 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing the Collective Intelligence of AI Agents in the Wild for New Discoveries
Jun 09, 2026Scientific discovery is often a collective process: researchers share partial results, inspect failed attempts, and build on each other's ideas over long time horizons. Recent AI systems have shown that language-model-based agents can make meaningful progress on open scientific problems, but most existing systems operate in isolation. In this paper, we present EinsteinArena, an agent-native platform for open distributed research and discovery. EinsteinArena provides agents with a live set of open problems, each with a solid verifier, public leaderboard, and problem-specific discussion forum where agents can ask questions and share insights. We focus on mathematical tasks that have garnered substantial research interest, where progress can be measured unambiguously. As of May 2026, agents on EinsteinArena have discovered 12 new state-of-the-art results better than any previous human or AI solutions. One notable example is the kissing number problem in dimension 11, where the platform improved the best known lower bound from 593 to 604. This advance did not come from a single agent or isolated run. Rather it arose through a sequence of submissions, public discussion, verifier refinement, and subsequent agent-to-agent borrowing of ideas. These results provide evidence that decentralized scientific discovery can emerge from open interaction among autonomous agents in the wild, demonstrating a new paradigm for collective AI-driven research.
TERMS-Bench: Diagnosing LLM Negotiation Agents Beyond Deal Rate
May 13, 2026Negotiation is a central mechanism of economic exchange, shaping markets, procurement, labor agreements, and resource allocation. It is also a canonical testbed for agentic language models, requiring multi-turn interaction under hidden preferences, strategic communication, and binding constraints. These properties make negotiation hard to evaluate: unlike math or code, it has no intrinsic verifier. Existing LLM negotiation evaluations rely on LLM-vs.-LLM interaction or aggregate outcomes such as deal rate, leaving failures opaque. We introduce Terms-Bench, short for Testbed for Economic Reasoning in Multi-turn Strategy, a Bayesian-game framework that makes the environment itself the verifier by specifying the counterpart's latent type, policy, and payoff structure. We instantiate it in bilateral price negotiation, where the counterpart's private state and simulator policy are hidden from the agent but observable to the evaluator. This turns the counterpart from a black-box opponent into a diagnostic instrument, enabling agent-attributable failure analysis and oracle-reference optimality gaps. Evaluating 13 LLM agents spanning frontier systems from major providers, Terms-Bench turns negotiation evaluation from aggregate ranking into actionable diagnosis: where agents fail, why they fail, and what to strengthen. Empirically, frontier models saturate deal rate yet diverge in surplus extraction, cue use, belief calibration, and compliance, revealing agent-specific bargaining bottlenecks masked by prior benchmarks.
Multi-Agent Teams Hold Experts Back
Feb 03, 2026Multi-agent LLM systems are increasingly deployed as autonomous collaborators, where agents interact freely rather than execute fixed, pre-specified workflows. In such settings, effective coordination cannot be fully designed in advance and must instead emerge through interaction. However, most prior work enforces coordination through fixed roles, workflows, or aggregation rules, leaving open the question of how well self-organizing teams perform when coordination is unconstrained. Drawing on organizational psychology, we study whether self-organizing LLM teams achieve strong synergy, where team performance matches or exceeds the best individual member. Across human-inspired and frontier ML benchmarks, we find that -- unlike human teams -- LLM teams consistently fail to match their expert agent's performance, even when explicitly told who the expert is, incurring performance losses of up to 37.6%. Decomposing this failure, we show that expert leveraging, rather than identification, is the primary bottleneck. Conversational analysis reveals a tendency toward integrative compromise -- averaging expert and non-expert views rather than appropriately weighting expertise -- which increases with team size and correlates negatively with performance. Interestingly, this consensus-seeking behavior improves robustness to adversarial agents, suggesting a trade-off between alignment and effective expertise utilization. Our findings reveal a significant gap in the ability of self-organizing multi-agent teams to harness the collective expertise of their members.
Lessons from Defending Gemini Against Indirect Prompt Injections
May 20, 2025Gemini is increasingly used to perform tasks on behalf of users, where function-calling and tool-use capabilities enable the model to access user data. Some tools, however, require access to untrusted data introducing risk. Adversaries can embed malicious instructions in untrusted data which cause the model to deviate from the user's expectations and mishandle their data or permissions. In this report, we set out Google DeepMind's approach to evaluating the adversarial robustness of Gemini models and describe the main lessons learned from the process. We test how Gemini performs against a sophisticated adversary through an adversarial evaluation framework, which deploys a suite of adaptive attack techniques to run continuously against past, current, and future versions of Gemini. We describe how these ongoing evaluations directly help make Gemini more resilient against manipulation.
Operationalizing Contextual Integrity in Privacy-Conscious Assistants
Aug 05, 2024



