 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
VL4Pose: Active Learning Through Out-Of-Distribution Detection For Pose Estimation
Oct 12, 2022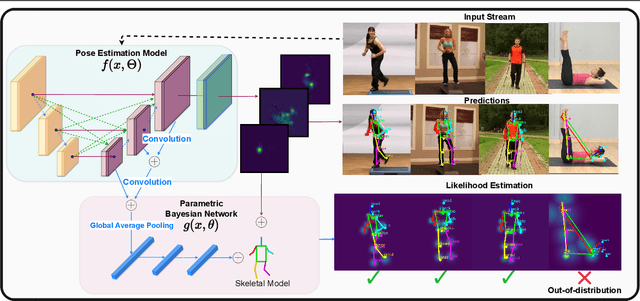
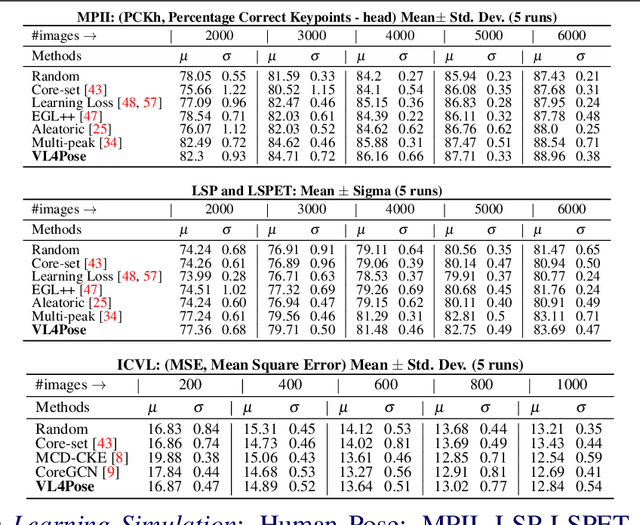

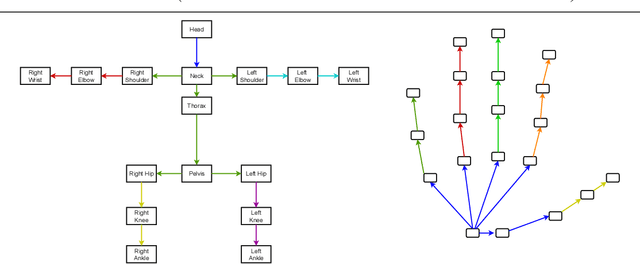
Advances in computing have enabled widespread access to pose estimation, creating new sources of data streams. Unlike mock set-ups for data collection, tapping into these data streams through on-device active learning allows us to directly sample from the real world to improve the spread of the training distribution. However, on-device computing power is limited, implying that any candidate active learning algorithm should have a low compute footprint while also being reliable. Although multiple algorithms cater to pose estimation, they either use extensive compute to power state-of-the-art results or are not competitive in low-resource settings. We address this limitation with VL4Pose (Visual Likelihood For Pose Estimation), a first principles approach for active learning through out-of-distribution detection. We begin with a simple premise: pose estimators often predict incoherent poses for out-of-distribution samples. Hence, can we identify a distribution of poses the model has been trained on, to identify incoherent poses the model is unsure of? Our solution involves modelling the pose through a simple parametric Bayesian network trained via maximum likelihood estimation. Therefore, poses incurring a low likelihood within our framework are out-of-distribution samples making them suitable candidates for annotation. We also observe two useful side-outcomes: VL4Pose in-principle yields better uncertainty estimates by unifying joint and pose level ambiguity, as well as the unintentional but welcome ability of VL4Pose to perform pose refinement in limited scenarios. We perform qualitative and quantitative experiments on three datasets: MPII, LSP and ICVL, spanning human and hand pose estimation. Finally, we note that VL4Pose is simple, computationally inexpensive and competitive, making it suitable for challenging tasks such as on-device active learning.
