 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Transfer of a Physics Foundation Model from Simulation to Laboratory Turbulence
May 31, 2026Whether physics foundation models can be usefully deployed on laboratory experiments remains an open question for scientific machine learning (ML). We test this question on the Rayleigh-Taylor instability (RTI), a ubiquitous and demanding fluid instability seen from tabletop flows to supernova explosions, in which small perturbations at a density interface grow into chaotic, multiscale mixing as a lighter fluid accelerates into a heavier one. Standard ML models struggle with RTI, and despite over a century of theoretical, numerical, and experimental work, it carries an unresolved discrepancy between simulation and experiment: the late-time mixing growth rate, $α$, measured in most laboratory experiments ($\sim$ 0.06-0.07), is roughly three times the value from idealized direct numerical simulations (DNS, $\sim$ 0.02). The gap's origin remains debated. These properties make RTI a stringent test for a question that matters well beyond RTI: can foundation models trained only on simulations generalise to sparse, messy, and noisy laboratory settings? We finetune Walrus, a foundation model for continuum dynamics, on three or fewer DNS realizations and recover key RTI physics over long rollouts. Applied zero-shot to sliding-barrier laboratory data, the finetuned model leaves the DNS-like regime and enters the observed growth band, having never seen a single experimental sample. These results provide independent, data-driven evidence that initial conditions play a crucial role in the longstanding sim-experiment gap in $α$. The model also generalises zero-shot to stable stratification, a buoyancy regime absent from training, correctly slowing mixing-layer growth. Together, our results show that foundation models can generalise well beyond their training data, predicting laboratory behavior and unseen physical regimes, opening new ways to probe longstanding simulation-experiment gaps.
Protein Design with Agent Rosetta: A Case Study for Specialized Scientific Agents
Mar 16, 2026Large language models (LLMs) are capable of emulating reasoning and using tools, creating opportunities for autonomous agents that execute complex scientific tasks. Protein design provides a natural testbed: although machine learning (ML) methods achieve strong results, these are largely restricted to canonical amino acids and narrow objectives, leaving unfilled need for a generalist tool for broad design pipelines. We introduce Agent Rosetta, an LLM agent paired with a structured environment for operating Rosetta, the leading physics-based heteropolymer design software, capable of modeling non-canonical building blocks and geometries. Agent Rosetta iteratively refines designs to achieve user-defined objectives, combining LLM reasoning with Rosetta's generality. We evaluate Agent Rosetta on design with canonical amino acids, matching specialized models and expert baselines, and with non-canonical residues -- where ML approaches fail -- achieving comparable performance. Critically, prompt engineering alone often fails to generate Rosetta actions, demonstrating that environment design is essential for integrating LLM agents with specialized software. Our results show that properly designed environments enable LLM agents to make scientific software accessible while matching specialized tools and human experts.
Probabilistic Retrofitting of Learned Simulators
Mar 02, 2026Dominant approaches for modelling Partial Differential Equations (PDEs) rely on deterministic predictions, yet many physical systems of interest are inherently chaotic and uncertain. While training probabilistic models from scratch is possible, it is computationally expensive and fails to leverage the significant resources already invested in high-performing deterministic backbones. In this work, we adopt a training-efficient strategy to transform pre-trained deterministic models into probabilistic ones via retrofitting with a proper scoring rule: the Continuous Ranked Probability Score (CRPS). Crucially, this approach is architecture-agnostic: it applies the same adaptation mechanism across distinct model backbones with minimal code modifications. The method proves highly effective across different scales of pre-training: for models trained on single dynamical systems, we achieve 20-54% reductions in rollout CRPS and up to 30% improvements in variance-normalised RMSE (VRMSE) relative to compute-matched deterministic fine-tuning. We further validate our approach on a PDE foundation model, trained on multiple systems and retrofitted on the dataset of interest, to show that our probabilistic adaptation yields an improvement of up to 40% in CRPS and up to 15% in VRMSE compared to deterministic fine-tuning. Validated across diverse architectures and dynamics, our results show that probabilistic PDE modelling need not require retraining from scratch, but can be unlocked from existing deterministic backbones with modest additional training cost.
