 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotionMap: Representing Multimodality in Human Pose Forecasting
Dec 25, 2024Human pose forecasting is inherently multimodal since multiple futures exist for an observed pose sequence. However, evaluating multimodality is challenging since the task is ill-posed. Therefore, we first propose an alternative paradigm to make the task well-posed. Next, while state-of-the-art methods predict multimodality, this requires oversampling a large volume of predictions. This raises key questions: (1) Can we capture multimodality by efficiently sampling a smaller number of predictions? (2) Subsequently, which of the predicted futures is more likely for an observed pose sequence? We address these questions with MotionMap, a simple yet effective heatmap based representation for multimodality. We extend heatmaps to represent a spatial distribution over the space of all possible motions, where different local maxima correspond to different forecasts for a given observation. MotionMap can capture a variable number of modes per observation and provide confidence measures for different modes. Further, MotionMap allows us to introduce the notion of uncertainty and controllability over the forecasted pose sequence. Finally, MotionMap captures rare modes that are non-trivial to evaluate yet critical for safety. We support our claims through multiple qualitative and quantitative experiments using popular 3D human pose datasets: Human3.6M and AMASS, highlighting the strengths and limitations of our proposed method. Project Page: https://www.epfl.ch/labs/vita/research/prediction/motionmap/
TIC-TAC: A Framework To Learn And Evaluate Your Covariance
Oct 29, 2023



We study the problem of unsupervised heteroscedastic covariance estimation, where the goal is to learn the multivariate target distribution $\mathcal{N}(y, \Sigma_y | x )$ given an observation $x$. This problem is particularly challenging as $\Sigma_{y}$ varies for different samples (heteroscedastic) and no annotation for the covariance is available (unsupervised). Typically, state-of-the-art methods predict the mean $f_{\theta}(x)$ and covariance $\textrm{Cov}(f_{\theta}(x))$ of the target distribution through two neural networks trained using the negative log-likelihood. This raises two questions: (1) Does the predicted covariance truly capture the randomness of the predicted mean? (2) In the absence of ground-truth annotation, how can we quantify the performance of covariance estimation? We address (1) by deriving TIC: Taylor Induced Covariance, which captures the randomness of the multivariate $f_{\theta}(x)$ by incorporating its gradient and curvature around $x$ through the second order Taylor polynomial. Furthermore, we tackle (2) by introducing TAC: Task Agnostic Correlations, a metric which leverages conditioning of the normal distribution to evaluate the covariance. We verify the effectiveness of TIC through multiple experiments spanning synthetic (univariate, multivariate) and real-world datasets (UCI Regression, LSP, and MPII Human Pose Estimation). Our experiments show that TIC outperforms state-of-the-art in accurately learning the covariance, as quantified through TAC.
VL4Pose: Active Learning Through Out-Of-Distribution Detection For Pose Estimation
Oct 12, 2022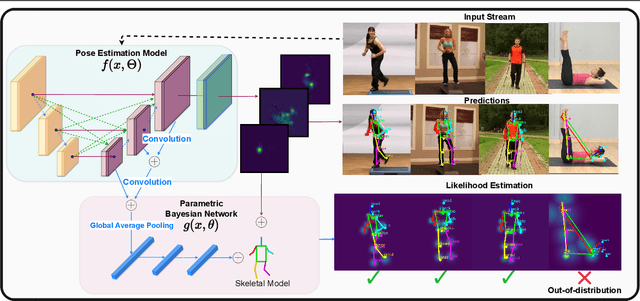
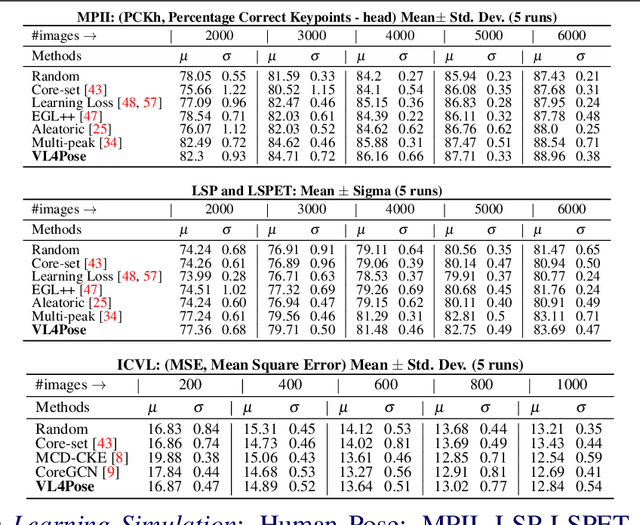

