 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlbedo: An Albedo and Shading Aerial Dataset for Large-Scale Outdoor Environments
Feb 24, 2026Intrinsic image decomposition (IID) of outdoor scenes is crucial for relighting, editing, and understanding large-scale environments, but progress has been limited by the lack of real-world datasets with reliable albedo and shading supervision. We introduce Olbedo, a large-scale aerial dataset for outdoor albedo--shading decomposition in the wild. Olbedo contains 5,664 UAV images captured across four landscape types, multiple years, and diverse illumination conditions. Each view is accompanied by multi-view consistent albedo and shading maps, metric depth, surface normals, sun and sky shading components, camera poses, and, for recent flights, measured HDR sky domes. These annotations are derived from an inverse-rendering refinement pipeline over multi-view stereo reconstructions and calibrated sky illumination, together with per-pixel confidence masks. We demonstrate that Olbedo enables state-of-the-art diffusion-based IID models, originally trained on synthetic indoor data, to generalize to real outdoor imagery: fine-tuning on Olbedo significantly improves single-view outdoor albedo prediction on the MatrixCity benchmark. We further illustrate applications of Olbedo-trained models to multi-view consistent relighting of 3D assets, material editing, and scene change analysis for urban digital twins. We release the dataset, baseline models, and an evaluation protocol to support future research in outdoor intrinsic decomposition and illumination-aware aerial vision.
Reconfigurable Tendon-Driven Robots: Eliminating Inter-segmental Coupling via Independently Lockable Joints
Jul 23, 2025



With a slender redundant body, the tendon-driven robot (TDR) has a large workspace and great maneuverability while working in complex environments. TDR comprises multiple independently controlled robot segments, each with a set of driving tendons. While increasing the number of robot segments enhances dexterity and expands the workspace, this structural expansion also introduces intensified inter-segmental coupling. Therefore, achieving precise TDR control requires more complex models and additional motors. This paper presents a reconfigurable tendon-driven robot (RTR) equipped with innovative lockable joints. Each joint's state (locked/free) can be individually controlled through a pair of antagonistic tendons, and its structure eliminates the need for a continuous power supply to maintain the state. Operators can selectively actuate the targeted robot segments, and this scheme fundamentally eliminates the inter-segmental coupling, thereby avoiding the requirement for complex coordinated control between segments. The workspace of RTR has been simulated and compared with traditional TDRs' workspace, and RTR's advantages are further revealed. The kinematics and statics models of the RTR have been derived and validation experiments have been conducted. Demonstrations have been performed using a seven-joint RTR prototype to show its reconfigurability and moving ability in complex environments with an actuator pack comprising only six motors.
Synthetic Data Matters: Re-training with Geo-typical Synthetic Labels for Building Detection
Jul 22, 2025Deep learning has significantly advanced building segmentation in remote sensing, yet models struggle to generalize on data of diverse geographic regions due to variations in city layouts and the distribution of building types, sizes and locations. However, the amount of time-consuming annotated data for capturing worldwide diversity may never catch up with the demands of increasingly data-hungry models. Thus, we propose a novel approach: re-training models at test time using synthetic data tailored to the target region's city layout. This method generates geo-typical synthetic data that closely replicates the urban structure of a target area by leveraging geospatial data such as street network from OpenStreetMap. Using procedural modeling and physics-based rendering, very high-resolution synthetic images are created, incorporating domain randomization in building shapes, materials, and environmental illumination. This enables the generation of virtually unlimited training samples that maintain the essential characteristics of the target environment. To overcome synthetic-to-real domain gaps, our approach integrates geo-typical data into an adversarial domain adaptation framework for building segmentation. Experiments demonstrate significant performance enhancements, with median improvements of up to 12%, depending on the domain gap. This scalable and cost-effective method blends partial geographic knowledge with synthetic imagery, providing a promising solution to the "model collapse" issue in purely synthetic datasets. It offers a practical pathway to improving generalization in remote sensing building segmentation without extensive real-world annotations.
Lessons from Defending Gemini Against Indirect Prompt Injections
May 20, 2025Gemini is increasingly used to perform tasks on behalf of users, where function-calling and tool-use capabilities enable the model to access user data. Some tools, however, require access to untrusted data introducing risk. Adversaries can embed malicious instructions in untrusted data which cause the model to deviate from the user's expectations and mishandle their data or permissions. In this report, we set out Google DeepMind's approach to evaluating the adversarial robustness of Gemini models and describe the main lessons learned from the process. We test how Gemini performs against a sophisticated adversary through an adversarial evaluation framework, which deploys a suite of adaptive attack techniques to run continuously against past, current, and future versions of Gemini. We describe how these ongoing evaluations directly help make Gemini more resilient against manipulation.
ParetoRAG: Leveraging Sentence-Context Attention for Robust and Efficient Retrieval-Augmented Generation
Feb 12, 2025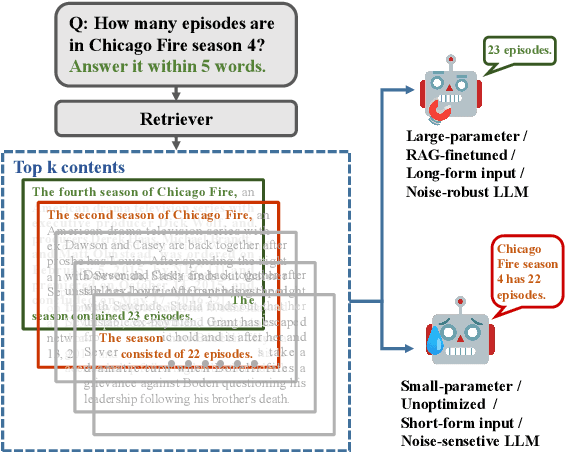



