 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Differentially Private Ad Prediction Models with Semi-Sensitive Features
Jan 26, 2024



Motivated by problems arising in digital advertising, we introduce the task of training differentially private (DP) machine learning models with semi-sensitive features. In this setting, a subset of the features is known to the attacker (and thus need not be protected) while the remaining features as well as the label are unknown to the attacker and should be protected by the DP guarantee. This task interpolates between training the model with full DP (where the label and all features should be protected) or with label DP (where all the features are considered known, and only the label should be protected). We present a new algorithm for training DP models with semi-sensitive features. Through an empirical evaluation on real ads datasets, we demonstrate that our algorithm surpasses in utility the baselines of (i) DP stochastic gradient descent (DP-SGD) run on all features (known and unknown), and (ii) a label DP algorithm run only on the known features (while discarding the unknown ones).
Private Ad Modeling with DP-SGD
Nov 21, 2022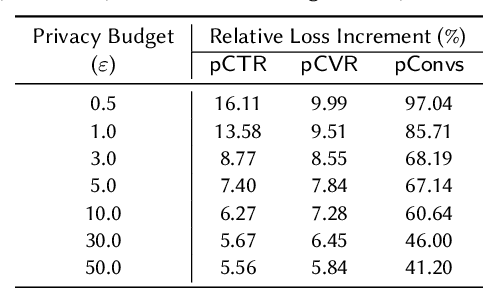
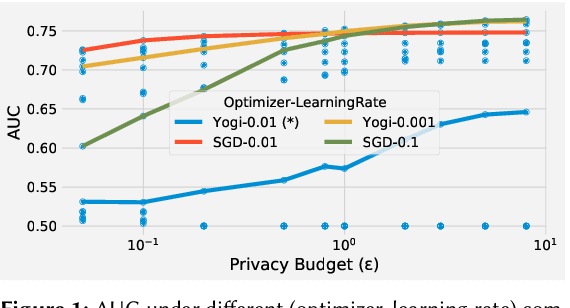

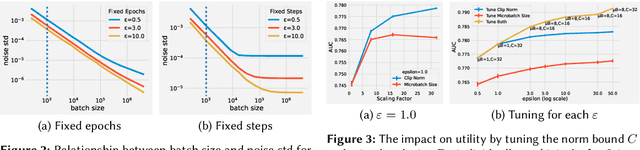
A well-known algorithm in privacy-preserving ML is differentially private stochastic gradient descent (DP-SGD). While this algorithm has been evaluated on text and image data, it has not been previously applied to ads data, which are notorious for their high class imbalance and sparse gradient updates. In this work we apply DP-SGD to several ad modeling tasks including predicting click-through rates, conversion rates, and number of conversion events, and evaluate their privacy-utility trade-off on real-world datasets. Our work is the first to empirically demonstrate that DP-SGD can provide both privacy and utility for ad modeling tasks.
Privacy-Preserving Inference in Machine Learning Services Using Trusted Execution Environments
Dec 07, 2019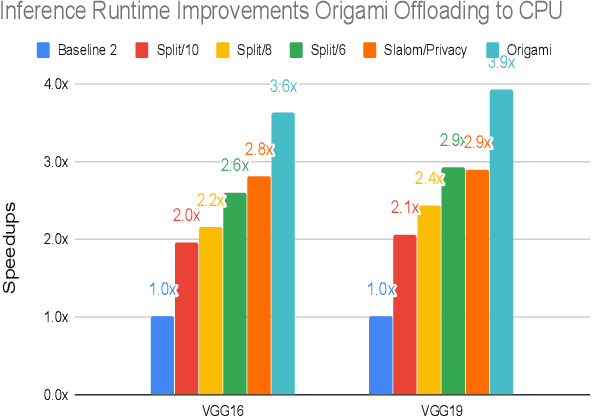
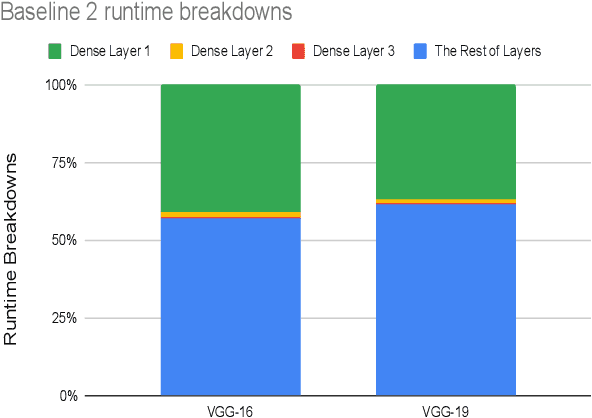
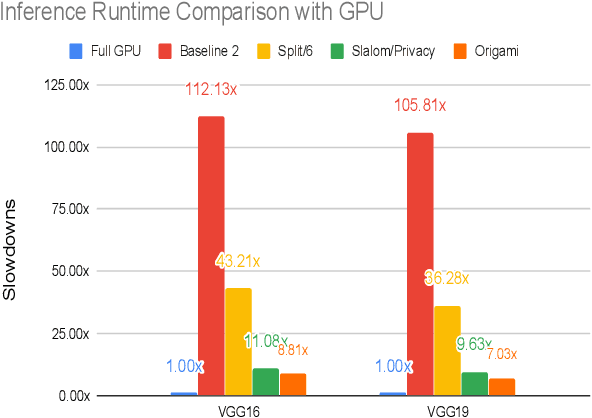
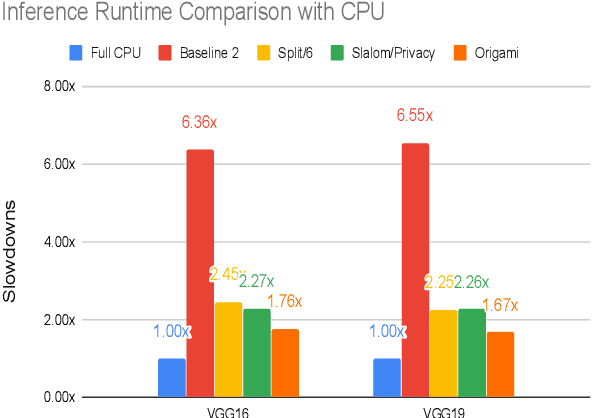
