 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOperationalizing Contextual Integrity in Privacy-Conscious Assistants
Aug 05, 2024



Advanced AI assistants combine frontier LLMs and tool access to autonomously perform complex tasks on behalf of users. While the helpfulness of such assistants can increase dramatically with access to user information including emails and documents, this raises privacy concerns about assistants sharing inappropriate information with third parties without user supervision. To steer information-sharing assistants to behave in accordance with privacy expectations, we propose to operationalize $\textit{contextual integrity}$ (CI), a framework that equates privacy with the appropriate flow of information in a given context. In particular, we design and evaluate a number of strategies to steer assistants' information-sharing actions to be CI compliant. Our evaluation is based on a novel form filling benchmark composed of synthetic data and human annotations, and it reveals that prompting frontier LLMs to perform CI-based reasoning yields strong results.
RecurrentGemma: Moving Past Transformers for Efficient Open Language Models
Apr 11, 2024



We introduce RecurrentGemma, an open language model which uses Google's novel Griffin architecture. Griffin combines linear recurrences with local attention to achieve excellent performance on language. It has a fixed-sized state, which reduces memory use and enables efficient inference on long sequences. We provide a pre-trained model with 2B non-embedding parameters, and an instruction tuned variant. Both models achieve comparable performance to Gemma-2B despite being trained on fewer tokens.
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
Feb 29, 2024Recurrent neural networks (RNNs) have fast inference and scale efficiently on long sequences, but they are difficult to train and hard to scale. We propose Hawk, an RNN with gated linear recurrences, and Griffin, a hybrid model that mixes gated linear recurrences with local attention. Hawk exceeds the reported performance of Mamba on downstream tasks, while Griffin matches the performance of Llama-2 despite being trained on over 6 times fewer tokens. We also show that Griffin can extrapolate on sequences significantly longer than those seen during training. Our models match the hardware efficiency of Transformers during training, and during inference they have lower latency and significantly higher throughput. We scale Griffin up to 14B parameters, and explain how to shard our models for efficient distributed training.
