approach in UDA. We produce state-of-the-art results on GTA $\rightarrow$ Cityscapes (74.4 mIOU, +0.6) and Synthia $\rightarrow$ Cityscapes (67.2 mIOU, +1.4) datasets. CLUDA effectively demonstrates contrastive learning in UDA as a generic method, which can be easily integrated into any existing UDA for semantic segmentation tasks. Please refer to the supplementary material for the details on implementation.
A Mathematical Analysis of Learning Loss for Active Learning in Regression
Apr 19, 2021

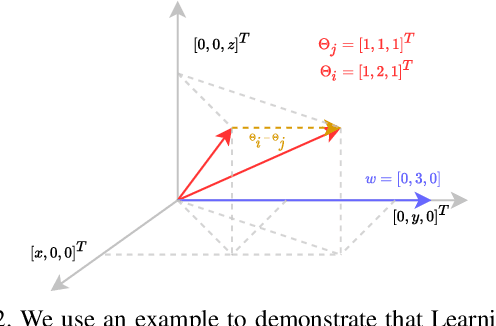

Active learning continues to remain significant in the industry since it is data efficient. Not only is it cost effective on a constrained budget, continuous refinement of the model allows for early detection and resolution of failure scenarios during the model development stage. Identifying and fixing failures with the model is crucial as industrial applications demand that the underlying model performs accurately in all foreseeable use cases. One popular state-of-the-art technique that specializes in continuously refining the model via failure identification is Learning Loss. Although simple and elegant, this approach is empirically motivated. Our paper develops a foundation for Learning Loss which enables us to propose a novel modification we call LearningLoss++. We show that gradients are crucial in interpreting how Learning Loss works, with rigorous analysis and comparison of the gradients between Learning Loss and LearningLoss++. We also propose a convolutional architecture that combines features at different scales to predict the loss. We validate LearningLoss++ for regression on the task of human pose estimation (using MPII and LSP datasets), as done in Learning Loss. We show that LearningLoss++ outperforms in identifying scenarios where the model is likely to perform poorly, which on model refinement translates into reliable performance in the open world.
ProtoGAN: Towards Few Shot Learning for Action Recognition
Sep 17, 2019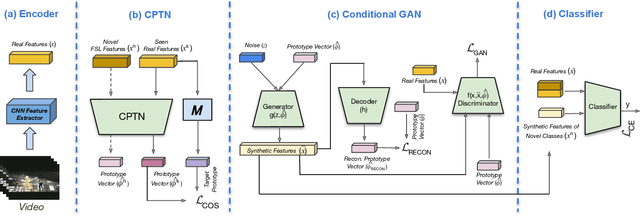
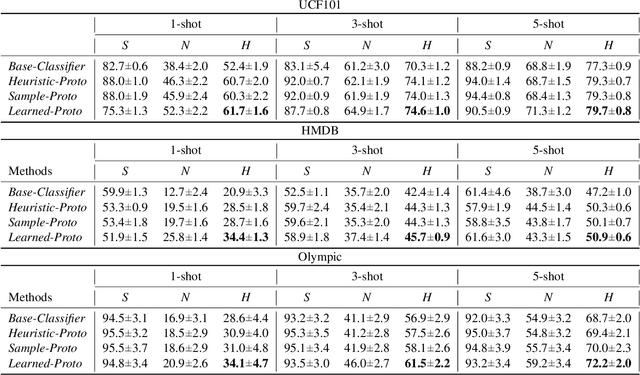
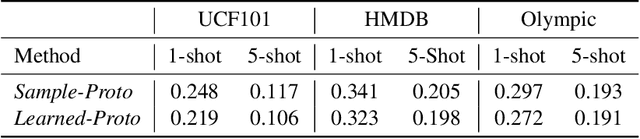
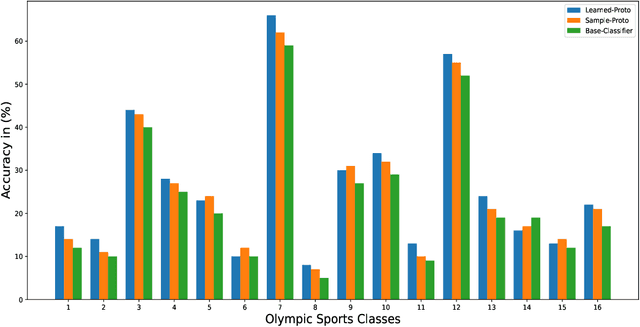
Few-shot learning (FSL) for action recognition is a challenging task of recognizing novel action categories which are represented by few instances in the training data. In a more generalized FSL setting (G-FSL), both seen as well as novel action categories need to be recognized. Conventional classifiers suffer due to inadequate data in FSL setting and inherent bias towards seen action categories in G-FSL setting. In this paper, we address this problem by proposing a novel ProtoGAN framework which synthesizes additional examples for novel categories by conditioning a conditional generative adversarial network with class prototype vectors. These class prototype vectors are learnt using a Class Prototype Transfer Network (CPTN) from examples of seen categories. Our synthesized examples for a novel class are semantically similar to real examples belonging to that class and is used to train a model exhibiting better generalization towards novel classes. We support our claim by performing extensive experiments on three datasets: UCF101, HMDB51 and Olympic-Sports. To the best of our knowledge, we are the first to report the results for G-FSL and provide a strong benchmark for future research. We also outperform the state-of-the-art method in FSL for all the aforementioned datasets.
