 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentive Semantic Video Generation using Captions
Paper and Code
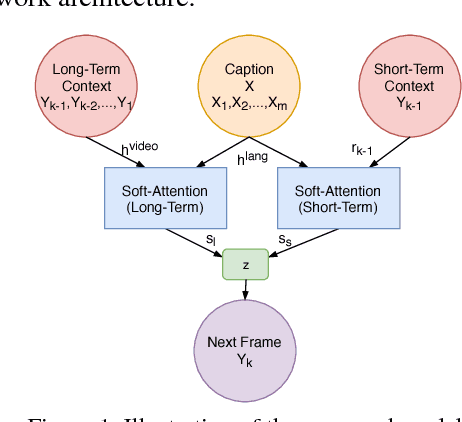
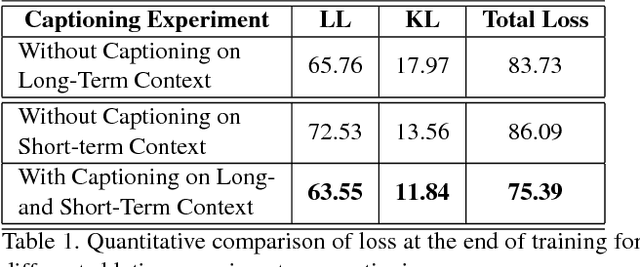
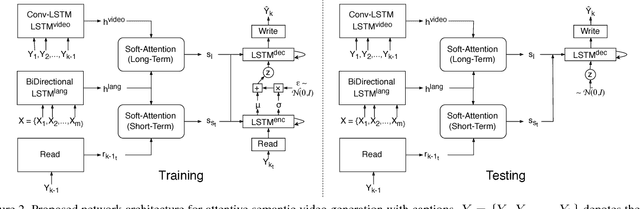

This paper proposes a network architecture to perform variable length semantic video generation using captions. We adopt a new perspective towards video generation where we allow the captions to be combined with the long-term and short-term dependencies between video frames and thus generate a video in an incremental manner. Our experiments demonstrate our network architecture's ability to distinguish between objects, actions and interactions in a video and combine them to generate videos for unseen captions. The network also exhibits the capability to perform spatio-temporal style transfer when asked to generate videos for a sequence of captions. We also show that the network's ability to learn a latent representation allows it generate videos in an unsupervised manner and perform other tasks such as action recognition. (Accepted in International Conference in Computer Vision (ICCV) 2017)