Advances in computing have enabled widespread access to pose estimation, creating new sources of data streams. Unlike mock set-ups for data collection, tapping into these data streams through on-device active learning allows us to directly sample from the real world to improve the spread of the training distribution. However, on-device computing power is limited, implying that any candidate active learning algorithm should have a low compute footprint while also being reliable. Although multiple algorithms cater to pose estimation, they either use extensive compute to power state-of-the-art results or are not competitive in low-resource settings. We address this limitation with VL4Pose (Visual Likelihood For Pose Estimation), a first principles approach for active learning through out-of-distribution detection. We begin with a simple premise: pose estimators often predict incoherent poses for out-of-distribution samples. Hence, can we identify a distribution of poses the model has been trained on, to identify incoherent poses the model is unsure of? Our solution involves modelling the pose through a simple parametric Bayesian network trained via maximum likelihood estimation. Therefore, poses incurring a low likelihood within our framework are out-of-distribution samples making them suitable candidates for annotation. We also observe two useful side-outcomes: VL4Pose in-principle yields better uncertainty estimates by unifying joint and pose level ambiguity, as well as the unintentional but welcome ability of VL4Pose to perform pose refinement in limited scenarios. We perform qualitative and quantitative experiments on three datasets: MPII, LSP and ICVL, spanning human and hand pose estimation. Finally, we note that VL4Pose is simple, computationally inexpensive and competitive, making it suitable for challenging tasks such as on-device active learning.
EGL++: Extending Expected Gradient Length to Active Learning for Human Pose Estimation
Apr 19, 2021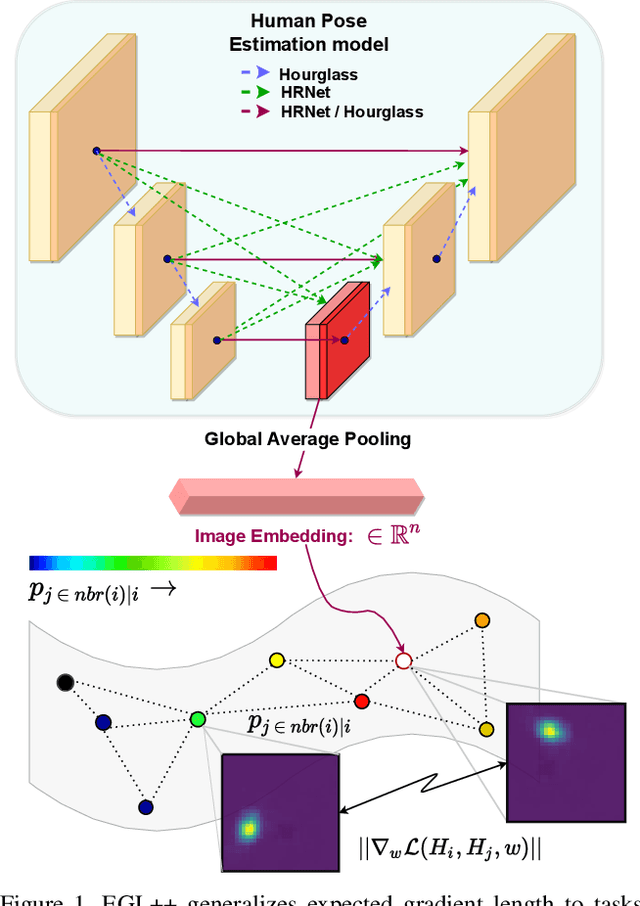
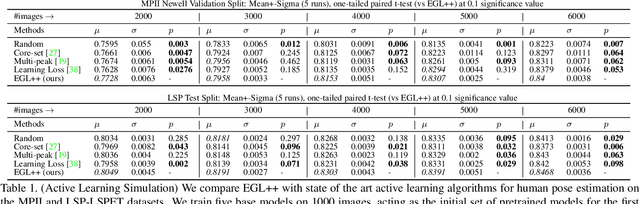
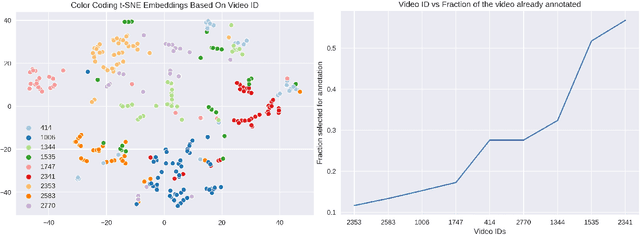