Out-of-Distribution Detection for Generalized Zero-Shot Action Recognition
May 06, 2019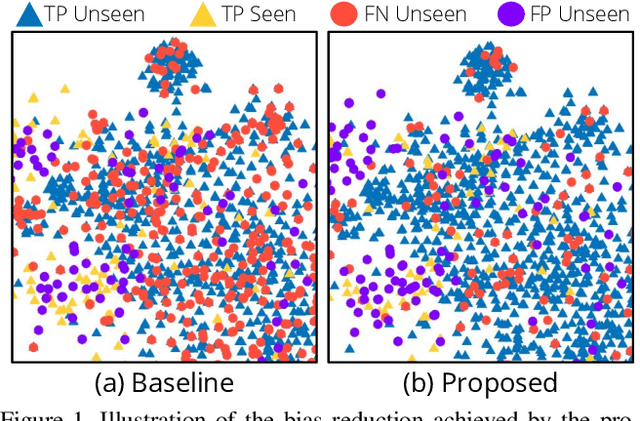
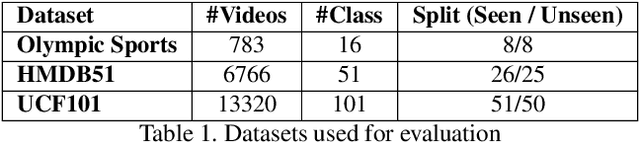
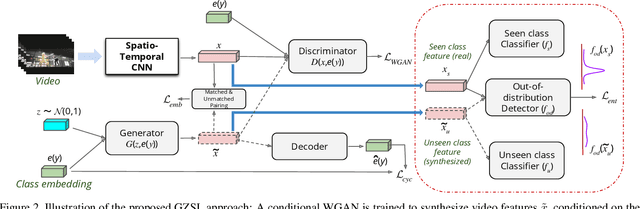
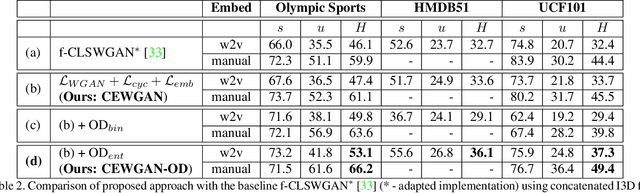
Generalized zero-shot action recognition is a challenging problem, where the task is to recognize new action categories that are unavailable during the training stage, in addition to the seen action categories. Existing approaches suffer from the inherent bias of the learned classifier towards the seen action categories. As a consequence, unseen category samples are incorrectly classified as belonging to one of the seen action categories. In this paper, we set out to tackle this issue by arguing for a separate treatment of seen and unseen action categories in generalized zero-shot action recognition. We introduce an out-of-distribution detector that determines whether the video features belong to a seen or unseen action category. To train our out-of-distribution detector, video features for unseen action categories are synthesized using generative adversarial networks trained on seen action category features. To the best of our knowledge, we are the first to propose an out-of-distribution detector based GZSL framework for action recognition in videos. Experiments are performed on three action recognition datasets: Olympic Sports, HMDB51 and UCF101. For generalized zero-shot action recognition, our proposed approach outperforms the baseline (f-CLSWGAN) with absolute gains (in classification accuracy) of 7.0%, 3.4%, and 4.9%, respectively, on these datasets.
