 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRDD-Eclat: Approaches to Parallelize Eclat Algorithm on Spark RDD Framework (Extended Version)
Oct 22, 2021Frequent itemset mining (FIM) is a highly computational and data intensive algorithm. Therefore, parallel and distributed FIM algorithms have been designed to process large volume of data in a reduced time. Recently, a number of FIM algorithms have been designed on Hadoop MapReduce, a distributed big data processing framework. But, due to heavy disk I/O, MapReduce is found to be inefficient for the highly iterative FIM algorithms. Therefore, Spark, a more efficient distributed data processing framework, has been developed with in-memory computation and resilient distributed dataset (RDD) features to support the iterative algorithms. On this framework, Apriori and FP-Growth based FIM algorithms have been designed on the Spark RDD framework, but Eclat-based algorithm has not been explored yet. In this paper, RDD-Eclat, a parallel Eclat algorithm on the Spark RDD framework is proposed with its five variants. The proposed algorithms are evaluated on the various benchmark datasets, and the experimental results show that RDD-Eclat outperforms the Spark-based Apriori by many times. Also, the experimental results show the scalability of the proposed algorithms on increasing the number of cores and size of the dataset.
RDD-Eclat: Approaches to Parallelize Eclat Algorithm on Spark RDD Framework
Dec 13, 2019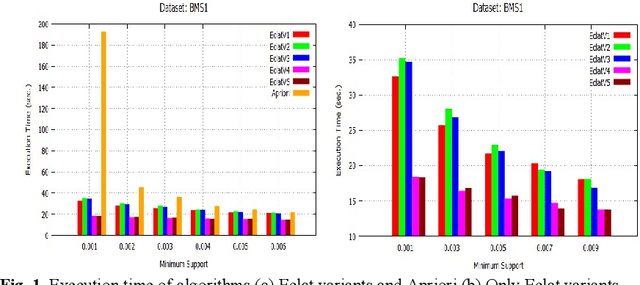
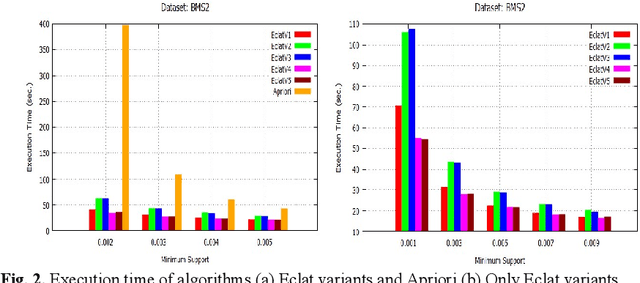
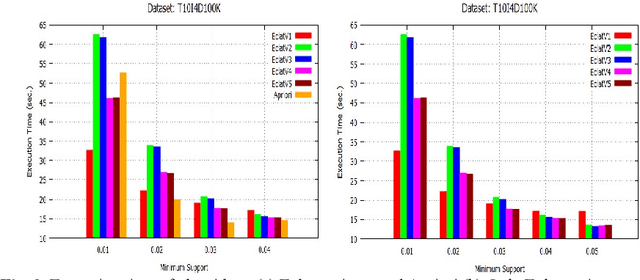
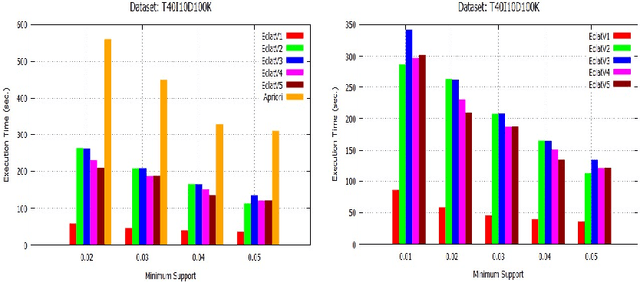
Initially, a number of frequent itemset mining (FIM) algorithms have been designed on the Hadoop MapReduce, a distributed big data processing framework. But, due to heavy disk I/O, MapReduce is found to be inefficient for such highly iterative algorithms. Therefore, Spark, a more efficient distributed data processing framework, has been developed with in-memory computation and resilient distributed dataset (RDD) features to support the iterative algorithms. On the Spark RDD framework, Apriori and FP-Growth based FIM algorithms have been designed, but Eclat-based algorithm has not been explored yet. In this paper, RDD-Eclat, a parallel Eclat algorithm on the Spark RDD framework is proposed with its five variants. The proposed algorithms are evaluated on the various benchmark datasets, which shows that RDD-Eclat outperforms the Spark-based Apriori by many times. Also, the experimental results show the scalability of the proposed algorithms on increasing the number of cores and size of the dataset.