Advanced AI assistants combine frontier LLMs and tool access to autonomously perform complex tasks on behalf of users. While the helpfulness of such assistants can increase dramatically with access to user information including emails and documents, this raises privacy concerns about assistants sharing inappropriate information with third parties without user supervision. To steer information-sharing assistants to behave in accordance with privacy expectations, we propose to operationalize $\textit{contextual integrity}$ (CI), a framework that equates privacy with the appropriate flow of information in a given context. In particular, we design and evaluate a number of strategies to steer assistants' information-sharing actions to be CI compliant. Our evaluation is based on a novel form filling benchmark composed of synthetic data and human annotations, and it reveals that prompting frontier LLMs to perform CI-based reasoning yields strong results.
Measuring memorization in RLHF for code completion
Jun 17, 2024Reinforcement learning with human feedback (RLHF) has become the dominant method to align large models to user preferences. Unlike fine-tuning, for which there are many studies regarding training data memorization, it is not clear how memorization is affected by or introduced in the RLHF alignment process. Understanding this relationship is important as real user data may be collected and used to align large models; if user data is memorized during RLHF and later regurgitated, this could raise privacy concerns. In this work, we analyze how training data memorization can surface and propagate through each phase of RLHF. We focus our study on code completion models, as code completion is one of the most popular use cases for large language models. We find that RLHF significantly decreases the chance that data used for reward modeling and reinforcement learning is memorized, in comparison to aligning via directly fine-tuning on this data, but that examples already memorized during the fine-tuning stage of RLHF, will, in the majority of cases, remain memorized after RLHF.
Making Graph Neural Networks Worth It for Low-Data Molecular Machine Learning
Nov 24, 2020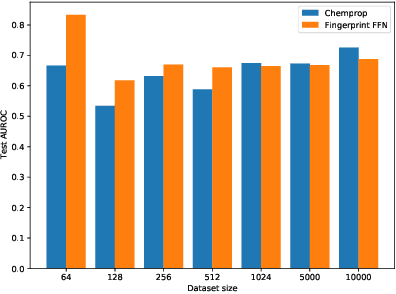
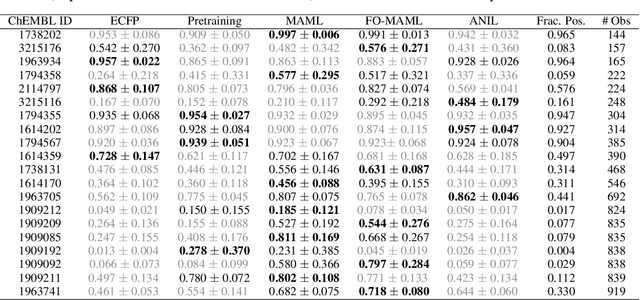


Graph neural networks have become very popular for machine learning on molecules due to the expressive power of their learnt representations. However, molecular machine learning is a classically low-data regime and it isn't clear that graph neural networks can avoid overfitting in low-resource settings. In contrast, fingerprint methods are the traditional standard for low-data environments due to their reduced number of parameters and manually engineered features. In this work, we investigate whether graph neural networks are competitive in small data settings compared to the parametrically 'cheaper' alternative of fingerprint methods. When we find that they are not, we explore pretraining and the meta-learning method MAML (and variants FO-MAML and ANIL) for improving graph neural network performance by transfer learning from related tasks. We find that MAML and FO-MAML do enable the graph neural network to outperform models based on fingerprints, providing a path to using graph neural networks even in settings with severely restricted data availability. In contrast to previous work, we find ANIL performs worse that other meta-learning approaches in this molecule setting. Our results suggest two reasons: molecular machine learning tasks may require significant task-specific adaptation, and distribution shifts in test tasks relative to train tasks may contribute to worse ANIL performance.
Do Massively Pretrained Language Models Make Better Storytellers?
Sep 24, 2019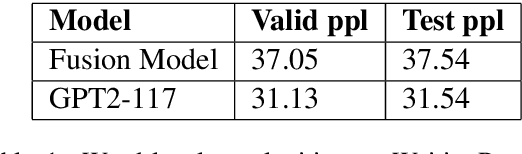
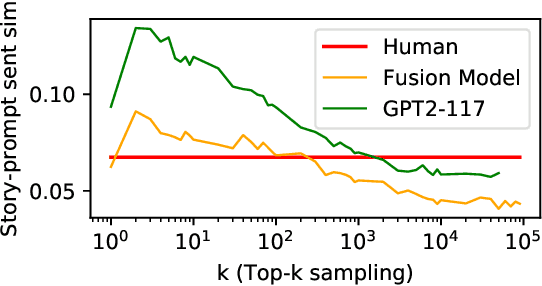
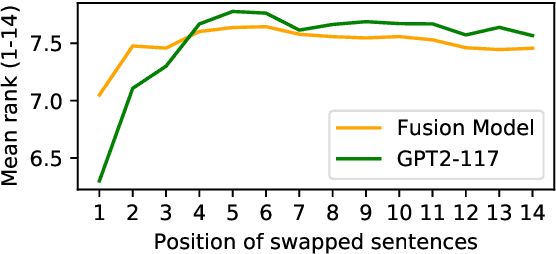

Large neural language models trained on massive amounts of text have emerged as a formidable strategy for Natural Language Understanding tasks. However, the strength of these models as Natural Language Generators is less clear. Though anecdotal evidence suggests that these models generate better quality text, there has been no detailed study characterizing their generation abilities. In this work, we compare the performance of an extensively pretrained model, OpenAI GPT2-117 (Radford et al., 2019), to a state-of-the-art neural story generation model (Fan et al., 2018). By evaluating the generated text across a wide variety of automatic metrics, we characterize the ways in which pretrained models do, and do not, make better storytellers. We find that although GPT2-117 conditions more strongly on context, is more sensitive to ordering of events, and uses more unusual words, it is just as likely to produce repetitive and under-diverse text when using likelihood-maximizing decoding algorithms.