While Retrieval-Augmented Generation (RAG) systems enhance Large Language Models (LLMs) by incorporating external knowledge, they still face persistent challenges in retrieval inefficiency and the inability of LLMs to filter out irrelevant information. We present ParetoRAG, an unsupervised framework that optimizes RAG systems through sentence-level refinement guided by the Pareto principle. By decomposing paragraphs into sentences and dynamically re-weighting core content while preserving contextual coherence, ParetoRAG achieves dual improvements in both retrieval precision and generation quality without requiring additional training or API resources. This framework has been empirically validated across various datasets, LLMs, and retrievers.
Deep Learning Meets Satellite Images -- An Evaluation on Handcrafted and Learning-based Features for Multi-date Satellite Stereo Images
Sep 04, 2024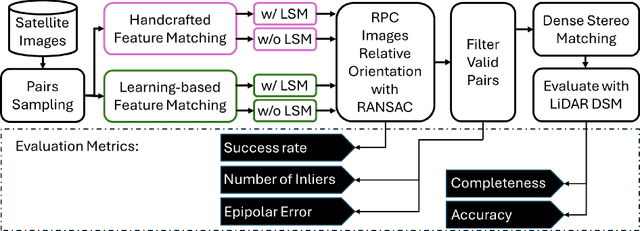
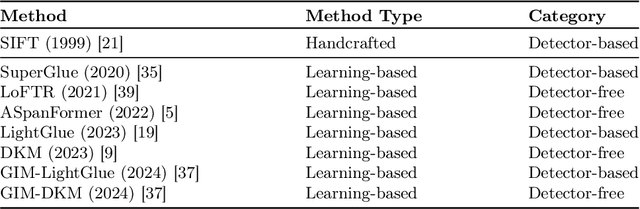
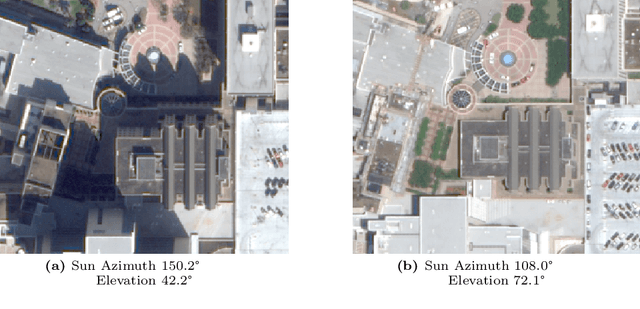

