 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVL4Pose: Active Learning Through Out-Of-Distribution Detection For Pose Estimation
Oct 12, 2022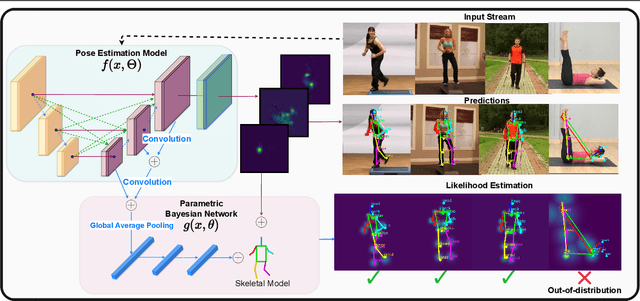
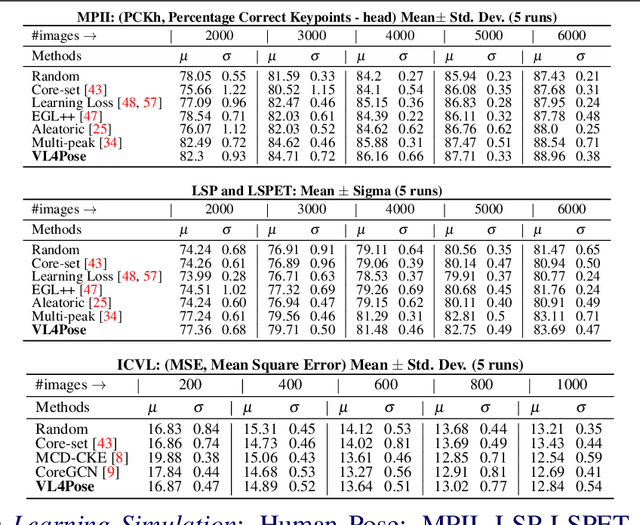

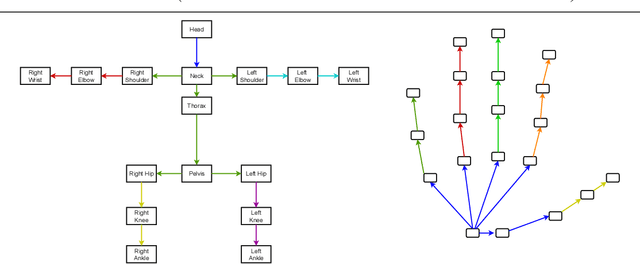
Advances in computing have enabled widespread access to pose estimation, creating new sources of data streams. Unlike mock set-ups for data collection, tapping into these data streams through on-device active learning allows us to directly sample from the real world to improve the spread of the training distribution. However, on-device computing power is limited, implying that any candidate active learning algorithm should have a low compute footprint while also being reliable. Although multiple algorithms cater to pose estimation, they either use extensive compute to power state-of-the-art results or are not competitive in low-resource settings. We address this limitation with VL4Pose (Visual Likelihood For Pose Estimation), a first principles approach for active learning through out-of-distribution detection. We begin with a simple premise: pose estimators often predict incoherent poses for out-of-distribution samples. Hence, can we identify a distribution of poses the model has been trained on, to identify incoherent poses the model is unsure of? Our solution involves modelling the pose through a simple parametric Bayesian network trained via maximum likelihood estimation. Therefore, poses incurring a low likelihood within our framework are out-of-distribution samples making them suitable candidates for annotation. We also observe two useful side-outcomes: VL4Pose in-principle yields better uncertainty estimates by unifying joint and pose level ambiguity, as well as the unintentional but welcome ability of VL4Pose to perform pose refinement in limited scenarios. We perform qualitative and quantitative experiments on three datasets: MPII, LSP and ICVL, spanning human and hand pose estimation. Finally, we note that VL4Pose is simple, computationally inexpensive and competitive, making it suitable for challenging tasks such as on-device active learning.
Transformer-based Flood Scene Segmentation for Developing Countries
Oct 09, 2022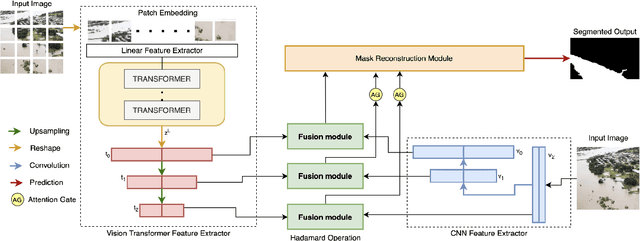
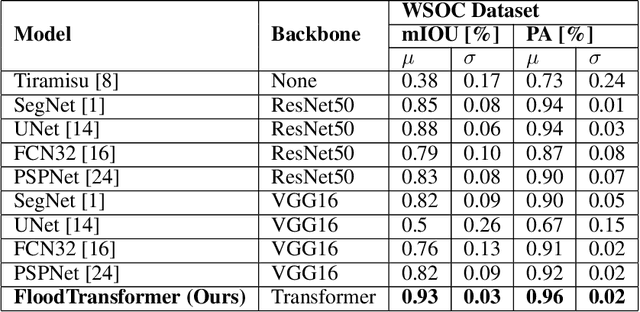


Floods are large-scale natural disasters that often induce a massive number of deaths, extensive material damage, and economic turmoil. The effects are more extensive and longer-lasting in high-population and low-resource developing countries. Early Warning Systems (EWS) constantly assess water levels and other factors to forecast floods, to help minimize damage. Post-disaster, disaster response teams undertake a Post Disaster Needs Assessment (PDSA) to assess structural damage and determine optimal strategies to respond to highly affected neighbourhoods. However, even today in developing countries, EWS and PDSA analysis of large volumes of image and video data is largely a manual process undertaken by first responders and volunteers. We propose FloodTransformer, which to the best of our knowledge, is the first visual transformer-based model to detect and segment flooded areas from aerial images at disaster sites. We also propose a custom metric, Flood Capacity (FC) to measure the spatial extent of water coverage and quantify the segmented flooded area for EWS and PDSA analyses. We use the SWOC Flood segmentation dataset and achieve 0.93 mIoU, outperforming all other methods. We further show the robustness of this approach by validating across unseen flood images from other flood data sources.