 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Universal Video Segmentation Model
Aug 26, 2025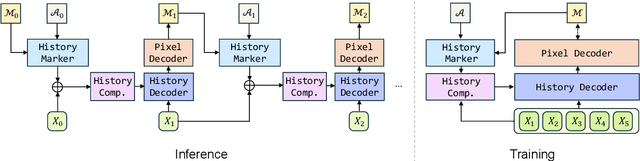
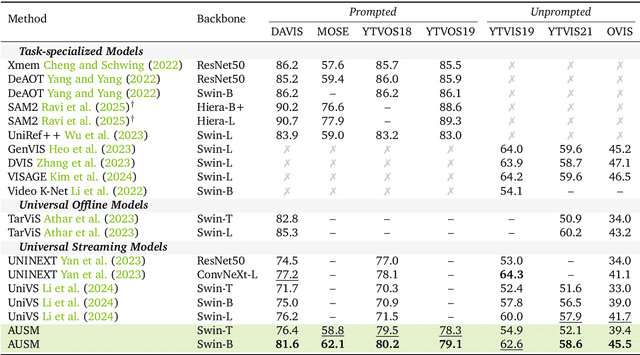
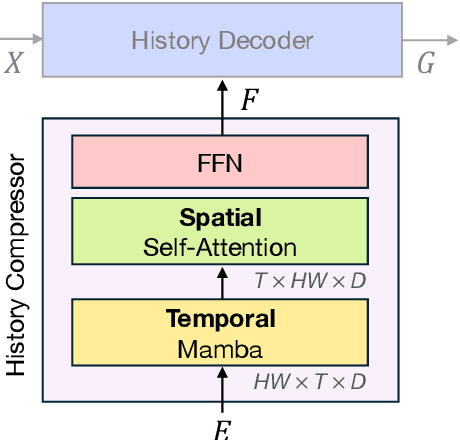

Recent video foundation models such as SAM2 excel at prompted video segmentation by treating masks as a general-purpose primitive. However, many real-world settings require unprompted segmentation that aims to detect and track all objects in a video without external cues, leaving today's landscape fragmented across task-specific models and pipelines. We recast streaming video segmentation as sequential mask prediction, analogous to language modeling, and introduce the Autoregressive Universal Segmentation Model (AUSM), a single architecture that unifies both prompted and unprompted video segmentation. Built on recent state-space models, AUSM maintains a fixed-size spatial state and scales to video streams of arbitrary length. Furthermore, all components of AUSM are designed for parallel training across frames, yielding substantial speedups over iterative training. On standard benchmarks (DAVIS17, YouTube-VOS 2018 & 2019, MOSE, YouTube-VIS 2019 & 2021, and OVIS) AUSM outperforms prior universal streaming video segmentation methods and achieves up to 2.5x faster training on 16-frame sequences.
Dynamic Chunking for End-to-End Hierarchical Sequence Modeling
Jul 10, 2025Despite incredible progress in language models (LMs) in recent years, largely resulting from moving away from specialized models designed for specific tasks to general models based on powerful architectures (e.g. the Transformer) that learn everything from raw data, pre-processing steps such as tokenization remain a barrier to true end-to-end foundation models. We introduce a collection of new techniques that enable a dynamic chunking mechanism which automatically learns content -- and context -- dependent segmentation strategies learned jointly with the rest of the model. Incorporating this into an explicit hierarchical network (H-Net) allows replacing the (implicitly hierarchical) tokenization-LM-detokenization pipeline with a single model learned fully end-to-end. When compute- and data- matched, an H-Net with one stage of hierarchy operating at the byte level outperforms a strong Transformer language model operating over BPE tokens. Iterating the hierarchy to multiple stages further increases its performance by modeling multiple levels of abstraction, demonstrating significantly better scaling with data and matching a token-based Transformer of twice its size. H-Nets pretrained on English show significantly increased character-level robustness, and qualitatively learn meaningful data-dependent chunking strategies without any heuristics or explicit supervision. Finally, the H-Net's improvement over tokenized pipelines is further increased in languages and modalities with weaker tokenization heuristics, such as Chinese and code, or DNA sequences (nearly 4x improvement in data efficiency over baselines), showing the potential of true end-to-end models that learn and scale better from unprocessed data.
