 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Learning with Public Feature Conditioning
Jun 17, 2026We study differentially private (DP) regression in settings where each data sample includes public, non-sensitive features -- common in applications such as recommendation and advertising systems. While such label-DP or semi-sensitive-feature settings have been primarily explored in the context of classification, effective approaches for regression remain underexplored. We introduce Cond-DP, a conditioned variant of DPSGD that leverages the structure of public feature matrices to improve optimization under privacy constraints. Motivated by the observation that these public features often exhibit rapidly decaying spectra, Cond-DP incorporates a data-driven conditioning matrix to reshape the optimization landscape and accelerate convergence. We provide convergence guarantees for convex, strongly convex, and non-convex settings, and recover standard DPSGD as a special case when the conditioning matrix is the identity. We show how to construct an effective conditioning matrix for Cond-DP directly from public features, enabling provably faster convergence than DPSGD in private linear regression without incurring additional privacy cost. Empirically, Cond-DP with this conditioning matrix consistently outperforms state-of-the-art baselines across a wide range of datasets and model architectures under label DP, demonstrating strong and robust performance in practice.
MAC-Attention: a Match-Amend-Complete Scheme for Fast and Accurate Attention Computation
Mar 31, 2026Long-context decoding in LLMs is IO-bound: each token re-reads an ever-growing KV cache. Prior accelerations cut bytes via compression, which lowers fidelity, or selection/eviction, which restricts what remains accessible, and both can degrade delayed recall and long-form generation. We introduce MAC-Attention, a fidelity- and access-preserving alternative that accelerates decoding by reusing prior attention computations for semantically similar recent queries. It starts with a match stage that performs pre-RoPE L2 matching over a short local window; an amend stage rectifies the reused attention by recomputing a small band near the match boundary; and a complete stage fuses the rectified results with fresh attention computed on the KV tail through a numerically stable merge. On a match hit, the compute and bandwidth complexity is constant regardless of context length. The method is model-agnostic and composes with IO-aware kernels, paged-KV managers, and MQA/GQA. Across LongBench v2 (120K), RULER (120K), and LongGenBench (16K continuous generation), compared to the latest FlashInfer library, MAC-Attention reduces KV accesses by up to 99%, cuts token generation latency by over 60% at 128K, and achieves over 14.3x attention-phase speedups, up to 2.6x end-to-end, while maintaining full-attention quality. By reusing computation, MAC-Attention delivers long-context inference that is both fast and faithful. Code is available here: https://github.com/YJHMITWEB/MAC-Attention.git
Training Differentially Private Ad Prediction Models with Semi-Sensitive Features
Jan 26, 2024



Motivated by problems arising in digital advertising, we introduce the task of training differentially private (DP) machine learning models with semi-sensitive features. In this setting, a subset of the features is known to the attacker (and thus need not be protected) while the remaining features as well as the label are unknown to the attacker and should be protected by the DP guarantee. This task interpolates between training the model with full DP (where the label and all features should be protected) or with label DP (where all the features are considered known, and only the label should be protected). We present a new algorithm for training DP models with semi-sensitive features. Through an empirical evaluation on real ads datasets, we demonstrate that our algorithm surpasses in utility the baselines of (i) DP stochastic gradient descent (DP-SGD) run on all features (known and unknown), and (ii) a label DP algorithm run only on the known features (while discarding the unknown ones).
Private Learning with Public Features
Oct 24, 2023



We study a class of private learning problems in which the data is a join of private and public features. This is often the case in private personalization tasks such as recommendation or ad prediction, in which features related to individuals are sensitive, while features related to items (the movies or songs to be recommended, or the ads to be shown to users) are publicly available and do not require protection. A natural question is whether private algorithms can achieve higher utility in the presence of public features. We give a positive answer for multi-encoder models where one of the encoders operates on public features. We develop new algorithms that take advantage of this separation by only protecting certain sufficient statistics (instead of adding noise to the gradient). This method has a guaranteed utility improvement for linear regression, and importantly, achieves the state of the art on two standard private recommendation benchmarks, demonstrating the importance of methods that adapt to the private-public feature separation.
Private Matrix Factorization with Public Item Features
Sep 17, 2023



We consider the problem of training private recommendation models with access to public item features. Training with Differential Privacy (DP) offers strong privacy guarantees, at the expense of loss in recommendation quality. We show that incorporating public item features during training can help mitigate this loss in quality. We propose a general approach based on collective matrix factorization (CMF), that works by simultaneously factorizing two matrices: the user feedback matrix (representing sensitive data) and an item feature matrix that encodes publicly available (non-sensitive) item information. The method is conceptually simple, easy to tune, and highly scalable. It can be applied to different types of public item data, including: (1) categorical item features; (2) item-item similarities learned from public sources; and (3) publicly available user feedback. Furthermore, these data modalities can be collectively utilized to fully leverage public data. Evaluating our method on a standard DP recommendation benchmark, we find that using public item features significantly narrows the quality gap between private models and their non-private counterparts. As privacy constraints become more stringent, models rely more heavily on public side features for recommendation. This results in a smooth transition from collaborative filtering to item-based contextual recommendations.