A critical step in the digital surface models(DSM) generation is feature matching. Off-track (or multi-date) satellite stereo images, in particular, can challenge the performance of feature matching due to spectral distortions between images, long baseline, and wide intersection angles. Feature matching methods have evolved over the years from handcrafted methods (e.g., SIFT) to learning-based methods (e.g., SuperPoint and SuperGlue). In this paper, we compare the performance of different features, also known as feature extraction and matching methods, applied to satellite imagery. A wide range of stereo pairs(~500) covering two separate study sites are used. SIFT, as a widely used classic feature extraction and matching algorithm, is compared with seven deep-learning matching methods: SuperGlue, LightGlue, LoFTR, ASpanFormer, DKM, GIM-LightGlue, and GIM-DKM. Results demonstrate that traditional matching methods are still competitive in this age of deep learning, although for particular scenarios learning-based methods are very promising.
A General Albedo Recovery Approach for Aerial Photogrammetric Images through Inverse Rendering
Sep 04, 2024



Modeling outdoor scenes for the synthetic 3D environment requires the recovery of reflectance/albedo information from raw images, which is an ill-posed problem due to the complicated unmodeled physics in this process (e.g., indirect lighting, volume scattering, specular reflection). The problem remains unsolved in a practical context. The recovered albedo can facilitate model relighting and shading, which can further enhance the realism of rendered models and the applications of digital twins. Typically, photogrammetric 3D models simply take the source images as texture materials, which inherently embed unwanted lighting artifacts (at the time of capture) into the texture. Therefore, these polluted textures are suboptimal for a synthetic environment to enable realistic rendering. In addition, these embedded environmental lightings further bring challenges to photo-consistencies across different images that cause image-matching uncertainties. This paper presents a general image formation model for albedo recovery from typical aerial photogrammetric images under natural illuminations and derives the inverse model to resolve the albedo information through inverse rendering intrinsic image decomposition. Our approach builds on the fact that both the sun illumination and scene geometry are estimable in aerial photogrammetry, thus they can provide direct inputs for this ill-posed problem. This physics-based approach does not require additional input other than data acquired through the typical drone-based photogrammetric collection and was shown to favorably outperform existing approaches. We also demonstrate that the recovered albedo image can in turn improve typical image processing tasks in photogrammetry such as feature and dense matching, edge, and line extraction.
EAR: Edge-Aware Reconstruction of 3-D vertebrae structures from bi-planar X-ray images
Jul 30, 2024



X-ray images ease the diagnosis and treatment process due to their rapid imaging speed and high resolution. However, due to the projection process of X-ray imaging, much spatial information has been lost. To accurately provide efficient spinal morphological and structural information, reconstructing the 3-D structures of the spine from the 2-D X-ray images is essential. It is challenging for current reconstruction methods to preserve the edge information and local shapes of the asymmetrical vertebrae structures. In this study, we propose a new Edge-Aware Reconstruction network (EAR) to focus on the performance improvement of the edge information and vertebrae shapes. In our network, by using the auto-encoder architecture as the backbone, the edge attention module and frequency enhancement module are proposed to strengthen the perception of the edge reconstruction. Meanwhile, we also combine four loss terms, including reconstruction loss, edge loss, frequency loss and projection loss. The proposed method is evaluated using three publicly accessible datasets and compared with four state-of-the-art models. The proposed method is superior to other methods and achieves 25.32%, 15.32%, 86.44%, 80.13%, 23.7612 and 0.3014 with regard to MSE, MAE, Dice, SSIM, PSNR and frequency distance. Due to the end-to-end and accurate reconstruction process, EAR can provide sufficient 3-D spatial information and precise preoperative surgical planning guidance.
Multi-view X-ray Image Synthesis with Multiple Domain Disentanglement from CT Scans
Apr 18, 2024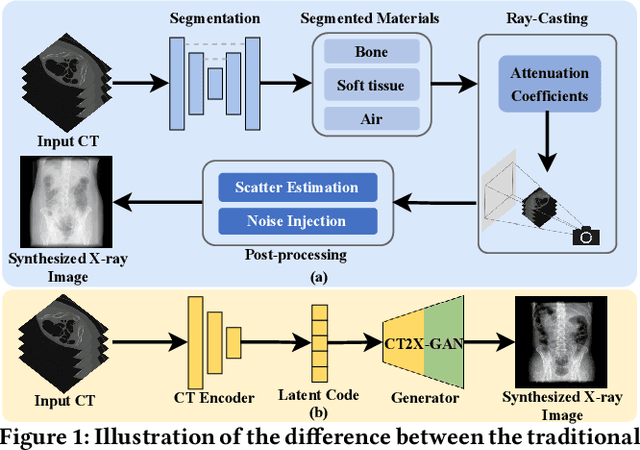

