 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Sign Language Recognition System using Deep Learning with MediaPipe Holistic
Nov 07, 2024Sign languages are the language of hearing-impaired people who use visuals like the hand, facial, and body movements for communication. There are different signs and gestures representing alphabets, words, and phrases. Nowadays approximately 300 sign languages are being practiced worldwide such as American Sign Language (ASL), Chinese Sign Language (CSL), Indian Sign Language (ISL), and many more. Sign languages are dependent on the vocal language of a place. Unlike vocal or spoken languages, there are no helping words in sign language like is, am, are, was, were, will, be, etc. As only a limited population is well-versed in sign language, this lack of familiarity of sign language hinders hearing-impaired people from communicating freely and easily with everyone. This issue can be addressed by a sign language recognition (SLR) system which has the capability to translate the sign language into vocal language. In this paper, a continuous SLR system is proposed using a deep learning model employing Long Short-Term Memory (LSTM), trained and tested on an ISL primary dataset. This dataset is created using MediaPipe Holistic pipeline for tracking face, hand, and body movements and collecting landmarks. The system recognizes the signs and gestures in real-time with 88.23% accuracy.
* 14 pages, 4 figures, Wireless Pers Commun
An Empirical Study of Mamba-based Language Models
Jun 12, 2024



Selective state-space models (SSMs) like Mamba overcome some of the shortcomings of Transformers, such as quadratic computational complexity with sequence length and large inference-time memory requirements from the key-value cache. Moreover, recent studies have shown that SSMs can match or exceed the language modeling capabilities of Transformers, making them an attractive alternative. In a controlled setting (e.g., same data), however, studies so far have only presented small scale experiments comparing SSMs to Transformers. To understand the strengths and weaknesses of these architectures at larger scales, we present a direct comparison between 8B-parameter Mamba, Mamba-2, and Transformer models trained on the same datasets of up to 3.5T tokens. We also compare these models to a hybrid architecture consisting of 43% Mamba-2, 7% attention, and 50% MLP layers (Mamba-2-Hybrid). Using a diverse set of tasks, we answer the question of whether Mamba models can match Transformers at larger training budgets. Our results show that while pure SSMs match or exceed Transformers on many tasks, they lag behind Transformers on tasks which require strong copying or in-context learning abilities (e.g., 5-shot MMLU, Phonebook) or long-context reasoning. In contrast, we find that the 8B Mamba-2-Hybrid exceeds the 8B Transformer on all 12 standard tasks we evaluated (+2.65 points on average) and is predicted to be up to 8x faster when generating tokens at inference time. To validate long-context capabilities, we provide additional experiments evaluating variants of the Mamba-2-Hybrid and Transformer extended to support 16K, 32K, and 128K sequences. On an additional 23 long-context tasks, the hybrid model continues to closely match or exceed the Transformer on average. To enable further study, we release the checkpoints as well as the code used to train our models as part of NVIDIA's Megatron-LM project.
Medical Image Analysis for Detection, Treatment and Planning of Disease using Artificial Intelligence Approaches
May 18, 2024


X-ray is one of the prevalent image modalities for the detection and diagnosis of the human body. X-ray provides an actual anatomical structure of an organ present with disease or absence of disease. Segmentation of disease in chest X-ray images is essential for the diagnosis and treatment. In this paper, a framework for the segmentation of X-ray images using artificial intelligence techniques has been discussed. Here data has been pre-processed and cleaned followed by segmentation using SegNet and Residual Net approaches to X-ray images. Finally, segmentation has been evaluated using well known metrics like Loss, Dice Coefficient, Jaccard Coefficient, Precision, Recall, Binary Accuracy, and Validation Accuracy. The experimental results reveal that the proposed approach performs better in all respect of well-known parameters with 16 batch size and 50 epochs. The value of validation accuracy, precision, and recall of SegNet and Residual Unet models are 0.9815, 0.9699, 0.9574, and 0.9901, 0.9864, 0.9750 respectively.