An Improved Learning Framework for Covariant Local Feature Detection
Nov 01, 2018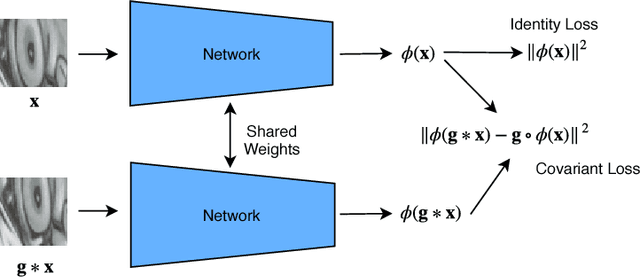
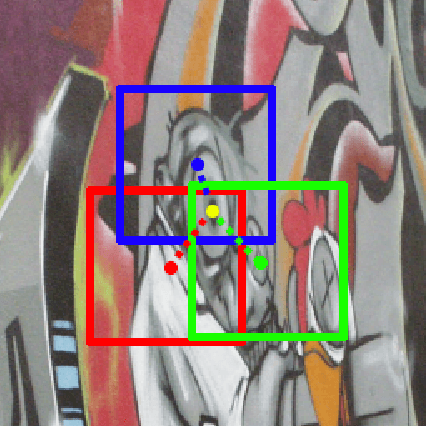
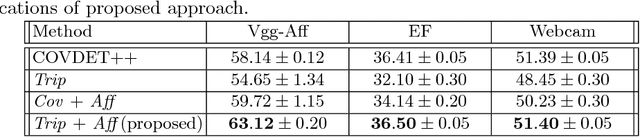

Learning feature detection has been largely an unexplored area when compared to handcrafted feature detection. Recent learning formulations use the covariant constraint in their loss function to learn covariant detectors. However, just learning from covariant constraint can lead to detection of unstable features. To impart further, stability detectors are trained to extract pre-determined features obtained by hand-crafted detectors. However, in the process they lose the ability to detect novel features. In an attempt to overcome the above limitations, we propose an improved scheme by incorporating covariant constraints in form of triplets with addition to an affine covariant constraint. We show that using these additional constraints one can learn to detect novel and stable features without using pre-determined features for training. Extensive experiments show our model achieves state-of-the-art performance in repeatability score on the well known datasets such as Vgg-Affine, EF, and Webcam.
* 15 pages
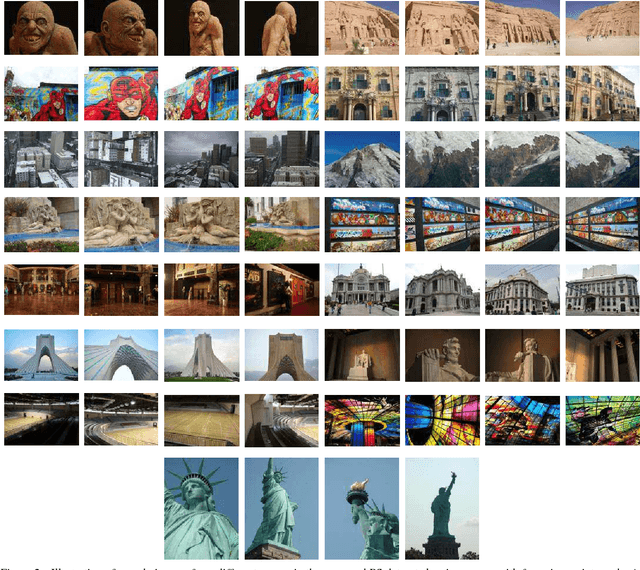
A Large Dataset for Improving Patch Matching
Apr 17, 2018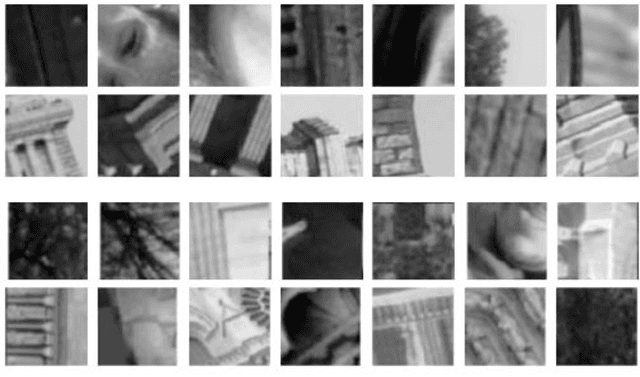
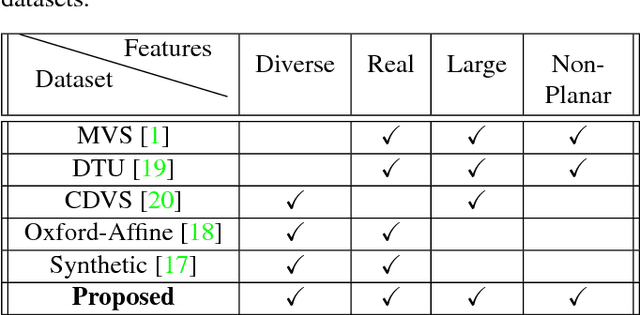

We propose a new dataset for learning local image descriptors which can be used for significantly improved patch matching. Our proposed dataset consists of an order of magnitude more number of scenes, images, and positive and negative correspondences compared to the currently available Multi-View Stereo (MVS) dataset from Brown et al. The new dataset also has better coverage of the overall viewpoint, scale, and lighting changes in comparison to the MVS dataset. Our dataset also provides supplementary information like RGB patches with scale and rotations values, and intrinsic and extrinsic camera parameters which as shown later can be used to customize training data as per application. We train an existing state-of-the-art model on our dataset and evaluate on publicly available benchmarks such as HPatches dataset and Strecha et al.\cite{strecha} to quantify the image descriptor performance. Experimental evaluations show that the descriptors trained using our proposed dataset outperform the current state-of-the-art descriptors trained on MVS by 8%, 4% and 10% on matching, verification and retrieval tasks respectively on the HPatches dataset. Similarly on the Strecha dataset, we see an improvement of 3-5% for the matching task in non-planar scenes.