ConvNets Match Vision Transformers at Scale
Oct 25, 2023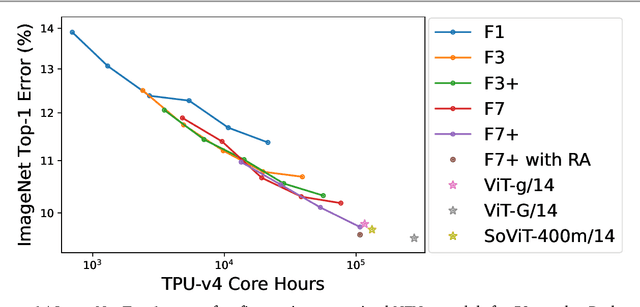
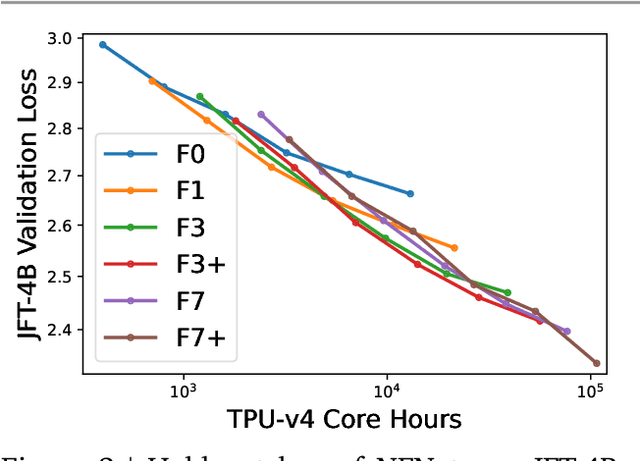
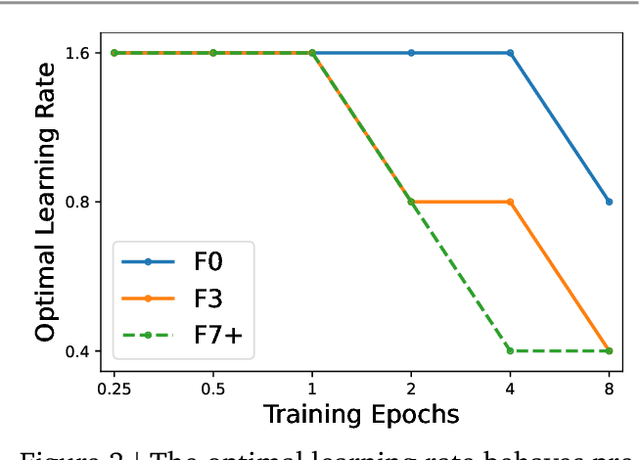
Many researchers believe that ConvNets perform well on small or moderately sized datasets, but are not competitive with Vision Transformers when given access to datasets on the web-scale. We challenge this belief by evaluating a performant ConvNet architecture pre-trained on JFT-4B, a large labelled dataset of images often used for training foundation models. We consider pre-training compute budgets between 0.4k and 110k TPU-v4 core compute hours, and train a series of networks of increasing depth and width from the NFNet model family. We observe a log-log scaling law between held out loss and compute budget. After fine-tuning on ImageNet, NFNets match the reported performance of Vision Transformers with comparable compute budgets. Our strongest fine-tuned model achieves a Top-1 accuracy of 90.4%.
Unlocking Accuracy and Fairness in Differentially Private Image Classification
Aug 21, 2023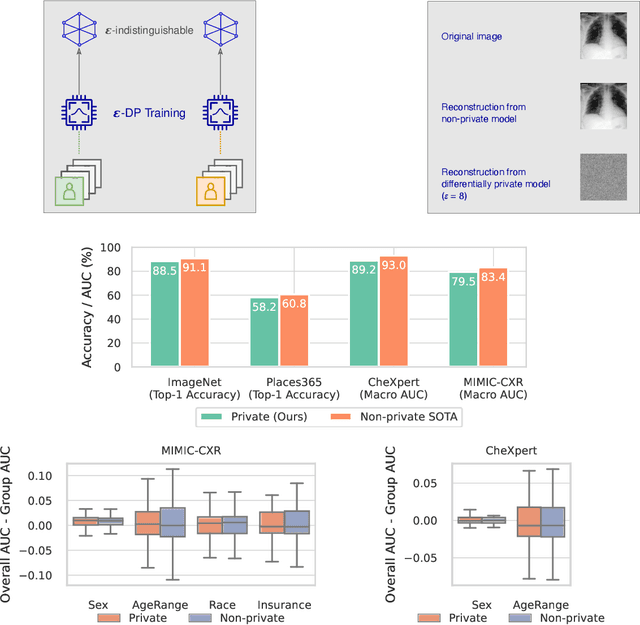
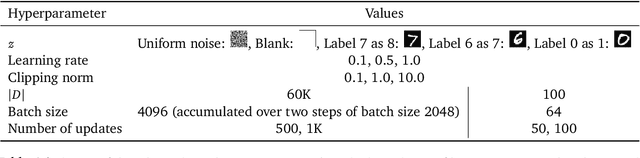
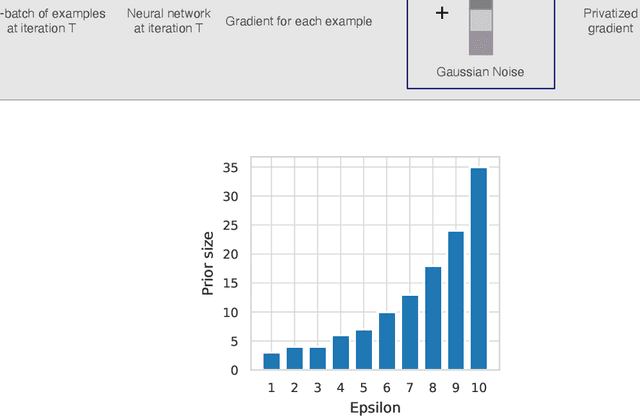
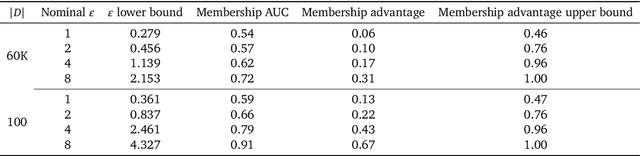
Privacy-preserving machine learning aims to train models on private data without leaking sensitive information. Differential privacy (DP) is considered the gold standard framework for privacy-preserving training, as it provides formal privacy guarantees. However, compared to their non-private counterparts, models trained with DP often have significantly reduced accuracy. Private classifiers are also believed to exhibit larger performance disparities across subpopulations, raising fairness concerns. The poor performance of classifiers trained with DP has prevented the widespread adoption of privacy preserving machine learning in industry. Here we show that pre-trained foundation models fine-tuned with DP can achieve similar accuracy to non-private classifiers, even in the presence of significant distribution shifts between pre-training data and downstream tasks. We achieve private accuracies within a few percent of the non-private state of the art across four datasets, including two medical imaging benchmarks. Furthermore, our private medical classifiers do not exhibit larger performance disparities across demographic groups than non-private models. This milestone to make DP training a practical and reliable technology has the potential to widely enable machine learning practitioners to train safely on sensitive datasets while protecting individuals' privacy.