Understanding and Improving Length Generalization in Recurrent Models
Jul 03, 2025Recently, recurrent models such as state space models and linear attention have become popular due to their linear complexity in the sequence length. Thanks to their recurrent nature, in principle they can process arbitrarily long sequences, but their performance sometimes drops considerably beyond their training context lengths-i.e. they fail to length generalize. In this work, we provide comprehensive empirical and theoretical analysis to support the unexplored states hypothesis, which posits that models fail to length generalize when during training they are only exposed to a limited subset of the distribution of all attainable states (i.e. states that would be attained if the recurrence was applied to long sequences). Furthermore, we investigate simple training interventions that aim to increase the coverage of the states that the model is trained on, e.g. by initializing the state with Gaussian noise or with the final state of a different input sequence. With only 500 post-training steps ($\sim 0.1\%$ of the pre-training budget), these interventions enable length generalization for sequences that are orders of magnitude longer than the training context (e.g. $2k\longrightarrow 128k$) and show improved performance in long context tasks, thus presenting a simple and efficient way to enable robust length generalization in general recurrent models.
Understanding the Skill Gap in Recurrent Language Models: The Role of the Gather-and-Aggregate Mechanism
Apr 22, 2025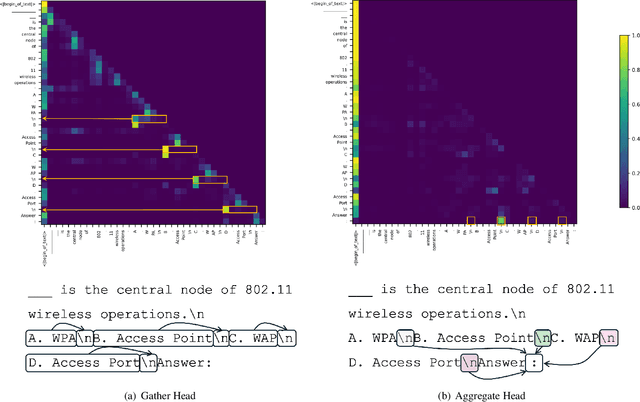



SSMs offer efficient processing of long sequences with fixed state sizes, but struggle with algorithmic tasks like retrieving past context. In this work, we examine how such in-context retrieval operates within Transformer- and SSM-based language models. We find that both architectures develop the same fundamental Gather-and-Aggregate (G&A) mechanism. A Gather Head first identifies and extracts relevant information from the context, which an Aggregate Head then integrates into a final representation. Across both model types, G&A concentrates in just a few heads, making them critical bottlenecks even for benchmarks that require a basic form of retrieval. For example, disabling a single Gather or Aggregate Head of a pruned Llama-3.1-8B degrades its ability to retrieve the correct answer letter in MMLU, reducing accuracy from 66% to 25%. This finding suggests that in-context retrieval can obscure the limited knowledge demands of certain tasks. Despite strong MMLU performance with retrieval intact, the pruned model fails on other knowledge tests. Similar G&A dependencies exist in GSM8K, BBH, and dialogue tasks. Given the significance of G&A in performance, we show that retrieval challenges in SSMs manifest in how they implement G&A, leading to smoother attention patterns rather than the sharp token transitions that effective G&A relies on. Thus, while a gap exists between Transformers and SSMs in implementing in-context retrieval, it is confined to a few heads, not the entire model. This insight suggests a unified explanation for performance differences between Transformers and SSMs while also highlighting ways to combine their strengths. For example, in pretrained hybrid models, attention components naturally take on the role of Aggregate Heads. Similarly, in a pretrained pure SSM, replacing a single G&A head with an attention-based variant significantly improves retrieval.
Lyra: An Efficient and Expressive Subquadratic Architecture for Modeling Biological Sequences
Mar 20, 2025Deep learning architectures such as convolutional neural networks and Transformers have revolutionized biological sequence modeling, with recent advances driven by scaling up foundation and task-specific models. The computational resources and large datasets required, however, limit their applicability in biological contexts. We introduce Lyra, a subquadratic architecture for sequence modeling, grounded in the biological framework of epistasis for understanding sequence-to-function relationships. Mathematically, we demonstrate that state space models efficiently capture global epistatic interactions and combine them with projected gated convolutions for modeling local relationships. We demonstrate that Lyra is performant across over 100 wide-ranging biological tasks, achieving state-of-the-art (SOTA) performance in many key areas, including protein fitness landscape prediction, biophysical property prediction (e.g. disordered protein region functions) peptide engineering applications (e.g. antibody binding, cell-penetrating peptide prediction), RNA structure analysis, RNA function prediction, and CRISPR guide design. It achieves this with orders-of-magnitude improvements in inference speed and reduction in parameters (up to 120,000-fold in our tests) compared to recent biology foundation models. Using Lyra, we were able to train and run every task in this study on two or fewer GPUs in under two hours, democratizing access to biological sequence modeling at SOTA performance, with potential applications to many fields.