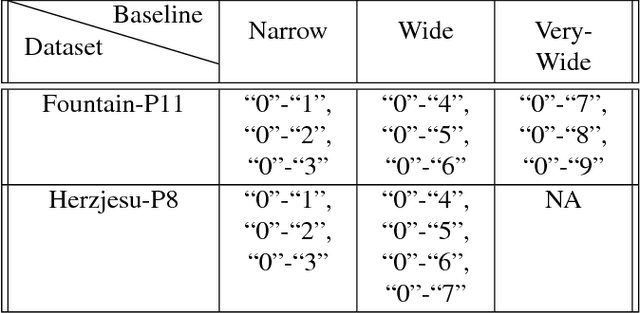
Improved Descriptors for Patch Matching and Reconstruction
Aug 27, 2017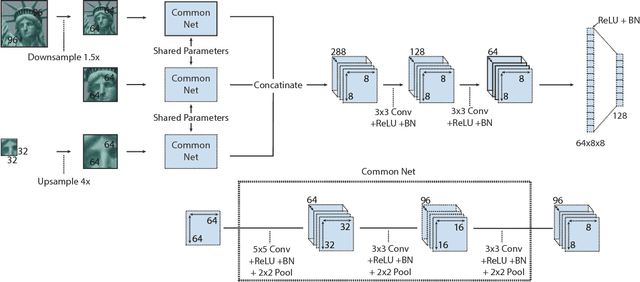
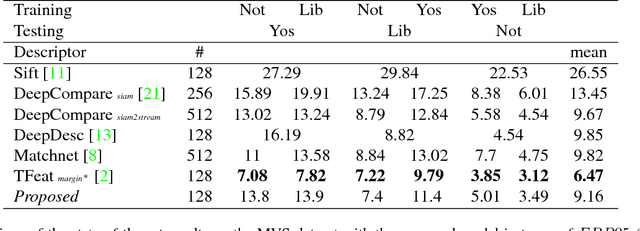
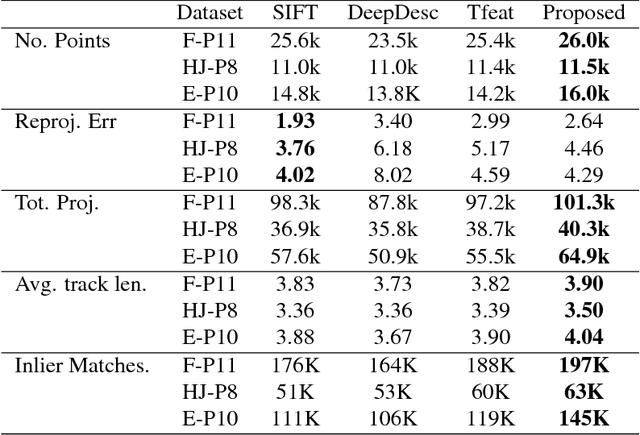
We propose a convolutional neural network (ConvNet) based approach for learning local image descriptors which can be used for significantly improved patch matching and 3D reconstructions. A multi-resolution ConvNet is used for learning keypoint descriptors. We also propose a new dataset consisting of an order of magnitude more number of scenes, images, and positive and negative correspondences compared to the currently available Multi-View Stereo (MVS) [18] dataset. The new dataset also has better coverage of the overall viewpoint, scale, and lighting changes in comparison to the MVS dataset. We evaluate our approach on publicly available datasets, such as Oxford Affine Covariant Regions Dataset (ACRD) [12], MVS [18], Synthetic [6] and Strecha [15] datasets to quantify the image descriptor performance. Scenes from the Oxford ACRD, MVS and Synthetic datasets are used for evaluating the patch matching performance of the learnt descriptors while the Strecha dataset is used to evaluate the 3D reconstruction task. Experiments show that the proposed descriptor outperforms the current state-of-the-art descriptors in both the evaluation tasks.