Multi-Task Differential Privacy Under Distribution Skew
Feb 15, 2023
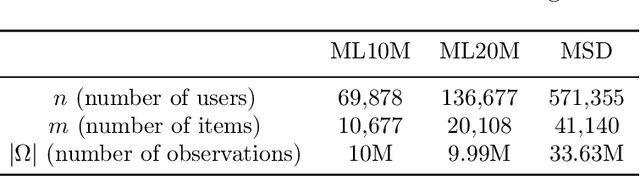


We study the problem of multi-task learning under user-level differential privacy, in which $n$ users contribute data to $m$ tasks, each involving a subset of users. One important aspect of the problem, that can significantly impact quality, is the distribution skew among tasks. Certain tasks may have much fewer data samples than others, making them more susceptible to the noise added for privacy. It is natural to ask whether algorithms can adapt to this skew to improve the overall utility. We give a systematic analysis of the problem, by studying how to optimally allocate a user's privacy budget among tasks. We propose a generic algorithm, based on an adaptive reweighting of the empirical loss, and show that when there is task distribution skew, this gives a quantifiable improvement of excess empirical risk. Experimental studies on recommendation problems that exhibit a long tail of small tasks, demonstrate that our methods significantly improve utility, achieving the state of the art on two standard benchmarks.
Differentially Private Image Classification from Features
Nov 24, 2022
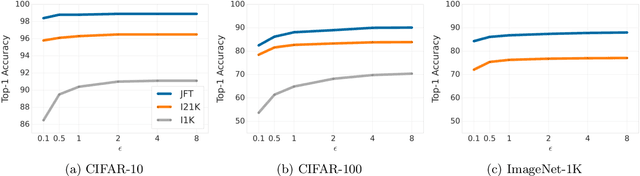
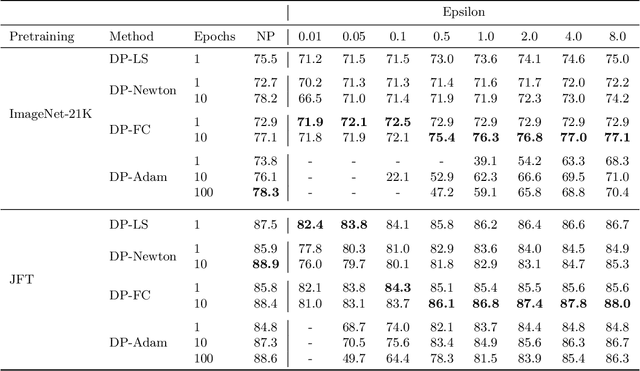
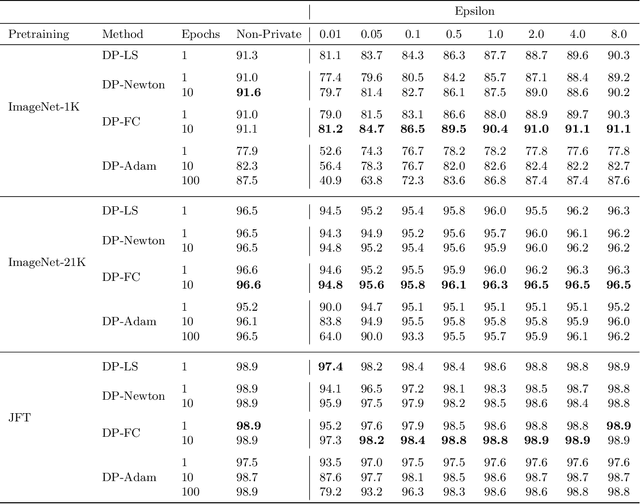
Leveraging transfer learning has recently been shown to be an effective strategy for training large models with Differential Privacy (DP). Moreover, somewhat surprisingly, recent works have found that privately training just the last layer of a pre-trained model provides the best utility with DP. While past studies largely rely on algorithms like DP-SGD for training large models, in the specific case of privately learning from features, we observe that computational burden is low enough to allow for more sophisticated optimization schemes, including second-order methods. To that end, we systematically explore the effect of design parameters such as loss function and optimization algorithm. We find that, while commonly used logistic regression performs better than linear regression in the non-private setting, the situation is reversed in the private setting. We find that linear regression is much more effective than logistic regression from both privacy and computational aspects, especially at stricter epsilon values ($\epsilon < 1$). On the optimization side, we also explore using Newton's method, and find that second-order information is quite helpful even with privacy, although the benefit significantly diminishes with stricter privacy guarantees. While both methods use second-order information, least squares is effective at lower epsilons while Newton's method is effective at larger epsilon values. To combine the benefits of both, we propose a novel algorithm called DP-FC, which leverages feature covariance instead of the Hessian of the logistic regression loss and performs well across all $\epsilon$ values we tried. With this, we obtain new SOTA results on ImageNet-1k, CIFAR-100 and CIFAR-10 across all values of $\epsilon$ typically considered. Most remarkably, on ImageNet-1K, we obtain top-1 accuracy of 88\% under (8, $8 * 10^{-7}$)-DP and 84.3\% under (0.1, $8 * 10^{-7}$)-DP.
