 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Skill Gap in Recurrent Language Models: The Role of the Gather-and-Aggregate Mechanism
Apr 22, 2025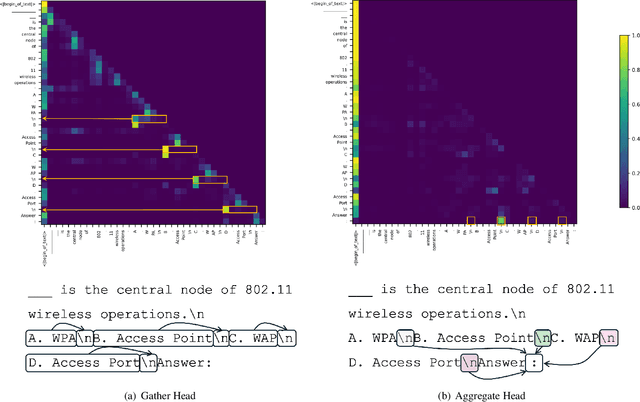



SSMs offer efficient processing of long sequences with fixed state sizes, but struggle with algorithmic tasks like retrieving past context. In this work, we examine how such in-context retrieval operates within Transformer- and SSM-based language models. We find that both architectures develop the same fundamental Gather-and-Aggregate (G&A) mechanism. A Gather Head first identifies and extracts relevant information from the context, which an Aggregate Head then integrates into a final representation. Across both model types, G&A concentrates in just a few heads, making them critical bottlenecks even for benchmarks that require a basic form of retrieval. For example, disabling a single Gather or Aggregate Head of a pruned Llama-3.1-8B degrades its ability to retrieve the correct answer letter in MMLU, reducing accuracy from 66% to 25%. This finding suggests that in-context retrieval can obscure the limited knowledge demands of certain tasks. Despite strong MMLU performance with retrieval intact, the pruned model fails on other knowledge tests. Similar G&A dependencies exist in GSM8K, BBH, and dialogue tasks. Given the significance of G&A in performance, we show that retrieval challenges in SSMs manifest in how they implement G&A, leading to smoother attention patterns rather than the sharp token transitions that effective G&A relies on. Thus, while a gap exists between Transformers and SSMs in implementing in-context retrieval, it is confined to a few heads, not the entire model. This insight suggests a unified explanation for performance differences between Transformers and SSMs while also highlighting ways to combine their strengths. For example, in pretrained hybrid models, attention components naturally take on the role of Aggregate Heads. Similarly, in a pretrained pure SSM, replacing a single G&A head with an attention-based variant significantly improves retrieval.
Thinking Slow, Fast: Scaling Inference Compute with Distilled Reasoners
Feb 27, 2025Recent advancements have demonstrated that the performance of large language models (LLMs) can be significantly enhanced by scaling computational resources at test time. A common strategy involves generating multiple Chain-of-Thought (CoT) trajectories and aggregating their outputs through various selection mechanisms. This raises a fundamental question: can models with lower complexity leverage their superior generation throughput to outperform similarly sized Transformers for a fixed computational budget? To address this question and overcome the lack of strong subquadratic reasoners, we distill pure and hybrid Mamba models from pretrained Transformers. Trained on only 8 billion tokens, our distilled models show strong performance and scaling on mathematical reasoning datasets while being much faster at inference for large batches and long sequences. Despite the zero-shot performance hit due to distillation, both pure and hybrid Mamba models can scale their coverage and accuracy performance past their Transformer teacher models under fixed time budgets, opening a new direction for scaling inference compute.
Llamba: Scaling Distilled Recurrent Models for Efficient Language Processing
Feb 23, 2025We introduce Llamba, a family of efficient recurrent language models distilled from Llama-3.x into the Mamba architecture. The series includes Llamba-1B, Llamba-3B, and Llamba-8B, which achieve higher inference throughput and handle significantly larger batch sizes than Transformer-based models while maintaining comparable benchmark performance. Furthermore, Llamba demonstrates the effectiveness of cross-architecture distillation using MOHAWK (Bick et al., 2024), achieving these results with less than 0.1% of the training data typically used for models of similar size. To take full advantage of their efficiency, we provide an optimized implementation of Llamba for resource-constrained devices such as smartphones and edge platforms, offering a practical and memory-efficient alternative to Transformers. Overall, Llamba improves the tradeoff between speed, memory efficiency, and performance, making high-quality language models more accessible.
Transformers to SSMs: Distilling Quadratic Knowledge to Subquadratic Models
Aug 19, 2024



Transformer architectures have become a dominant paradigm for domains like language modeling but suffer in many inference settings due to their quadratic-time self-attention. Recently proposed subquadratic architectures, such as Mamba, have shown promise, but have been pretrained with substantially less computational resources than the strongest Transformer models. In this work, we present a method that is able to distill a pretrained Transformer architecture into alternative architectures such as state space models (SSMs). The key idea to our approach is that we can view both Transformers and SSMs as applying different forms of mixing matrices over the token sequences. We can thus progressively distill the Transformer architecture by matching different degrees of granularity in the SSM: first matching the mixing matrices themselves, then the hidden units at each block, and finally the end-to-end predictions. Our method, called MOHAWK, is able to distill a Mamba-2 variant based on the Phi-1.5 architecture (Phi-Mamba) using only 3B tokens and a hybrid version (Hybrid Phi-Mamba) using 5B tokens. Despite using less than 1% of the training data typically used to train models from scratch, Phi-Mamba boasts substantially stronger performance compared to all past open-source non-Transformer models. MOHAWK allows models like SSMs to leverage computational resources invested in training Transformer-based architectures, highlighting a new avenue for building such models.