* 16 pages, 6 figures, ICCNCT 2019
Mining Association Rules in Various Computing Environments: A Survey
Jun 30, 2019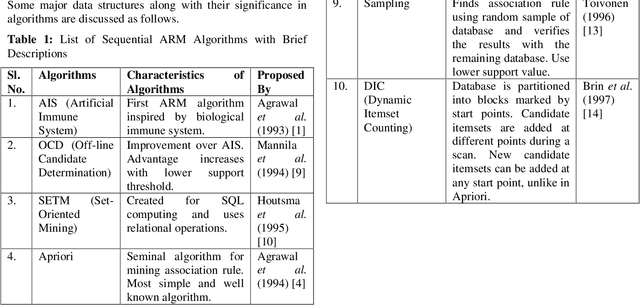
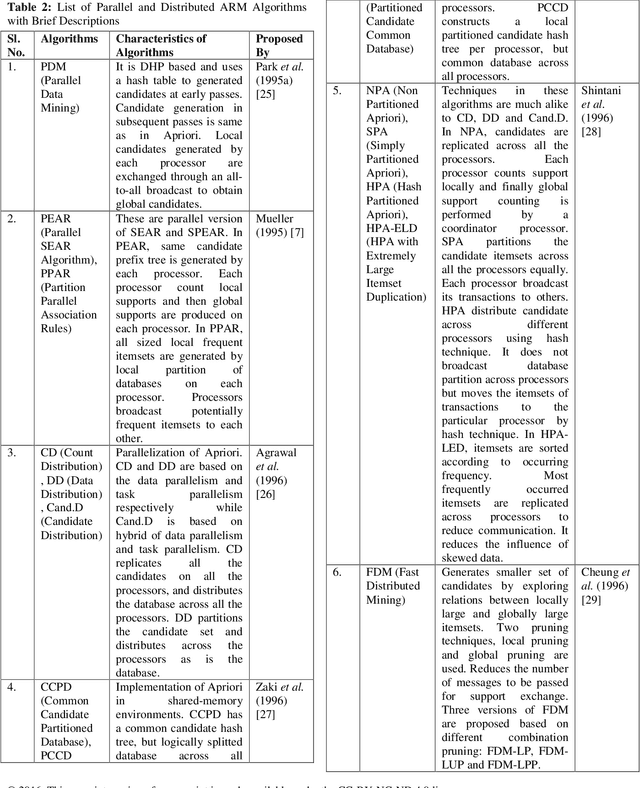
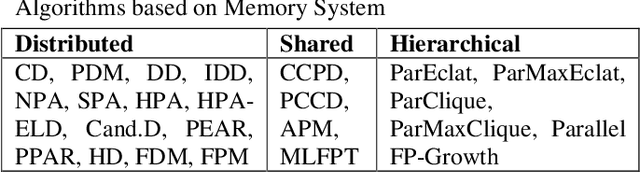

Association Rule Mining (ARM) is one of the well know and most researched technique of data mining. There are so many ARM algorithms have been designed that their counting is a large number. In this paper we have surveyed the various ARM algorithms in four computing environments. The considered computing environments are sequential computing, parallel and distributed computing, grid computing and cloud computing. With the emergence of new computing paradigm, ARM algorithms have been designed by many researchers to improve the efficiency by utilizing the new paradigm. This paper represents the journey of ARM algorithms started from sequential algorithms, and through parallel and distributed, and grid based algorithms to the current state-of-the-art, along with the motives for adopting new machinery.
* 14 pages