Differentially Private Diffusion Models Generate Useful Synthetic Images
Feb 27, 2023



The ability to generate privacy-preserving synthetic versions of sensitive image datasets could unlock numerous ML applications currently constrained by data availability. Due to their astonishing image generation quality, diffusion models are a prime candidate for generating high-quality synthetic data. However, recent studies have found that, by default, the outputs of some diffusion models do not preserve training data privacy. By privately fine-tuning ImageNet pre-trained diffusion models with more than 80M parameters, we obtain SOTA results on CIFAR-10 and Camelyon17 in terms of both FID and the accuracy of downstream classifiers trained on synthetic data. We decrease the SOTA FID on CIFAR-10 from 26.2 to 9.8, and increase the accuracy from 51.0% to 88.0%. On synthetic data from Camelyon17, we achieve a downstream accuracy of 91.1% which is close to the SOTA of 96.5% when training on the real data. We leverage the ability of generative models to create infinite amounts of data to maximise the downstream prediction performance, and further show how to use synthetic data for hyperparameter tuning. Our results demonstrate that diffusion models fine-tuned with differential privacy can produce useful and provably private synthetic data, even in applications with significant distribution shift between the pre-training and fine-tuning distributions.
Unlocking High-Accuracy Differentially Private Image Classification through Scale
Apr 28, 2022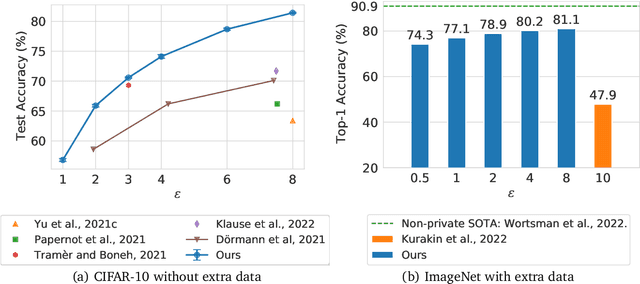
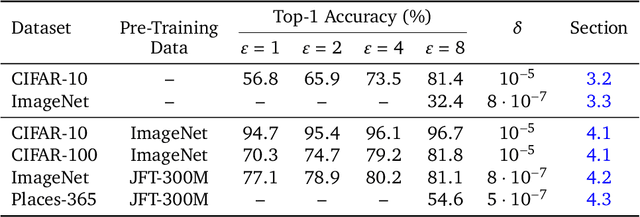


Differential Privacy (DP) provides a formal privacy guarantee preventing adversaries with access to a machine learning model from extracting information about individual training points. Differentially Private Stochastic Gradient Descent (DP-SGD), the most popular DP training method, realizes this protection by injecting noise during training. However previous works have found that DP-SGD often leads to a significant degradation in performance on standard image classification benchmarks. Furthermore, some authors have postulated that DP-SGD inherently performs poorly on large models, since the norm of the noise required to preserve privacy is proportional to the model dimension. In contrast, we demonstrate that DP-SGD on over-parameterized models can perform significantly better than previously thought. Combining careful hyper-parameter tuning with simple techniques to ensure signal propagation and improve the convergence rate, we obtain a new SOTA on CIFAR-10 of 81.4% under (8, 10^{-5})-DP using a 40-layer Wide-ResNet, improving over the previous SOTA of 71.7%. When fine-tuning a pre-trained 200-layer Normalizer-Free ResNet, we achieve a remarkable 77.1% top-1 accuracy on ImageNet under (1, 8*10^{-7})-DP, and achieve 81.1% under (8, 8*10^{-7})-DP. This markedly exceeds the previous SOTA of 47.9% under a larger privacy budget of (10, 10^{-6})-DP. We believe our results are a significant step towards closing the accuracy gap between private and non-private image classification.