* 10 pages, 3 figures
The State-of-the-Art in Air Pollution Monitoring and Forecasting Systems using IoT, Big Data, and Machine Learning
Apr 19, 2023The quality of air is closely linked with the life quality of humans, plantations, and wildlife. It needs to be monitored and preserved continuously. Transportations, industries, construction sites, generators, fireworks, and waste burning have a major percentage in degrading the air quality. These sources are required to be used in a safe and controlled manner. Using traditional laboratory analysis or installing bulk and expensive models every few miles is no longer efficient. Smart devices are needed for collecting and analyzing air data. The quality of air depends on various factors, including location, traffic, and time. Recent researches are using machine learning algorithms, big data technologies, and the Internet of Things to propose a stable and efficient model for the stated purpose. This review paper focuses on studying and compiling recent research in this field and emphasizes the Data sources, Monitoring, and Forecasting models. The main objective of this paper is to provide the astuteness of the researches happening to improve the various aspects of air polluting models. Further, it casts light on the various research issues and challenges also.
E-Mail Assistant -- Automation of E-Mail Handling and Management using Robotic Process Automation
May 12, 2022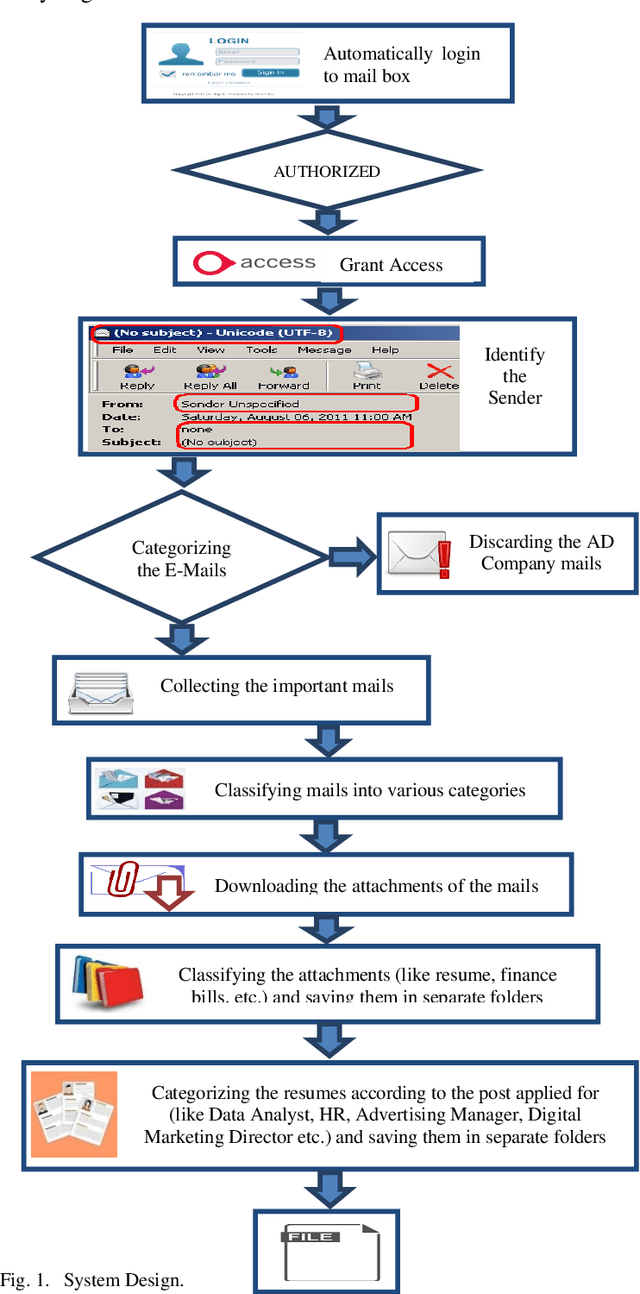
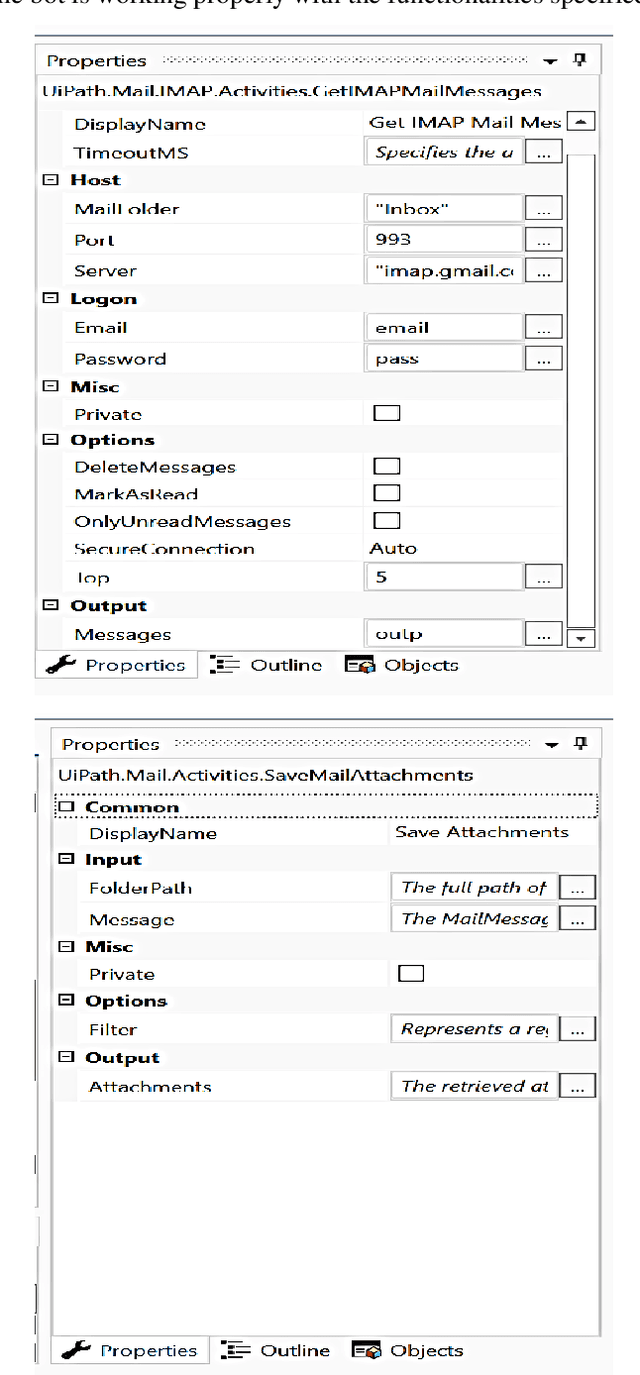
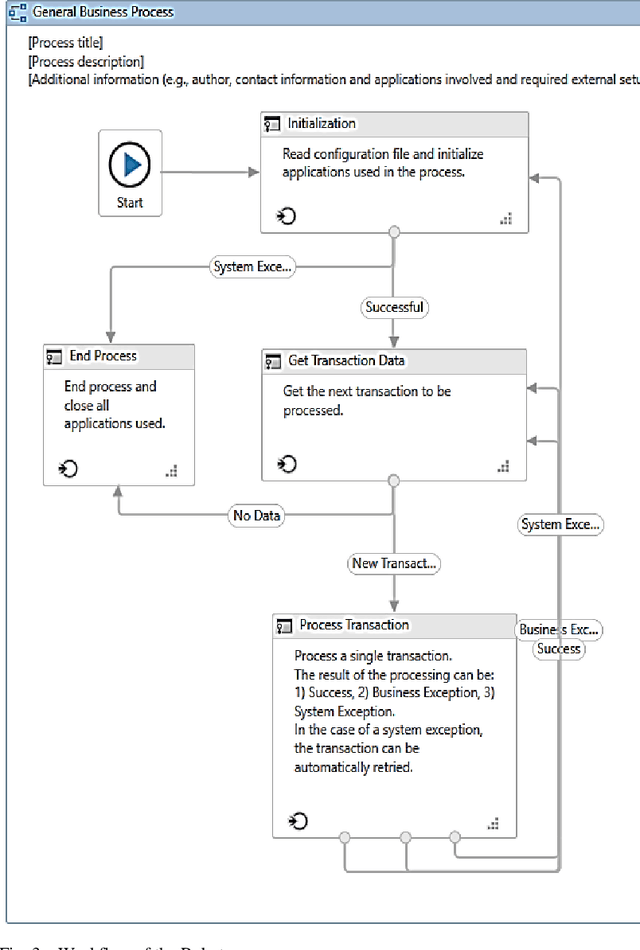

In this paper, a workflow for designing a bot using Robotic Process Automation (RPA), associated with Artificial Intelligence (AI) that is used for information extraction, classification, etc., is proposed. The bot is equipped with many features that make email handling a stress-free job. It automatically login into the mailbox through secured channels, distinguishes between the useful and not useful emails, classifies the emails into different labels, downloads the attached files, creates different directories, and stores the downloaded files into relevant directories. It moves the not useful emails into the trash. Further, the bot can also be trained to rename the attached files with the names of the sender/applicant in case of a job application for the sake of convenience. The bot is designed and tested using the UiPath tool to improve the performance of the system. The paper also discusses the further possible functionalities that can be added on to the bot.