Multilingual CheckList: Generation and Evaluation
Mar 30, 2022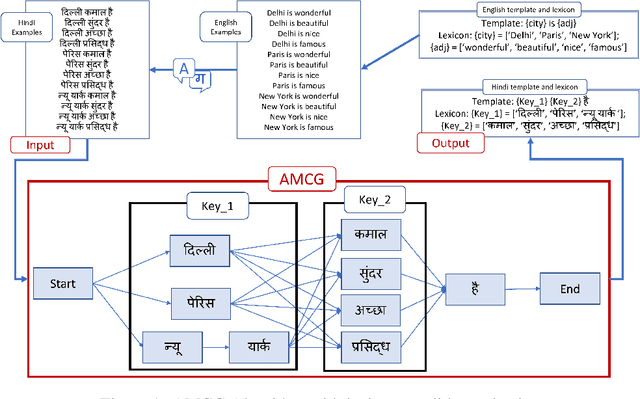
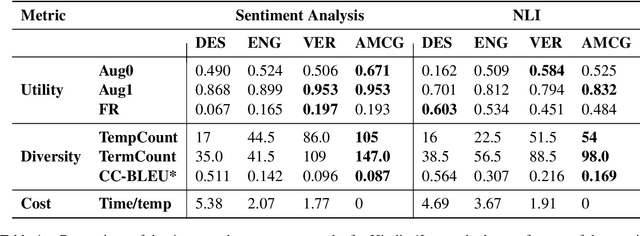
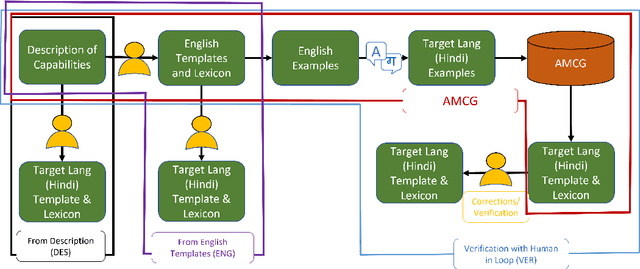
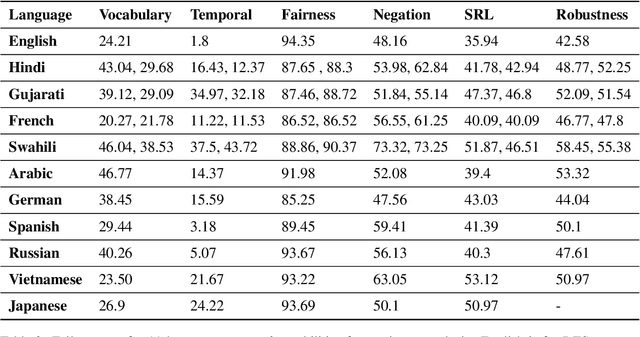
The recently proposed CheckList (Riberio et al,. 2020) approach to evaluation of NLP systems has revealed high failure rates for basic capabilities for multiple state-of-the-art and commercial models. However, the CheckList creation process is manual which creates a bottleneck towards creation of multilingual CheckLists catering 100s of languages. In this work, we explore multiple approaches to generate and evaluate the quality of Multilingual CheckList. We device an algorithm -- Automated Multilingual Checklist Generation (AMCG) for automatically transferring a CheckList from a source to a target language that relies on a reasonable machine translation system. We then compare the CheckList generated by AMCG with CheckLists generated with different levels of human intervention. Through in-depth crosslingual experiments between English and Hindi, and broad multilingual experiments spanning 11 languages, we show that the automatic approach can provide accurate estimates of failure rates of a model across capabilities, as would a human-verified CheckList, and better than CheckLists generated by humans from scratch.
RDD-Eclat: Approaches to Parallelize Eclat Algorithm on Spark RDD Framework (Extended Version)
Oct 22, 2021Frequent itemset mining (FIM) is a highly computational and data intensive algorithm. Therefore, parallel and distributed FIM algorithms have been designed to process large volume of data in a reduced time. Recently, a number of FIM algorithms have been designed on Hadoop MapReduce, a distributed big data processing framework. But, due to heavy disk I/O, MapReduce is found to be inefficient for the highly iterative FIM algorithms. Therefore, Spark, a more efficient distributed data processing framework, has been developed with in-memory computation and resilient distributed dataset (RDD) features to support the iterative algorithms. On this framework, Apriori and FP-Growth based FIM algorithms have been designed on the Spark RDD framework, but Eclat-based algorithm has not been explored yet. In this paper, RDD-Eclat, a parallel Eclat algorithm on the Spark RDD framework is proposed with its five variants. The proposed algorithms are evaluated on the various benchmark datasets, and the experimental results show that RDD-Eclat outperforms the Spark-based Apriori by many times. Also, the experimental results show the scalability of the proposed algorithms on increasing the number of cores and size of the dataset.