State of the art human pose estimation models continue to rely on large quantities of labelled data for robust performance. Since labelling budget is often constrained, active learning algorithms are important in retaining the overall performance of the model at a lower cost. Although active learning has been well studied in literature, few techniques are reported for human pose estimation. In this paper, we theoretically derive expected gradient length for regression, and propose EGL++, a novel heuristic algorithm that extends expected gradient length to tasks where discrete labels are not available. We achieve this by computing low dimensional representations of the original images which are then used to form a neighborhood graph. We use this graph to: 1) Obtain a set of neighbors for a given sample, with each neighbor iteratively assumed to represent the ground truth for gradient calculation 2) Quantify the probability of each sample being a neighbor in the above set, facilitating the expected gradient step. Such an approach allows us to provide an approximate solution to the otherwise intractable task of integrating over the continuous output domain. To validate EGL++, we use the same datasets (Leeds Sports Pose, MPII) and experimental design as suggested by previous literature, achieving competitive results in comparison to these methods.
A Mathematical Analysis of Learning Loss for Active Learning in Regression
Apr 19, 2021

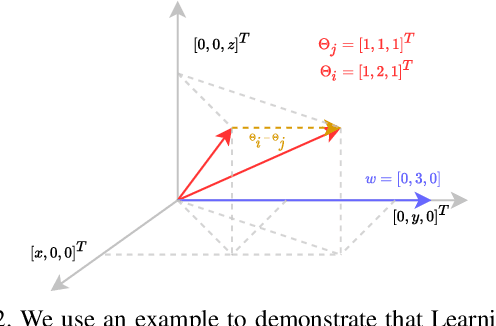

Active learning continues to remain significant in the industry since it is data efficient. Not only is it cost effective on a constrained budget, continuous refinement of the model allows for early detection and resolution of failure scenarios during the model development stage. Identifying and fixing failures with the model is crucial as industrial applications demand that the underlying model performs accurately in all foreseeable use cases. One popular state-of-the-art technique that specializes in continuously refining the model via failure identification is Learning Loss. Although simple and elegant, this approach is empirically motivated. Our paper develops a foundation for Learning Loss which enables us to propose a novel modification we call LearningLoss++. We show that gradients are crucial in interpreting how Learning Loss works, with rigorous analysis and comparison of the gradients between Learning Loss and LearningLoss++. We also propose a convolutional architecture that combines features at different scales to predict the loss. We validate LearningLoss++ for regression on the task of human pose estimation (using MPII and LSP datasets), as done in Learning Loss. We show that LearningLoss++ outperforms in identifying scenarios where the model is likely to perform poorly, which on model refinement translates into reliable performance in the open world.
LEt-SNE: A Hybrid Approach To Data Embedding and Visualization of Hyperspectral Imagery
Oct 19, 2019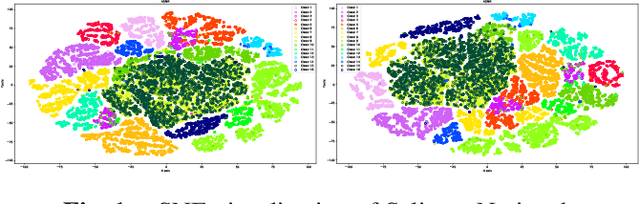

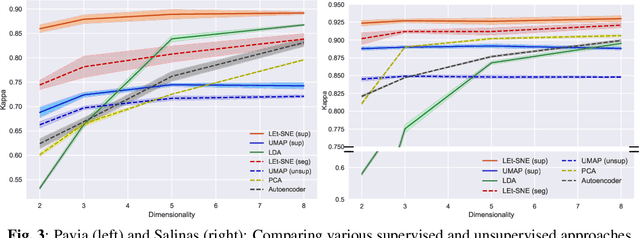
Hyperspectral Imagery (and Remote Sensing in general) captured from UAVs or satellites are highly voluminous in nature due to the large spatial extent and wavelengths captured by them. Since analyzing these images requires a huge amount of computational time and power, various dimensionality reduction techniques have been used for feature reduction. Some popular techniques among these falter when applied to Hyperspectral Imagery due to the famed curse of dimensionality. In this paper, we propose a novel approach, LEt-SNE, which combines graph based algorithms like t-SNE and Laplacian Eigenmaps into a model parameterized by a shallow feed forward network. We introduce a new term, Compression Factor, that enables our method to combat the curse of dimensionality. The proposed algorithm is suitable for manifold visualization and sample clustering with labelled or unlabelled data. We demonstrate that our method is competitive with current state-of-the-art methods on hyperspectral remote sensing datasets in public domain.