Thinking Slow, Fast: Scaling Inference Compute with Distilled Reasoners
Feb 27, 2025Recent advancements have demonstrated that the performance of large language models (LLMs) can be significantly enhanced by scaling computational resources at test time. A common strategy involves generating multiple Chain-of-Thought (CoT) trajectories and aggregating their outputs through various selection mechanisms. This raises a fundamental question: can models with lower complexity leverage their superior generation throughput to outperform similarly sized Transformers for a fixed computational budget? To address this question and overcome the lack of strong subquadratic reasoners, we distill pure and hybrid Mamba models from pretrained Transformers. Trained on only 8 billion tokens, our distilled models show strong performance and scaling on mathematical reasoning datasets while being much faster at inference for large batches and long sequences. Despite the zero-shot performance hit due to distillation, both pure and hybrid Mamba models can scale their coverage and accuracy performance past their Transformer teacher models under fixed time budgets, opening a new direction for scaling inference compute.
Llamba: Scaling Distilled Recurrent Models for Efficient Language Processing
Feb 23, 2025We introduce Llamba, a family of efficient recurrent language models distilled from Llama-3.x into the Mamba architecture. The series includes Llamba-1B, Llamba-3B, and Llamba-8B, which achieve higher inference throughput and handle significantly larger batch sizes than Transformer-based models while maintaining comparable benchmark performance. Furthermore, Llamba demonstrates the effectiveness of cross-architecture distillation using MOHAWK (Bick et al., 2024), achieving these results with less than 0.1% of the training data typically used for models of similar size. To take full advantage of their efficiency, we provide an optimized implementation of Llamba for resource-constrained devices such as smartphones and edge platforms, offering a practical and memory-efficient alternative to Transformers. Overall, Llamba improves the tradeoff between speed, memory efficiency, and performance, making high-quality language models more accessible.
On the Benefits of Memory for Modeling Time-Dependent PDEs
Sep 03, 2024Data-driven techniques have emerged as a promising alternative to traditional numerical methods for solving partial differential equations (PDEs). These techniques frequently offer a better trade-off between computational cost and accuracy for many PDE families of interest. For time-dependent PDEs, existing methodologies typically treat PDEs as Markovian systems, i.e., the evolution of the system only depends on the ``current state'', and not the past states. However, distortion of the input signals -- e.g., due to discretization or low-pass filtering -- can render the evolution of the distorted signals non-Markovian. In this work, motivated by the Mori-Zwanzig theory of model reduction, we investigate the impact of architectures with memory for modeling PDEs: that is, when past states are explicitly used to predict the future. We introduce Memory Neural Operator (MemNO), a network based on the recent SSM architectures and Fourier Neural Operator (FNO). We empirically demonstrate on a variety of PDE families of interest that when the input is given on a low-resolution grid, MemNO significantly outperforms the baselines without memory, achieving more than 6 times less error on unseen PDEs. Via a combination of theory and experiments, we show that the effect of memory is particularly significant when the solution of the PDE has high frequency Fourier components (e.g., low-viscosity fluid dynamics), and it also increases robustness to observation noise.
Transformers to SSMs: Distilling Quadratic Knowledge to Subquadratic Models
Aug 19, 2024



Transformer architectures have become a dominant paradigm for domains like language modeling but suffer in many inference settings due to their quadratic-time self-attention. Recently proposed subquadratic architectures, such as Mamba, have shown promise, but have been pretrained with substantially less computational resources than the strongest Transformer models. In this work, we present a method that is able to distill a pretrained Transformer architecture into alternative architectures such as state space models (SSMs). The key idea to our approach is that we can view both Transformers and SSMs as applying different forms of mixing matrices over the token sequences. We can thus progressively distill the Transformer architecture by matching different degrees of granularity in the SSM: first matching the mixing matrices themselves, then the hidden units at each block, and finally the end-to-end predictions. Our method, called MOHAWK, is able to distill a Mamba-2 variant based on the Phi-1.5 architecture (Phi-Mamba) using only 3B tokens and a hybrid version (Hybrid Phi-Mamba) using 5B tokens. Despite using less than 1% of the training data typically used to train models from scratch, Phi-Mamba boasts substantially stronger performance compared to all past open-source non-Transformer models. MOHAWK allows models like SSMs to leverage computational resources invested in training Transformer-based architectures, highlighting a new avenue for building such models.