Reciprocity in Machine Learning
Feb 19, 2022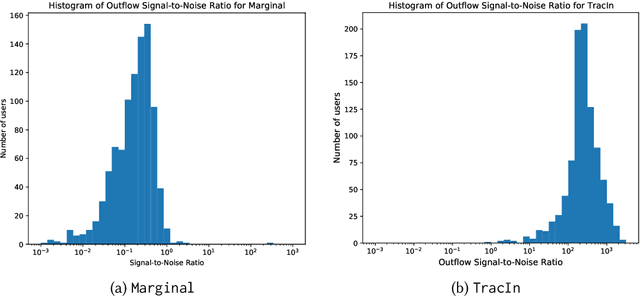
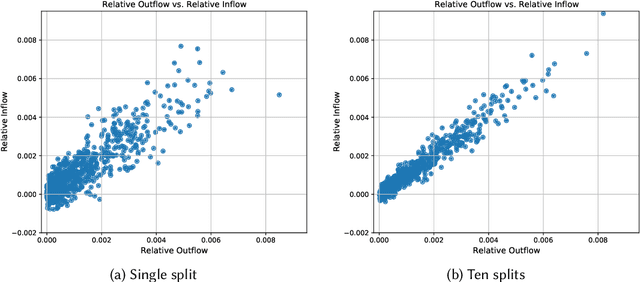
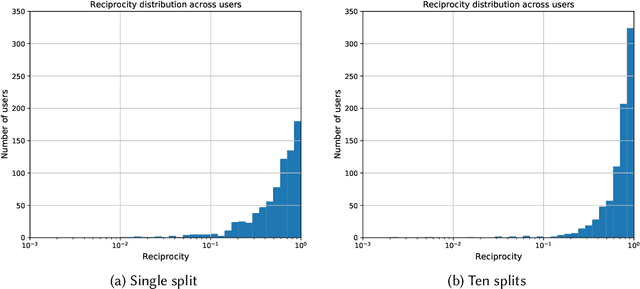
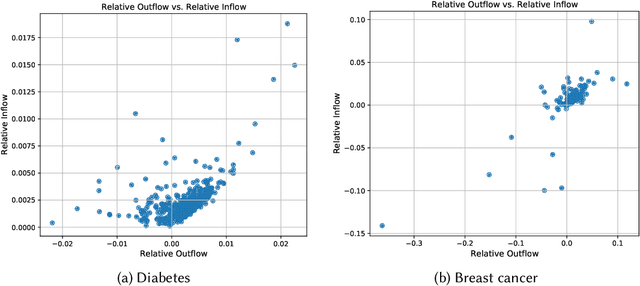
Machine learning is pervasive. It powers recommender systems such as Spotify, Instagram and YouTube, and health-care systems via models that predict sleep patterns, or the risk of disease. Individuals contribute data to these models and benefit from them. Are these contributions (outflows of influence) and benefits (inflows of influence) reciprocal? We propose measures of outflows, inflows and reciprocity building on previously proposed measures of training data influence. Our initial theoretical and empirical results indicate that under certain distributional assumptions, some classes of models are approximately reciprocal. We conclude with several open directions.