Sign Language Recognition System using TensorFlow Object Detection API
Jan 05, 2022
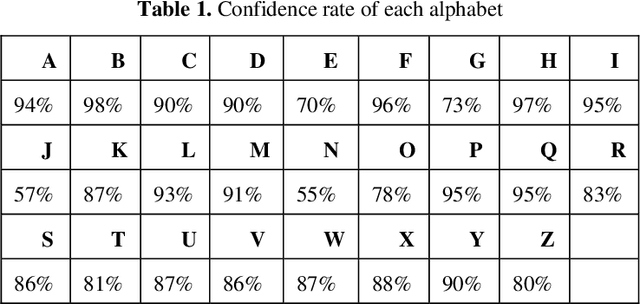


Communication is defined as the act of sharing or exchanging information, ideas or feelings. To establish communication between two people, both of them are required to have knowledge and understanding of a common language. But in the case of deaf and dumb people, the means of communication are different. Deaf is the inability to hear and dumb is the inability to speak. They communicate using sign language among themselves and with normal people but normal people do not take seriously the importance of sign language. Not everyone possesses the knowledge and understanding of sign language which makes communication difficult between a normal person and a deaf and dumb person. To overcome this barrier, one can build a model based on machine learning. A model can be trained to recognize different gestures of sign language and translate them into English. This will help a lot of people in communicating and conversing with deaf and dumb people. The existing Indian Sing Language Recognition systems are designed using machine learning algorithms with single and double-handed gestures but they are not real-time. In this paper, we propose a method to create an Indian Sign Language dataset using a webcam and then using transfer learning, train a TensorFlow model to create a real-time Sign Language Recognition system. The system achieves a good level of accuracy even with a limited size dataset.
Sentiment Analysis and Sarcasm Detection of Indian General Election Tweets
Jan 03, 2022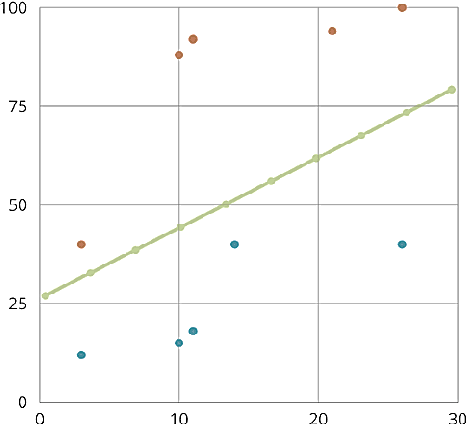
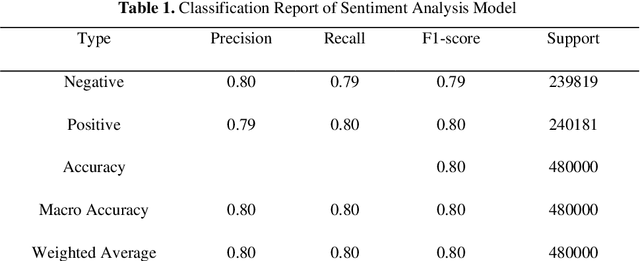
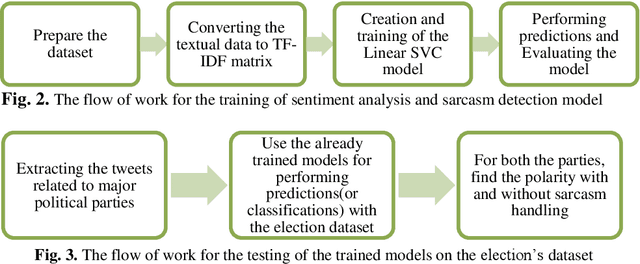
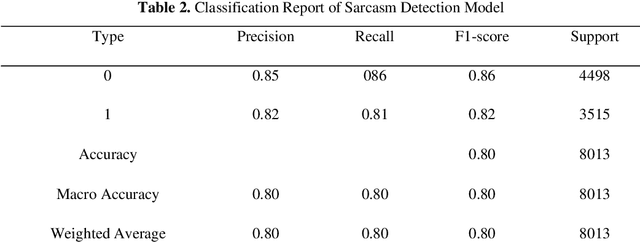
Social Media usage has increased to an all-time high level in today's digital world. The majority of the population uses social media tools (like Twitter, Facebook, YouTube, etc.) to share their thoughts and experiences with the community. Analysing the sentiments and opinions of the common public is very important for both the government and the business people. This is the reason behind the activeness of many media agencies during the election time for performing various kinds of opinion polls. In this paper, we have worked towards analysing the sentiments of the people of India during the Lok Sabha election of 2019 using the Twitter data of that duration. We have built an automatic tweet analyser using the Transfer Learning technique to handle the unsupervised nature of this problem. We have used the Linear Support Vector Classifiers method in our Machine Learning model, also, the Term Frequency Inverse Document Frequency (TF-IDF) methodology for handling the textual data of tweets. Further, we have increased the capability of the model to address the sarcastic tweets posted by some of the users, which has not been yet considered by the researchers in this domain.