Hydra: Bidirectional State Space Models Through Generalized Matrix Mixers
Jul 13, 2024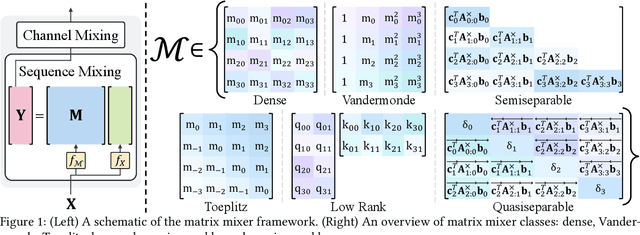
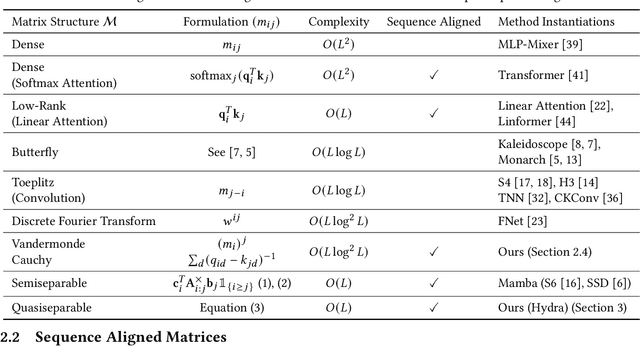
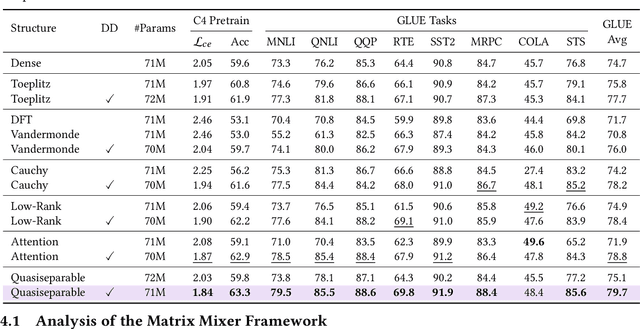
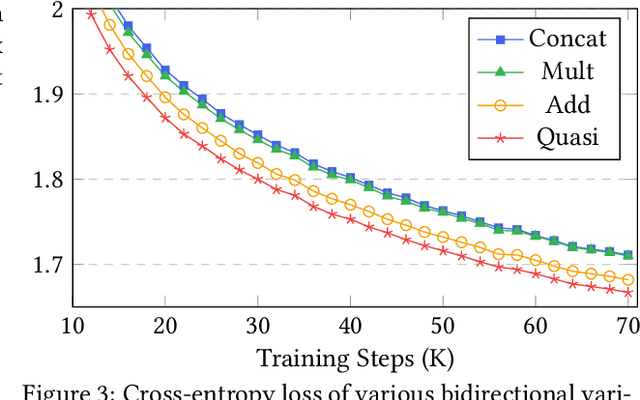
A wide array of sequence models are built on a framework modeled after Transformers, comprising alternating sequence mixer and channel mixer layers. This paper studies a unifying matrix mixer view of sequence mixers that can be conceptualized as a linear map on the input sequence. This framework encompasses a broad range of well-known sequence models, including the self-attention of Transformers as well as recent strong alternatives such as structured state space models (SSMs), and allows understanding downstream characteristics such as efficiency and expressivity through properties of their structured matrix class. We identify a key axis of matrix parameterizations termed sequence alignment, which increases the flexibility and performance of matrix mixers, providing insights into the strong performance of Transformers and recent SSMs such as Mamba. Furthermore, the matrix mixer framework offers a systematic approach to developing sequence mixers with desired properties, allowing us to develop several new sub-quadratic sequence models. In particular, we propose a natural bidirectional extension of the Mamba model (Hydra), parameterized as a quasiseparable matrix mixer, which demonstrates superior performance over other sequence models including Transformers on non-causal tasks. As a drop-in replacement for attention layers, Hydra outperforms BERT by 0.8 points on the GLUE benchmark and ViT by 2% Top-1 accuracy on ImageNet.