 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMamba-3: Improved Sequence Modeling using State Space Principles
Mar 16, 2026Scaling inference-time compute has emerged as an important driver of LLM performance, making inference efficiency a central focus of model design alongside model quality. While the current Transformer-based models deliver strong model quality, their quadratic compute and linear memory make inference expensive. This has spurred the development of sub-quadratic models with reduced linear compute and constant memory requirements. However, many recent linear models trade off model quality and capability for algorithmic efficiency, failing on tasks such as state tracking. Moreover, their theoretically linear inference remains hardware-inefficient in practice. Guided by an inference-first perspective, we introduce three core methodological improvements inspired by the state space model (SSM) viewpoint of linear models. We combine: (1) a more expressive recurrence derived from SSM discretization, (2) a complex-valued state update rule that enables richer state tracking, and (3) a multi-input, multi-output (MIMO) formulation for better model performance without increasing decode latency. Together with architectural refinements, our Mamba-3 model achieves significant gains across retrieval, state-tracking, and downstream language modeling tasks. At the 1.5B scale, Mamba-3 improves average downstream accuracy by 0.6 percentage points compared to the next best model (Gated DeltaNet), with Mamba-3's MIMO variant further improving accuracy by another 1.2 points for a total 1.8 point gain. Across state-size experiments, Mamba-3 achieves comparable perplexity to Mamba-2 despite using half of its predecessor's state size. Our evaluations demonstrate Mamba-3's ability to advance the performance-efficiency Pareto frontier.
Hydra: Bidirectional State Space Models Through Generalized Matrix Mixers
Jul 13, 2024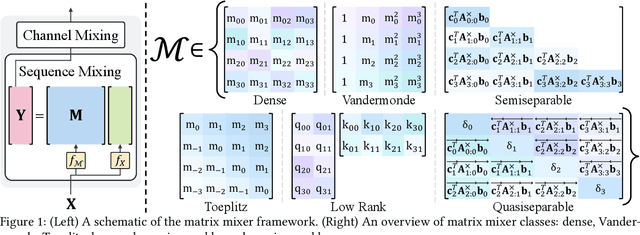
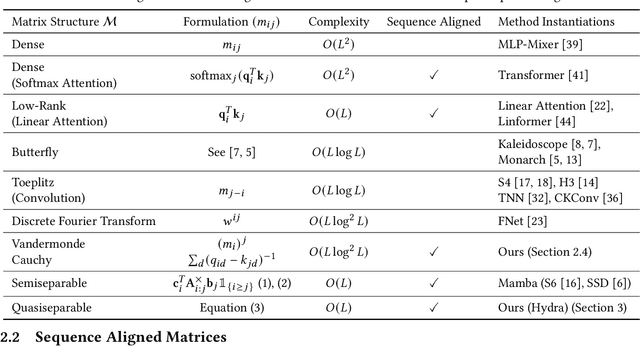
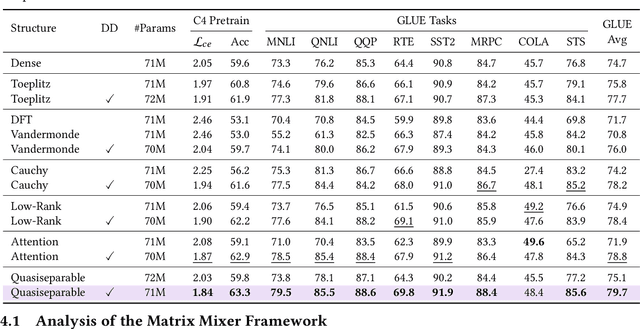
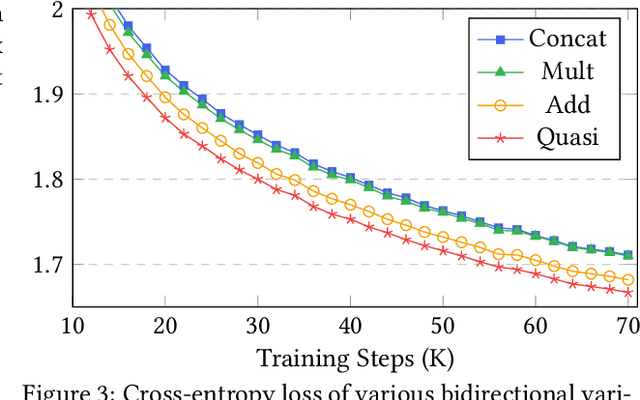
A wide array of sequence models are built on a framework modeled after Transformers, comprising alternating sequence mixer and channel mixer layers. This paper studies a unifying matrix mixer view of sequence mixers that can be conceptualized as a linear map on the input sequence. This framework encompasses a broad range of well-known sequence models, including the self-attention of Transformers as well as recent strong alternatives such as structured state space models (SSMs), and allows understanding downstream characteristics such as efficiency and expressivity through properties of their structured matrix class. We identify a key axis of matrix parameterizations termed sequence alignment, which increases the flexibility and performance of matrix mixers, providing insights into the strong performance of Transformers and recent SSMs such as Mamba. Furthermore, the matrix mixer framework offers a systematic approach to developing sequence mixers with desired properties, allowing us to develop several new sub-quadratic sequence models. In particular, we propose a natural bidirectional extension of the Mamba model (Hydra), parameterized as a quasiseparable matrix mixer, which demonstrates superior performance over other sequence models including Transformers on non-causal tasks. As a drop-in replacement for attention layers, Hydra outperforms BERT by 0.8 points on the GLUE benchmark and ViT by 2% Top-1 accuracy on ImageNet.