RDD-Eclat: Approaches to Parallelize Eclat Algorithm on Spark RDD Framework (Extended Version)
Oct 22, 2021Frequent itemset mining (FIM) is a highly computational and data intensive algorithm. Therefore, parallel and distributed FIM algorithms have been designed to process large volume of data in a reduced time. Recently, a number of FIM algorithms have been designed on Hadoop MapReduce, a distributed big data processing framework. But, due to heavy disk I/O, MapReduce is found to be inefficient for the highly iterative FIM algorithms. Therefore, Spark, a more efficient distributed data processing framework, has been developed with in-memory computation and resilient distributed dataset (RDD) features to support the iterative algorithms. On this framework, Apriori and FP-Growth based FIM algorithms have been designed on the Spark RDD framework, but Eclat-based algorithm has not been explored yet. In this paper, RDD-Eclat, a parallel Eclat algorithm on the Spark RDD framework is proposed with its five variants. The proposed algorithms are evaluated on the various benchmark datasets, and the experimental results show that RDD-Eclat outperforms the Spark-based Apriori by many times. Also, the experimental results show the scalability of the proposed algorithms on increasing the number of cores and size of the dataset.
RDD-Eclat: Approaches to Parallelize Eclat Algorithm on Spark RDD Framework
Dec 13, 2019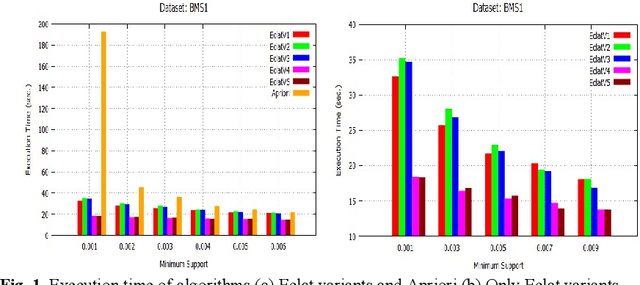
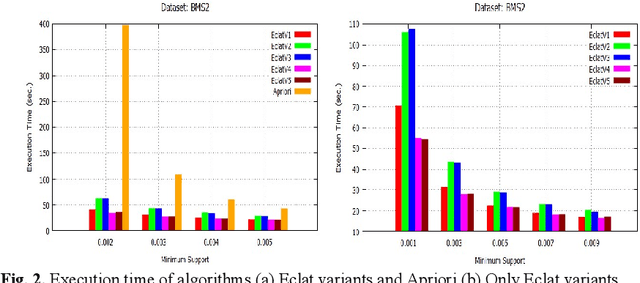
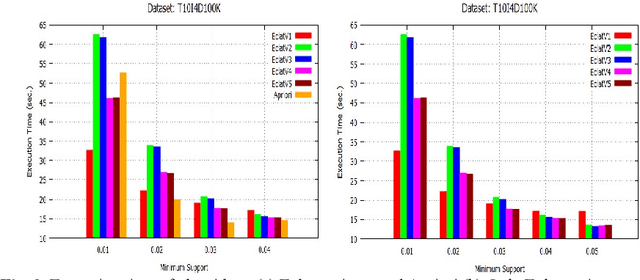
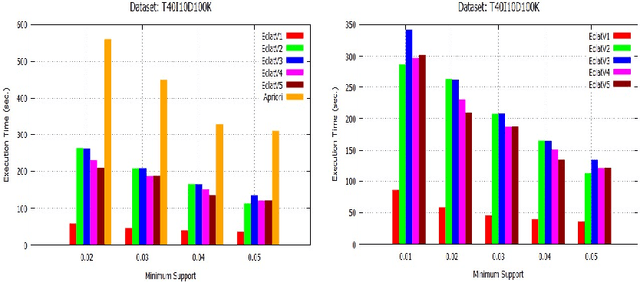
Initially, a number of frequent itemset mining (FIM) algorithms have been designed on the Hadoop MapReduce, a distributed big data processing framework. But, due to heavy disk I/O, MapReduce is found to be inefficient for such highly iterative algorithms. Therefore, Spark, a more efficient distributed data processing framework, has been developed with in-memory computation and resilient distributed dataset (RDD) features to support the iterative algorithms. On the Spark RDD framework, Apriori and FP-Growth based FIM algorithms have been designed, but Eclat-based algorithm has not been explored yet. In this paper, RDD-Eclat, a parallel Eclat algorithm on the Spark RDD framework is proposed with its five variants. The proposed algorithms are evaluated on the various benchmark datasets, which shows that RDD-Eclat outperforms the Spark-based Apriori by many times. Also, the experimental results show the scalability of the proposed algorithms on increasing the number of cores and size of the dataset.