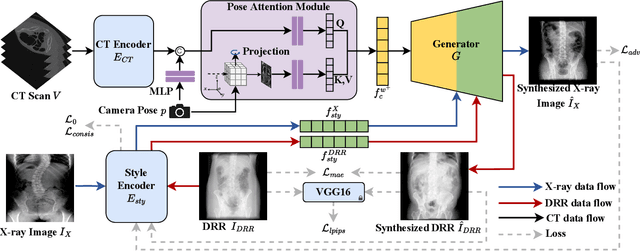
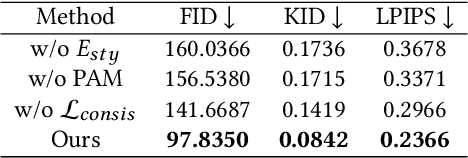
X-ray images play a vital role in the intraoperative processes due to their high resolution and fast imaging speed and greatly promote the subsequent segmentation, registration and reconstruction. However, over-dosed X-rays superimpose potential risks to human health to some extent. Data-driven algorithms from volume scans to X-ray images are restricted by the scarcity of paired X-ray and volume data. Existing methods are mainly realized by modelling the whole X-ray imaging procedure. In this study, we propose a learning-based approach termed CT2X-GAN to synthesize the X-ray images in an end-to-end manner using the content and style disentanglement from three different image domains. Our method decouples the anatomical structure information from CT scans and style information from unpaired real X-ray images/ digital reconstructed radiography (DRR) images via a series of decoupling encoders. Additionally, we introduce a novel consistency regularization term to improve the stylistic resemblance between synthesized X-ray images and real X-ray images. Meanwhile, we also impose a supervised process by computing the similarity of computed real DRR and synthesized DRR images. We further develop a pose attention module to fully strengthen the comprehensive information in the decoupled content code from CT scans, facilitating high-quality multi-view image synthesis in the lower 2D space. Extensive experiments were conducted on the publicly available CTSpine1K dataset and achieved 97.8350, 0.0842 and 3.0938 in terms of FID, KID and defined user-scored X-ray similarity, respectively. In comparison with 3D-aware methods ($\pi$-GAN, EG3D), CT2X-GAN is superior in improving the synthesis quality and realistic to the real X-ray images.
Scalable Scene Modeling from Perspective Imaging: Physics-based Appearance and Geometry Inference
Apr 01, 2024



3D scene modeling techniques serve as the bedrocks in the geospatial engineering and computer science, which drives many applications ranging from automated driving, terrain mapping, navigation, virtual, augmented, mixed, and extended reality (for gaming and movie industry etc.). This dissertation presents a fraction of contributions that advances 3D scene modeling to its state of the art, in the aspects of both appearance and geometry modeling. In contrast to the prevailing deep learning methods, as a core contribution, this thesis aims to develop algorithms that follow first principles, where sophisticated physic-based models are introduced alongside with simpler learning and inference tasks. The outcomes of these algorithms yield processes that can consume much larger volume of data for highly accurate reconstructing 3D scenes at a scale without losing methodological generality, which are not possible by contemporary complex-model based deep learning methods. Specifically, the dissertation introduces three novel methodologies that address the challenges of inferring appearance and geometry through physics-based modeling. Overall, the research encapsulated in this dissertation marks a series of methodological triumphs in the processing of complex datasets. By navigating the confluence of deep learning, computational geometry, and photogrammetry, this work lays down a robust framework for future exploration and practical application in the rapidly evolving field of 3D scene reconstruction. The outcomes of these studies are evidenced through rigorous experiments and comparisons with existing state-of-the-art methods, demonstrating the efficacy and scalability of the proposed approaches.