Role of Locality and Weight Sharing in Image-Based Tasks: A Sample Complexity Separation between CNNs, LCNs, and FCNs
Mar 23, 2024
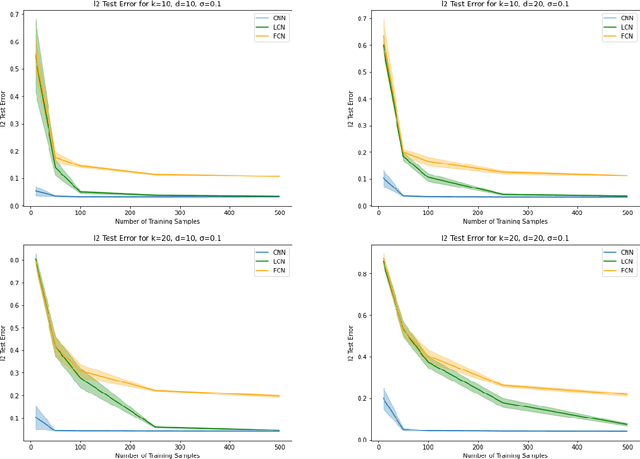
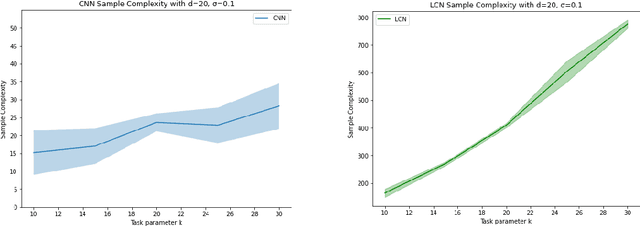
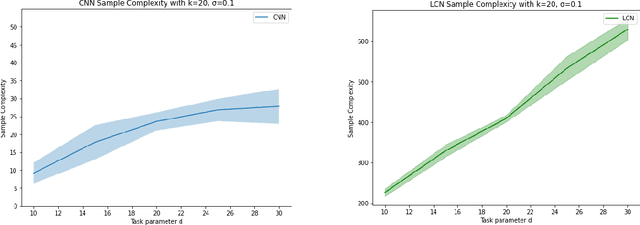
Vision tasks are characterized by the properties of locality and translation invariance. The superior performance of convolutional neural networks (CNNs) on these tasks is widely attributed to the inductive bias of locality and weight sharing baked into their architecture. Existing attempts to quantify the statistical benefits of these biases in CNNs over locally connected convolutional neural networks (LCNs) and fully connected neural networks (FCNs) fall into one of the following categories: either they disregard the optimizer and only provide uniform convergence upper bounds with no separating lower bounds, or they consider simplistic tasks that do not truly mirror the locality and translation invariance as found in real-world vision tasks. To address these deficiencies, we introduce the Dynamic Signal Distribution (DSD) classification task that models an image as consisting of $k$ patches, each of dimension $d$, and the label is determined by a $d$-sparse signal vector that can freely appear in any one of the $k$ patches. On this task, for any orthogonally equivariant algorithm like gradient descent, we prove that CNNs require $\tilde{O}(k+d)$ samples, whereas LCNs require $\Omega(kd)$ samples, establishing the statistical advantages of weight sharing in translation invariant tasks. Furthermore, LCNs need $\tilde{O}(k(k+d))$ samples, compared to $\Omega(k^2d)$ samples for FCNs, showcasing the benefits of locality in local tasks. Additionally, we develop information theoretic tools for analyzing randomized algorithms, which may be of interest for statistical research.
Sharpened Lazy Incremental Quasi-Newton Method
May 26, 2023We consider the finite sum minimization of $n$ strongly convex and smooth functions with Lipschitz continuous Hessians in $d$ dimensions. In many applications where such problems arise, including maximum likelihood estimation, empirical risk minimization, and unsupervised learning, the number of observations $n$ is large, and it becomes necessary to use incremental or stochastic algorithms whose per-iteration complexity is independent of $n$. Of these, the incremental/stochastic variants of the Newton method exhibit superlinear convergence, but incur a per-iteration complexity of $O(d^3)$, which may be prohibitive in large-scale settings. On the other hand, the incremental Quasi-Newton method incurs a per-iteration complexity of $O(d^2)$ but its superlinear convergence rate has only been characterized asymptotically. This work puts forth the Sharpened Lazy Incremental Quasi-Newton (SLIQN) method that achieves the best of both worlds: an explicit superlinear convergence rate with a per-iteration complexity of $O(d^2)$. Building upon the recently proposed Sharpened Quasi-Newton method, the proposed incremental variant incorporates a hybrid update strategy incorporating both classic and greedy BFGS updates. The proposed lazy update rule distributes the computational complexity between the iterations, so as to enable a per-iteration complexity of $O(d^2)$. Numerical tests demonstrate the superiority of SLIQN over all other incremental and stochastic Quasi-Newton variants.