RDD-Eclat: Approaches to Parallelize Eclat Algorithm on Spark RDD Framework
Dec 13, 2019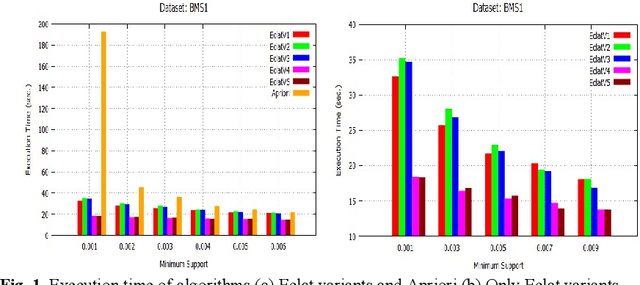
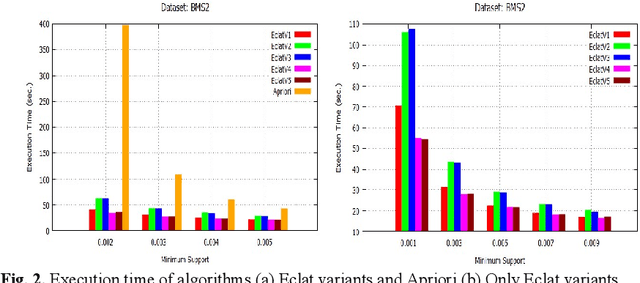
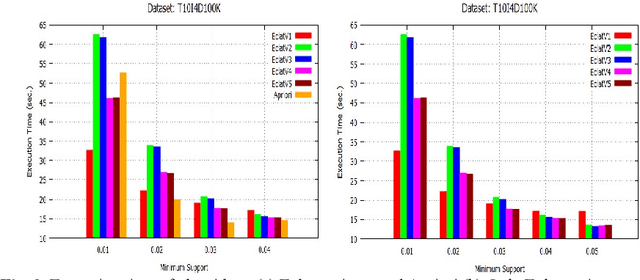
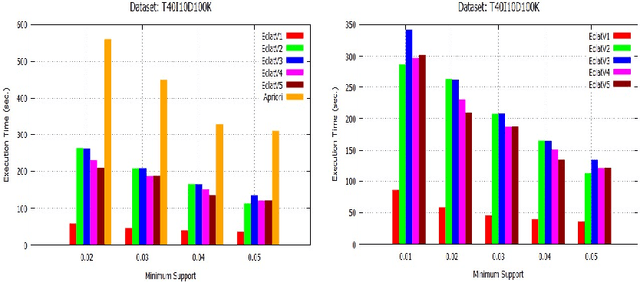
Initially, a number of frequent itemset mining (FIM) algorithms have been designed on the Hadoop MapReduce, a distributed big data processing framework. But, due to heavy disk I/O, MapReduce is found to be inefficient for such highly iterative algorithms. Therefore, Spark, a more efficient distributed data processing framework, has been developed with in-memory computation and resilient distributed dataset (RDD) features to support the iterative algorithms. On the Spark RDD framework, Apriori and FP-Growth based FIM algorithms have been designed, but Eclat-based algorithm has not been explored yet. In this paper, RDD-Eclat, a parallel Eclat algorithm on the Spark RDD framework is proposed with its five variants. The proposed algorithms are evaluated on the various benchmark datasets, which shows that RDD-Eclat outperforms the Spark-based Apriori by many times. Also, the experimental results show the scalability of the proposed algorithms on increasing the number of cores and size of the dataset.
* 16 pages, 6 figures, ICCNCT 2019
Mining Association Rules in Various Computing Environments: A Survey
Jun 30, 2019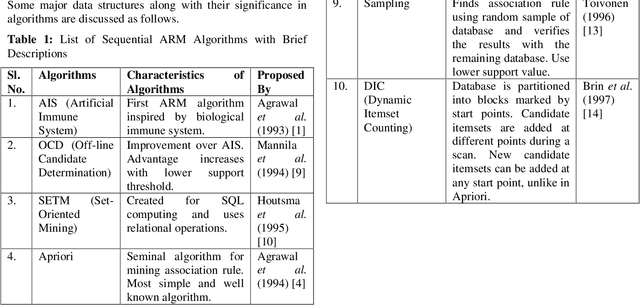
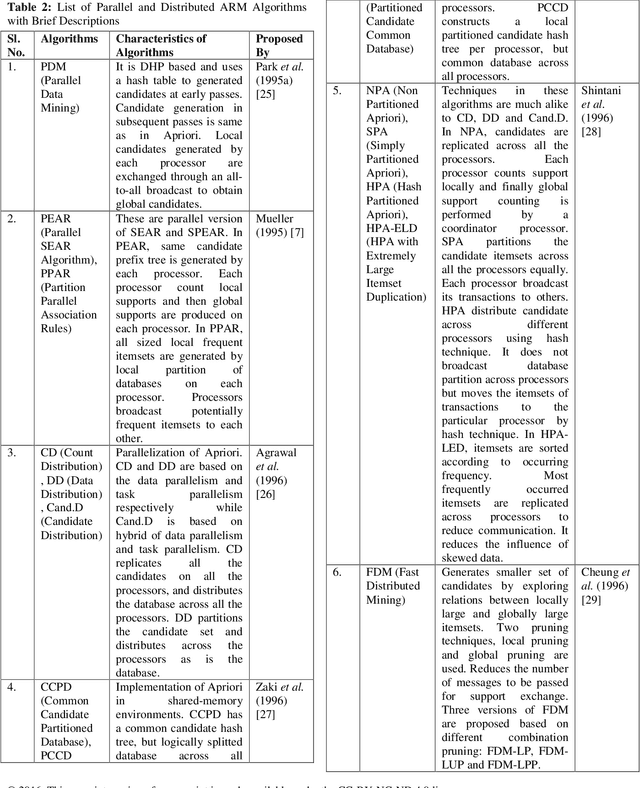
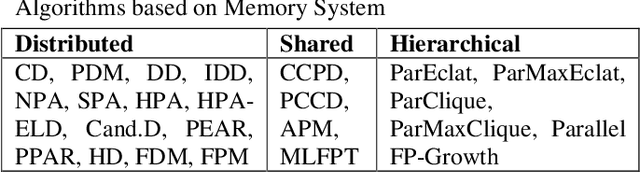

Association Rule Mining (ARM) is one of the well know and most researched technique of data mining. There are so many ARM algorithms have been designed that their counting is a large number. In this paper we have surveyed the various ARM algorithms in four computing environments. The considered computing environments are sequential computing, parallel and distributed computing, grid computing and cloud computing. With the emergence of new computing paradigm, ARM algorithms have been designed by many researchers to improve the efficiency by utilizing the new paradigm. This paper represents the journey of ARM algorithms started from sequential algorithms, and through parallel and distributed, and grid based algorithms to the current state-of-the-art, along with the motives for adopting new machinery.