This work presents Origami, which provides privacy-preserving inference for large deep neural network (DNN) models through a combination of enclave execution, cryptographic blinding, interspersed with accelerator-based computation. Origami partitions the ML model into multiple partitions. The first partition receives the encrypted user input within an SGX enclave. The enclave decrypts the input and then applies cryptographic blinding to the input data and the model parameters. Cryptographic blinding is a technique that adds noise to obfuscate data. Origami sends the obfuscated data for computation to an untrusted GPU/CPU. The blinding and de-blinding factors are kept private by the SGX enclave, thereby preventing any adversary from denoising the data, when the computation is offloaded to a GPU/CPU. The computed output is returned to the enclave, which decodes the computation on noisy data using the unblinding factors privately stored within SGX. This process may be repeated for each DNN layer, as has been done in prior work Slalom. However, the overhead of blinding and unblinding the data is a limiting factor to scalability. Origami relies on the empirical observation that the feature maps after the first several layers can not be used, even by a powerful conditional GAN adversary to reconstruct input. Hence, Origami dynamically switches to executing the rest of the DNN layers directly on an accelerator without needing any further cryptographic blinding intervention to preserve privacy. We empirically demonstrate that using Origami, a conditional GAN adversary, even with an unlimited inference budget, cannot reconstruct the input. We implement and demonstrate the performance gains of Origami using the VGG-16 and VGG-19 models. Compared to running the entire VGG-19 model within SGX, Origami inference improves the performance of private inference from 11x while using Slalom to 15.1x.
Train Where the Data is: A Case for Bandwidth Efficient Coded Training
Oct 22, 2019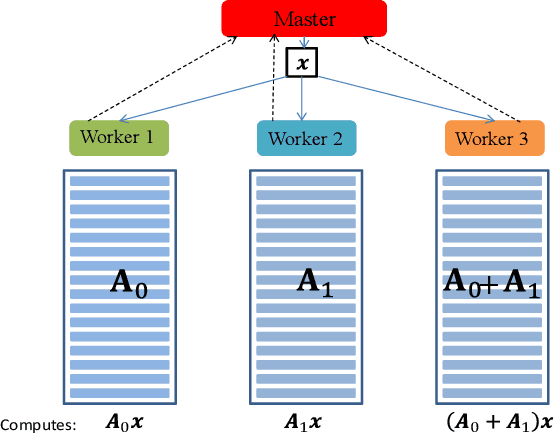
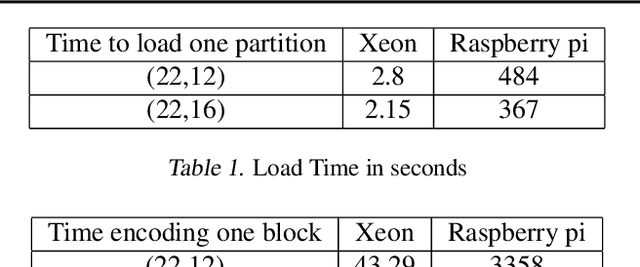
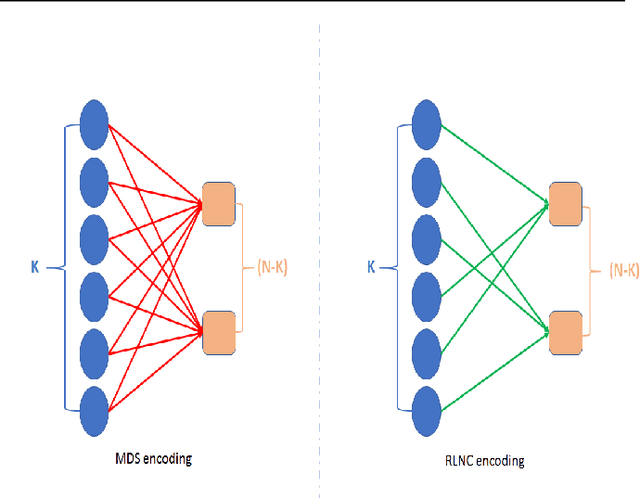
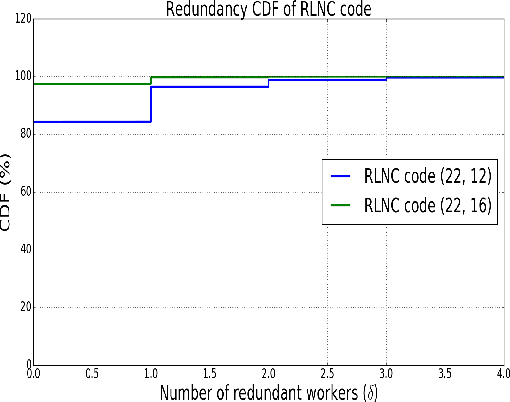
Training a machine learning model is both compute and data-intensive. Most of the model training is performed on high performance compute nodes and the training data is stored near these nodes for faster training. But there is a growing interest in enabling training near the data. For instance, mobile devices are rich sources of training data. It may not be feasible to consolidate the data from mobile devices into a cloud service, due to bandwidth and data privacy reasons. Training at mobile devices is however fraught with challenges. First mobile devices may join or leave the distributed setting, either voluntarily or due to environmental uncertainties, such as lack of power. Tolerating uncertainties is critical to the success of distributed mobile