Walrus: A Cross-Domain Foundation Model for Continuum Dynamics
Nov 19, 2025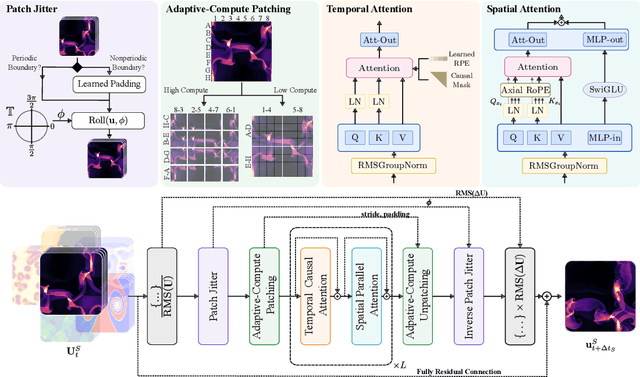


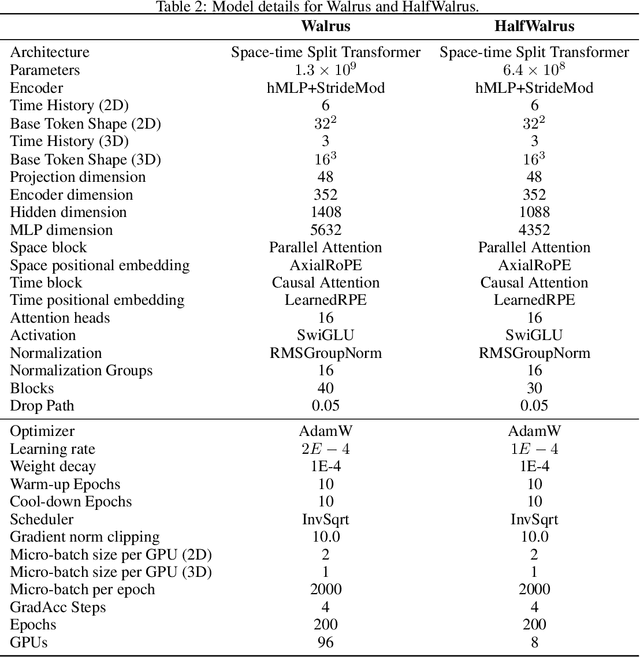
Foundation models have transformed machine learning for language and vision, but achieving comparable impact in physical simulation remains a challenge. Data heterogeneity and unstable long-term dynamics inhibit learning from sufficiently diverse dynamics, while varying resolutions and dimensionalities challenge efficient training on modern hardware. Through empirical and theoretical analysis, we incorporate new approaches to mitigate these obstacles, including a harmonic-analysis-based stabilization method, load-balanced distributed 2D and 3D training strategies, and compute-adaptive tokenization. Using these tools, we develop Walrus, a transformer-based foundation model developed primarily for fluid-like continuum dynamics. Walrus is pretrained on nineteen diverse scenarios spanning astrophysics, geoscience, rheology, plasma physics, acoustics, and classical fluids. Experiments show that Walrus outperforms prior foundation models on both short and long term prediction horizons on downstream tasks and across the breadth of pretraining data, while ablation studies confirm the value of our contributions to forecast stability, training throughput, and transfer performance over conventional approaches. Code and weights are released for community use.
CodePDE: An Inference Framework for LLM-driven PDE Solver Generation
May 13, 2025Partial differential equations (PDEs) are fundamental to modeling physical systems, yet solving them remains a complex challenge. Traditional numerical solvers rely on expert knowledge to implement and are computationally expensive, while neural-network-based solvers require large training datasets and often lack interpretability. In this work, we frame PDE solving as a code generation task and introduce CodePDE, the first inference framework for generating PDE solvers using large language models (LLMs). Leveraging advanced inference-time algorithms and scaling strategies, CodePDE unlocks critical capacities of LLM for PDE solving: reasoning, debugging, selfrefinement, and test-time scaling -- all without task-specific tuning. CodePDE achieves superhuman performance across a range of representative PDE problems. We also present a systematic empirical analysis of LLM generated solvers, analyzing their accuracy, efficiency, and numerical scheme choices. Our findings highlight the promise and the current limitations of LLMs in PDE solving, offering a new perspective on solver design and opportunities for future model development. Our code is available at https://github.com/LithiumDA/CodePDE.
Adapting Language Models via Token Translation
Nov 01, 2024Modern large language models use a fixed tokenizer to effectively compress text drawn from a source domain. However, applying the same tokenizer to a new target domain often leads to inferior compression, more costly inference, and reduced semantic alignment. To address this deficiency, we introduce Sparse Sinkhorn Token Translation (S2T2). S2T2 trains a tailored tokenizer for the target domain and learns to translate between target and source tokens, enabling more effective reuse of the pre-trained next-source-token predictor. In our experiments with finetuned English language models, S2T2 improves both the perplexity and the compression of out-of-domain protein sequences, outperforming direct finetuning with either the source or target tokenizer. In addition, we find that token translations learned for smaller, less expensive models can be directly transferred to larger, more powerful models to reap the benefits of S2T2 at lower cost.