* 16 pages, 6 figures, ICCNCT 2019
Mining Association Rules in Various Computing Environments: A Survey
Jun 30, 2019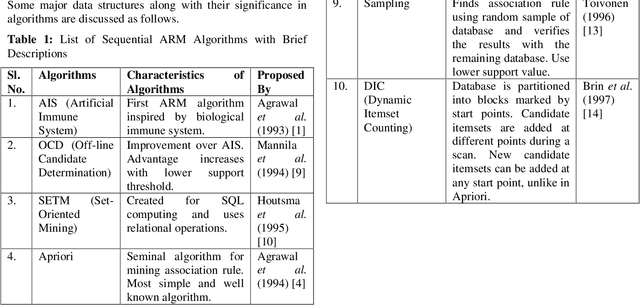
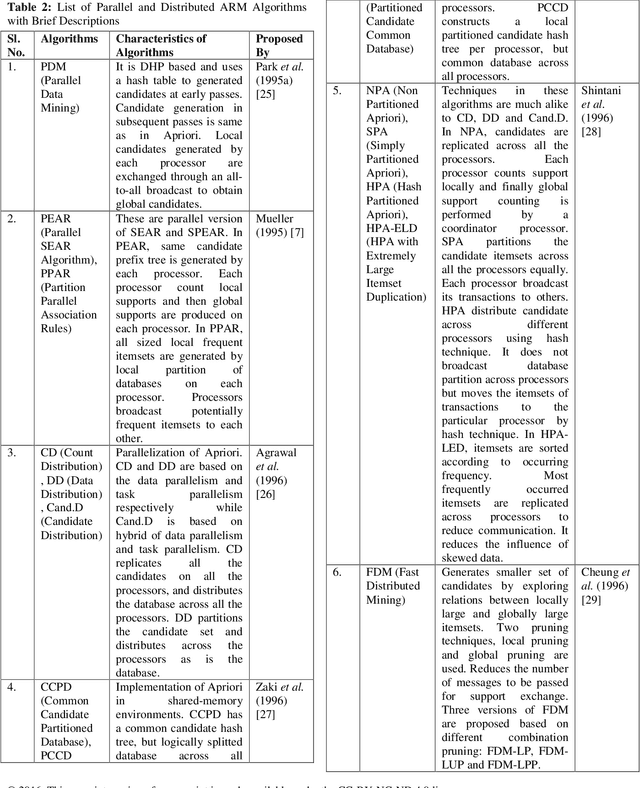
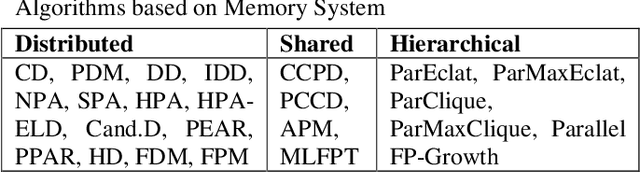

Association Rule Mining (ARM) is one of the well know and most researched technique of data mining. There are so many ARM algorithms have been designed that their counting is a large number. In this paper we have surveyed the various ARM algorithms in four computing environments. The considered computing environments are sequential computing, parallel and distributed computing, grid computing and cloud computing. With the emergence of new computing paradigm, ARM algorithms have been designed by many researchers to improve the efficiency by utilizing the new paradigm. This paper represents the journey of ARM algorithms started from sequential algorithms, and through parallel and distributed, and grid based algorithms to the current state-of-the-art, along with the motives for adopting new machinery.
* 14 pages