training. One proactive approach to tolerate computational uncertainty is to store data in a coded format and perform training on coded data. Encoding data is a challenging task since erasure codes require multiple devices to exchange their data to create a coded data partition, which places a significant bandwidth constraint. Furthermore, coded computing traditionally relied on a central node to encode and distribute data to all the worker nodes, which is not practical in a distributed mobile setting. In this paper, we tackle the uncertainty in distributed mobile training using a bandwidth-efficient encoding strategy. We use a Random Linear Network coding (RLNC) which reduces the need to exchange data partitions across all participating mobile devices, while at the same time preserving the property of coded computing to tolerate uncertainties. We implement gradient descent for logistic regression and SVM to evaluate the effectiveness of our mobile training framework. We demonstrate a 50% reduction in total required communication bandwidth compared to MDS coded computation, one of the popular erasure codes.
Collage Inference: Tolerating Stragglers in Distributed Neural Network Inference using Coding
Apr 27, 2019
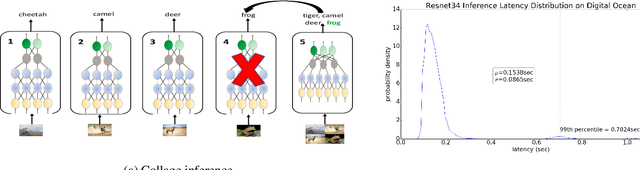

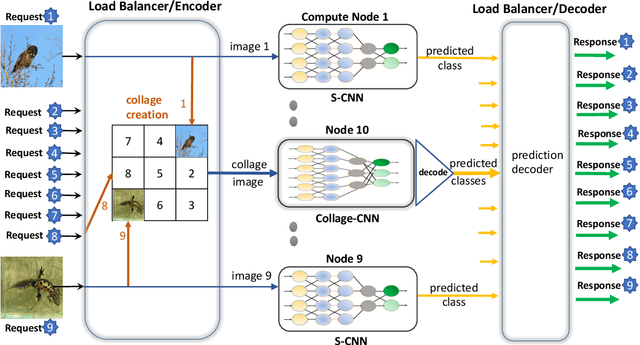
MLaaS (ML-as-a-Service) offerings by cloud computing platforms are becoming increasingly popular these days. Pre-trained machine learning models are deployed on the cloud to support prediction based applications and services. For achieving higher throughput, incoming requests are served by running multiple replicas of the model on different machines concurrently. Incidence of straggler nodes in distributed inference is a significant concern since it can increase inference latency, violate SLOs of the service. In this paper, we propose a novel coded inference model to deal with stragglers in distributed image classification. We propose modified single shot object detection models, Collage-CNN models, to provide necessary resilience efficiently. A Collage-CNN model takes collage images formed by combining multiple images as its input and performs multi-image classification in one shot. We generate custom training collages using images from standard image classification datasets and train the model to achieve high classification accuracy. Deploying the Collage-CNN models in the cloud, we demonstrate that the 99th percentile latency can be reduced by 1.45X to 2.46X compared to replication based approaches and without compromising prediction accuracy.