 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Image Generation Using Scene Graphs
Paper and Code
May 09, 2019

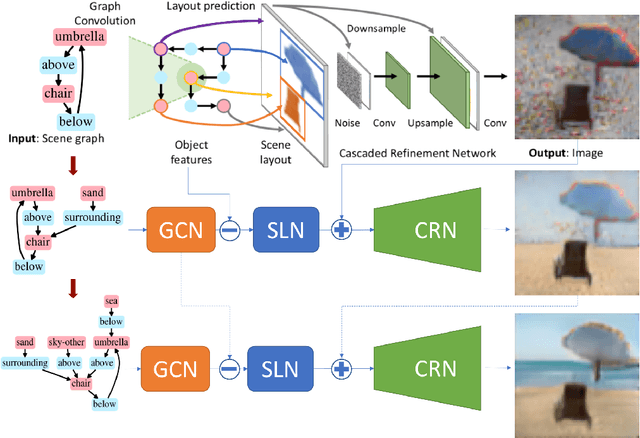

Recent years have witnessed some exciting developments in the domain of generating images from scene-based text descriptions. These approaches have primarily focused on generating images from a static text description and are limited to generating images in a single pass. They are unable to generate an image interactively based on an incrementally additive text description (something that is more intuitive and similar to the way we describe an image). We propose a method to generate an image incrementally based on a sequence of graphs of scene descriptions (scene-graphs). We propose a recurrent network architecture that preserves the image content generated in previous steps and modifies the cumulative image as per the newly provided scene information. Our model utilizes Graph Convolutional Networks (GCN) to cater to variable-sized scene graphs along with Generative Adversarial image translation networks to generate realistic multi-object images without needing any intermediate supervision during training. We experiment with Coco-Stuff dataset which has multi-object images along with annotations describing the visual scene and show that our model significantly outperforms other approaches on the same dataset in generating visually consistent images for incrementally growing scene graphs.