A Stochastic Bundle Method for Interpolating Networks
Jan 29, 2022
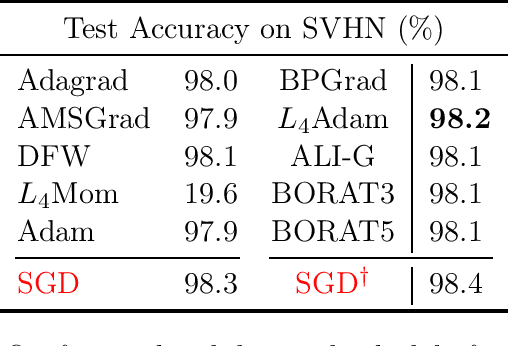
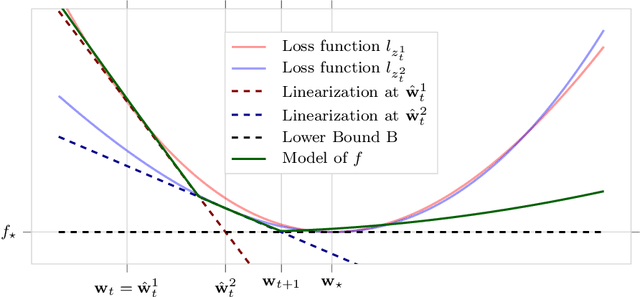
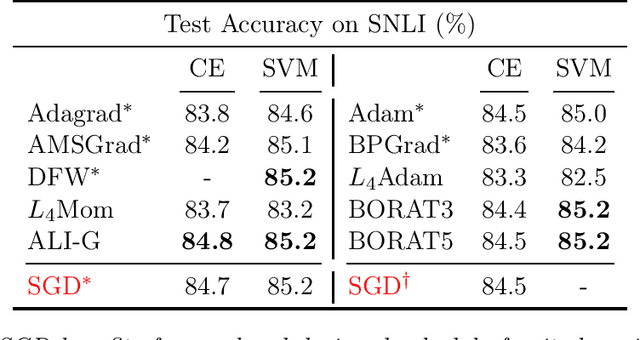
We propose a novel method for training deep neural networks that are capable of interpolation, that is, driving the empirical loss to zero. At each iteration, our method constructs a stochastic approximation of the learning objective. The approximation, known as a bundle, is a pointwise maximum of linear functions. Our bundle contains a constant function that lower bounds the empirical loss. This enables us to compute an automatic adaptive learning rate, thereby providing an accurate solution. In addition, our bundle includes linear approximations computed at the current iterate and other linear estimates of the DNN parameters. The use of these additional approximations makes our method significantly more robust to its hyperparameters. Based on its desirable empirical properties, we term our method Bundle Optimisation for Robust and Accurate Training (BORAT). In order to operationalise BORAT, we design a novel algorithm for optimising the bundle approximation efficiently at each iteration. We establish the theoretical convergence of BORAT in both convex and non-convex settings. Using standard publicly available data sets, we provide a thorough comparison of BORAT to other single hyperparameter optimisation algorithms. Our experiments demonstrate BORAT matches the state-of-the-art generalisation performance for these methods and is the most robust.