Towards characterizing the value of edge embeddings in Graph Neural Networks
Oct 13, 2024Graph neural networks (GNNs) are the dominant approach to solving machine learning problems defined over graphs. Despite much theoretical and empirical work in recent years, our understanding of finer-grained aspects of architectural design for GNNs remains impoverished. In this paper, we consider the benefits of architectures that maintain and update edge embeddings. On the theoretical front, under a suitable computational abstraction for a layer in the model, as well as memory constraints on the embeddings, we show that there are natural tasks on graphical models for which architectures leveraging edge embeddings can be much shallower. Our techniques are inspired by results on time-space tradeoffs in theoretical computer science. Empirically, we show architectures that maintain edge embeddings almost always improve on their node-based counterparts -- frequently significantly so in topologies that have ``hub'' nodes.
On the Benefits of Memory for Modeling Time-Dependent PDEs
Sep 03, 2024Data-driven techniques have emerged as a promising alternative to traditional numerical methods for solving partial differential equations (PDEs). These techniques frequently offer a better trade-off between computational cost and accuracy for many PDE families of interest. For time-dependent PDEs, existing methodologies typically treat PDEs as Markovian systems, i.e., the evolution of the system only depends on the ``current state'', and not the past states. However, distortion of the input signals -- e.g., due to discretization or low-pass filtering -- can render the evolution of the distorted signals non-Markovian. In this work, motivated by the Mori-Zwanzig theory of model reduction, we investigate the impact of architectures with memory for modeling PDEs: that is, when past states are explicitly used to predict the future. We introduce Memory Neural Operator (MemNO), a network based on the recent SSM architectures and Fourier Neural Operator (FNO). We empirically demonstrate on a variety of PDE families of interest that when the input is given on a low-resolution grid, MemNO significantly outperforms the baselines without memory, achieving more than 6 times less error on unseen PDEs. Via a combination of theory and experiments, we show that the effect of memory is particularly significant when the solution of the PDE has high frequency Fourier components (e.g., low-viscosity fluid dynamics), and it also increases robustness to observation noise.
UPS: Towards Foundation Models for PDE Solving via Cross-Modal Adaptation
Mar 11, 2024



We introduce UPS (Unified PDE Solver), an effective and data-efficient approach to solve diverse spatiotemporal PDEs defined over various domains, dimensions, and resolutions. UPS unifies different PDEs into a consistent representation space and processes diverse collections of PDE data using a unified network architecture that combines LLMs with domain-specific neural operators. We train the network via a two-stage cross-modal adaptation process, leveraging ideas of modality alignment and multi-task learning. By adapting from pretrained LLMs and exploiting text-form meta information, we are able to use considerably fewer training samples than previous methods while obtaining strong empirical results. UPS outperforms existing baselines, often by a large margin, on a wide range of 1D and 2D datasets in PDEBench, achieving state-of-the-art results on 8 of 10 tasks considered. Meanwhile, it is capable of few-shot transfer to different PDE families, coefficients, and resolutions.
Deep Equilibrium Based Neural Operators for Steady-State PDEs
Nov 30, 2023



Data-driven machine learning approaches are being increasingly used to solve partial differential equations (PDEs). They have shown particularly striking successes when training an operator, which takes as input a PDE in some family, and outputs its solution. However, the architectural design space, especially given structural knowledge of the PDE family of interest, is still poorly understood. We seek to remedy this gap by studying the benefits of weight-tied neural network architectures for steady-state PDEs. To achieve this, we first demonstrate that the solution of most steady-state PDEs can be expressed as a fixed point of a non-linear operator. Motivated by this observation, we propose FNO-DEQ, a deep equilibrium variant of the FNO architecture that directly solves for the solution of a steady-state PDE as the infinite-depth fixed point of an implicit operator layer using a black-box root solver and differentiates analytically through this fixed point resulting in $\mathcal{O}(1)$ training memory. Our experiments indicate that FNO-DEQ-based architectures outperform FNO-based baselines with $4\times$ the number of parameters in predicting the solution to steady-state PDEs such as Darcy Flow and steady-state incompressible Navier-Stokes. Finally, we show FNO-DEQ is more robust when trained with datasets with more noisy observations than the FNO-based baselines, demonstrating the benefits of using appropriate inductive biases in architectural design for different neural network based PDE solvers. Further, we show a universal approximation result that demonstrates that FNO-DEQ can approximate the solution to any steady-state PDE that can be written as a fixed point equation.