* 14 pages
Learning From Less Data: Diversified Subset Selection and Active Learning in Image Classification Tasks
May 28, 2018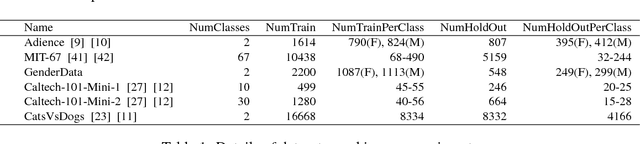
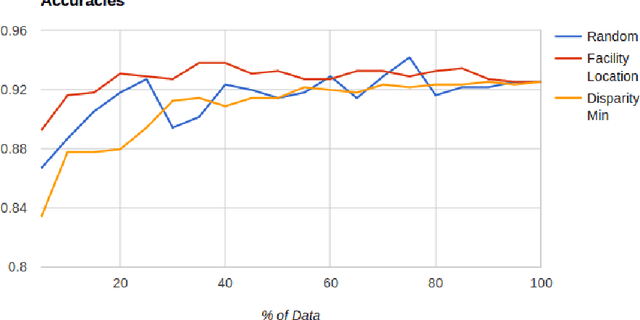
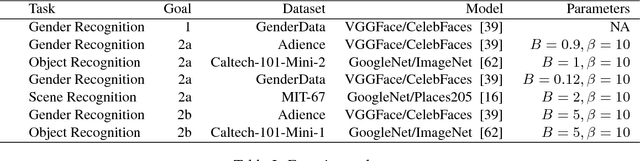
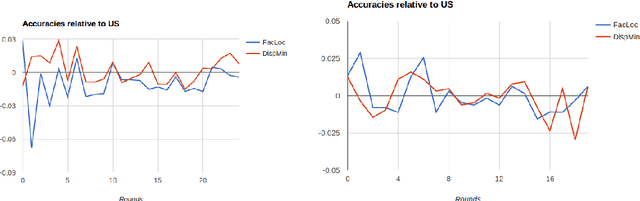
Supervised machine learning based state-of-the-art computer vision techniques are in general data hungry and pose the challenges of not having adequate computing resources and of high costs involved in human labeling efforts. Training data subset selection and active learning techniques have been proposed as possible solutions to these challenges respectively. A special class of subset selection functions naturally model notions of diversity, coverage and representation and they can be used to eliminate redundancy and thus lend themselves well for training data subset selection. They can also help improve the efficiency of active learning in further reducing human labeling efforts by selecting a subset of the examples obtained using the conventional uncertainty sampling based techniques. In this work we empirically demonstrate the effectiveness of two diversity models, namely the Facility-Location and Disparity-Min models for training-data subset selection and reducing labeling effort. We do this for a variety of computer vision tasks including Gender Recognition, Scene Recognition and Object Recognition. Our results show that subset selection done in the right way can add 2-3% in accuracy on existing baselines, particularly in the case of less training data. This allows the training of complex machine learning models (like Convolutional Neural Networks) with much less training data while incurring minimal performance loss.