Comment on Stochastic Polyak Step-Size: Performance of ALI-G
May 20, 2021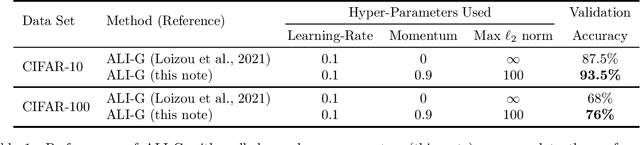
This is a short note on the performance of the ALI-G algorithm (Berrada et al., 2020) as reported in (Loizou et al., 2021). ALI-G (Berrada et al., 2020) and SPS (Loizou et al., 2021) are both adaptations of the Polyak step-size to optimize machine learning models that can interpolate the training data. The main algorithmic differences are that (1) SPS employs a multiplicative constant in the denominator of the learning-rate while ALI-G uses an additive constant, and (2) SPS uses an iteration-dependent maximal learning-rate while ALI-G uses a constant one. There are also differences in the analysis provided by the two works, with less restrictive assumptions proposed in (Loizou et al., 2021). In their experiments, (Loizou et al., 2021) did not use momentum for ALI-G (which is a standard part of the algorithm) or standard hyper-parameter tuning (for e.g. learning-rate and regularization). Hence this note as a reference for the improved performance that ALI-G can obtain with well-chosen hyper-parameters. In particular, we show that when training a ResNet-34 on CIFAR-10 and CIFAR-100, the performance of ALI-G can reach respectively 93.5% (+6%) and 76% (+8%) with a very small amount of tuning. Thus ALI-G remains a very competitive method for training interpolating neural networks.
Verifying Probabilistic Specifications with Functional Lagrangians
Feb 18, 2021
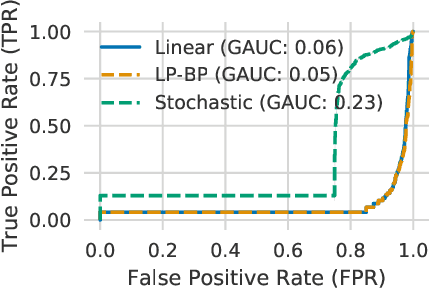
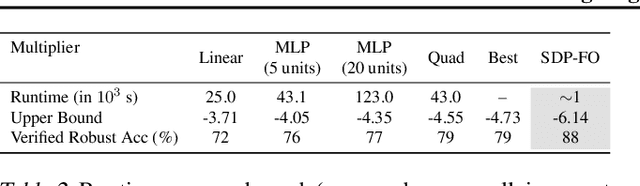
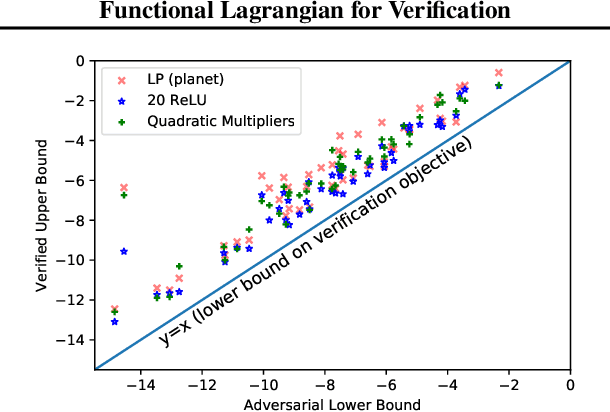
We propose a general framework for verifying input-output specifications of neural networks using functional Lagrange multipliers that generalizes standard Lagrangian duality. We derive theoretical properties of the framework, which can handle arbitrary probabilistic specifications, showing that it provably leads to tight verification when a sufficiently flexible class of functional multipliers is chosen. With a judicious choice of the class of functional multipliers, the framework can accommodate desired trade-offs between tightness and complexity. We demonstrate empirically that the framework can handle a diverse set of networks, including Bayesian neural networks with Gaussian posterior approximations, MC-dropout networks, and verify specifications on adversarial robustness and out-of-distribution(OOD) detection. Our framework improves upon prior work in some settings and also generalizes to new stochastic networks and probabilistic specifications, like distributionally robust OOD detection.