ALX: Large Scale Matrix Factorization on TPUs
Dec 03, 2021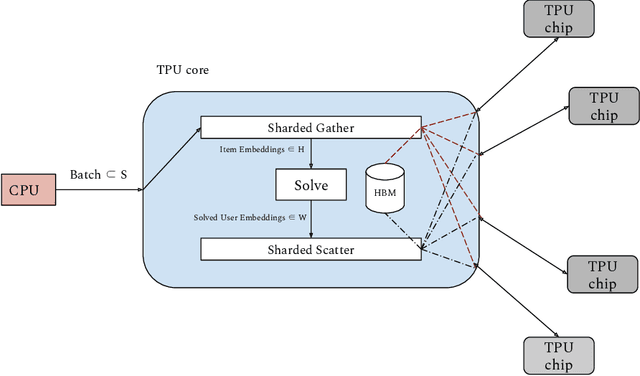


We present ALX, an open-source library for distributed matrix factorization using Alternating Least Squares, written in JAX. Our design allows for efficient use of the TPU architecture and scales well to matrix factorization problems of O(B) rows/columns by scaling the number of available TPU cores. In order to spur future research on large scale matrix factorization methods and to illustrate the scalability properties of our own implementation, we also built a real world web link prediction dataset called WebGraph. This dataset can be easily modeled as a matrix factorization problem. We created several variants of this dataset based on locality and sparsity properties of sub-graphs. The largest variant of WebGraph has around 365M nodes and training a single epoch finishes in about 20 minutes with 256 TPU cores. We include speed and performance numbers of ALX on all variants of WebGraph. Both the framework code and the dataset is open-sourced.
iALS++: Speeding up Matrix Factorization with Subspace Optimization
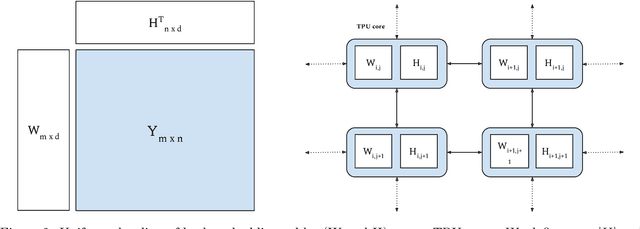
Oct 26, 2021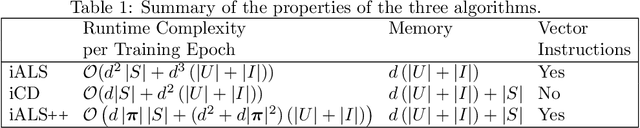
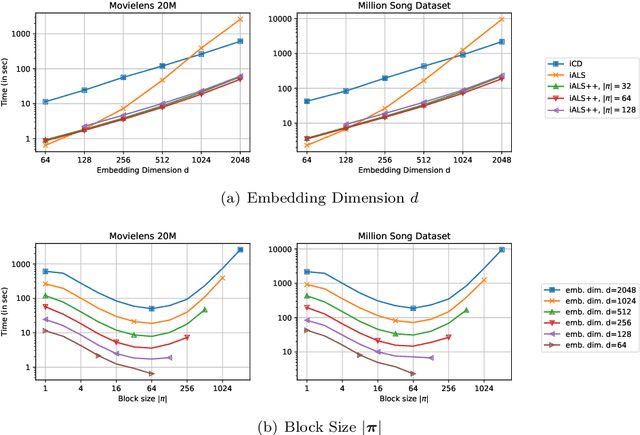

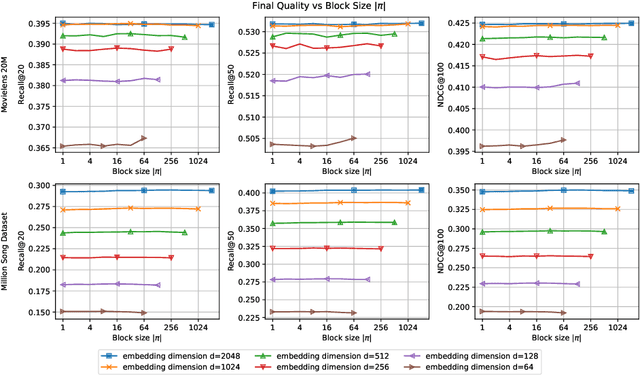
iALS is a popular algorithm for learning matrix factorization models from implicit feedback with alternating least squares. This algorithm was invented over a decade ago but still shows competitive quality compared to recent approaches like VAE, EASE, SLIM, or NCF. Due to a computational trick that avoids negative sampling, iALS is very efficient especially for large item catalogues. However, iALS does not scale well with large embedding dimensions, d, due to its cubic runtime dependency on d. Coordinate descent variations, iCD, have been proposed to lower the complexity to quadratic in d. In this work, we show that iCD approaches are not well suited for modern processors and can be an order of magnitude slower than a careful iALS implementation for small to mid scale embedding sizes (d ~ 100) and only perform better than iALS on large embeddings d ~ 1000. We propose a new solver iALS++ that combines the advantages of iALS in terms of vector processing with a low computational complexity as in iCD. iALS++ is an order of magnitude faster than iCD both for small and large embedding dimensions. It can solve benchmark problems like Movielens 20M or Million Song Dataset even for 1000 dimensional embedding vectors in a few minutes.