 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrain Where the Data is: A Case for Bandwidth Efficient Coded Training
Oct 22, 2019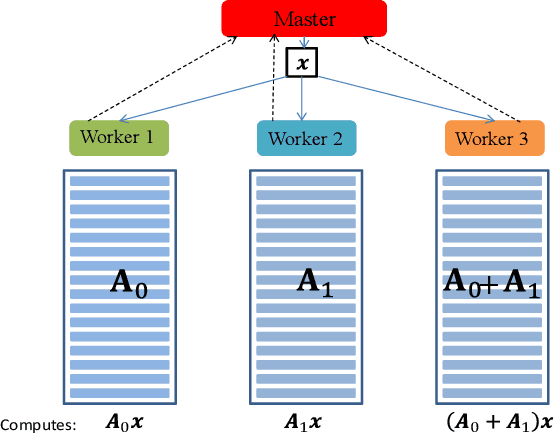
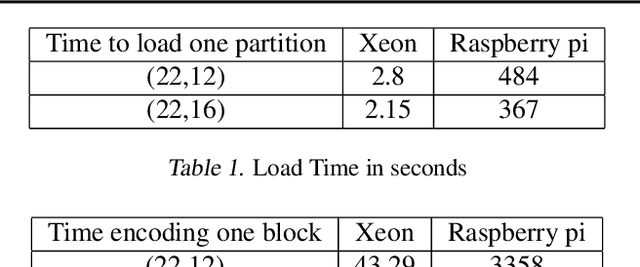
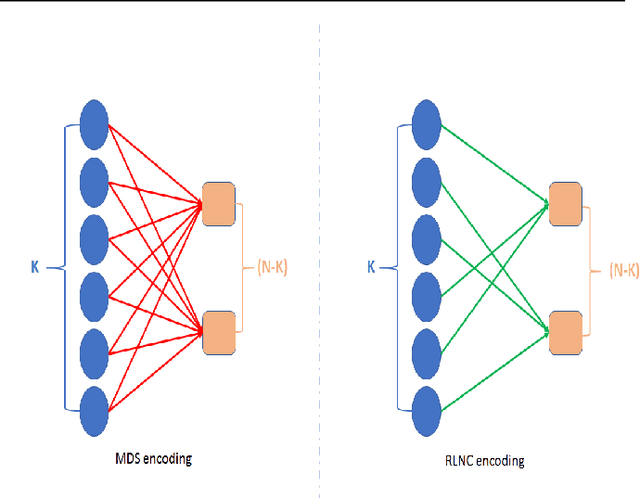
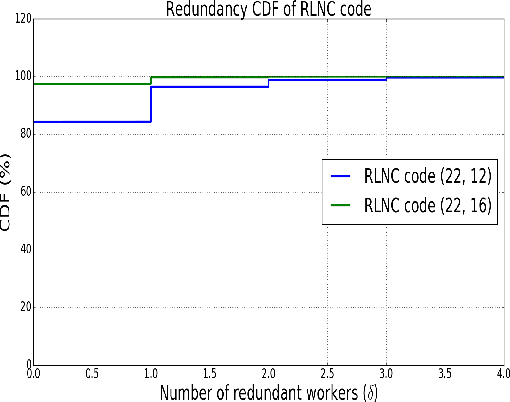
Training a machine learning model is both compute and data-intensive. Most of the model training is performed on high performance compute nodes and the training data is stored near these nodes for faster training. But there is a growing interest in enabling training near the data. For instance, mobile devices are rich sources of training data. It may not be feasible to consolidate the data from mobile devices into a cloud service, due to bandwidth and data privacy reasons. Training at mobile devices is however fraught with challenges. First mobile devices may join or leave the distributed setting, either voluntarily or due to environmental uncertainties, such as lack of power. Tolerating uncertainties is critical to the success of distributed mobile training. One proactive approach to tolerate computational uncertainty is to store data in a coded format and perform training on coded data. Encoding data is a challenging task since erasure codes require multiple devices to exchange their data to create a coded data partition, which places a significant bandwidth constraint. Furthermore, coded computing traditionally relied on a central node to encode and distribute data to all the worker nodes, which is not practical in a distributed mobile setting. In this paper, we tackle the uncertainty in distributed mobile training using a bandwidth-efficient encoding strategy. We use a Random Linear Network coding (RLNC) which reduces the need to exchange data partitions across all participating mobile devices, while at the same time preserving the property of coded computing to tolerate uncertainties. We implement gradient descent for logistic regression and SVM to evaluate the effectiveness of our mobile training framework. We demonstrate a 50% reduction in total required communication bandwidth compared to MDS coded computation, one of the popular erasure codes.
Pipe-SGD: A Decentralized Pipelined SGD Framework for Distributed Deep Net Training
Nov 08, 2018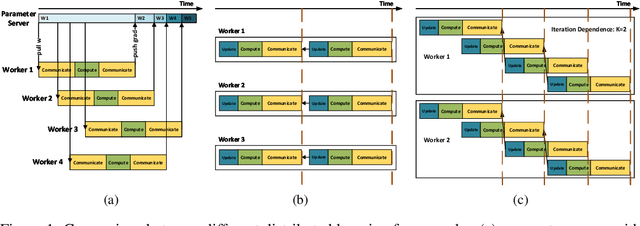
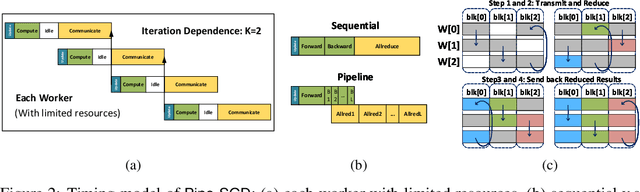
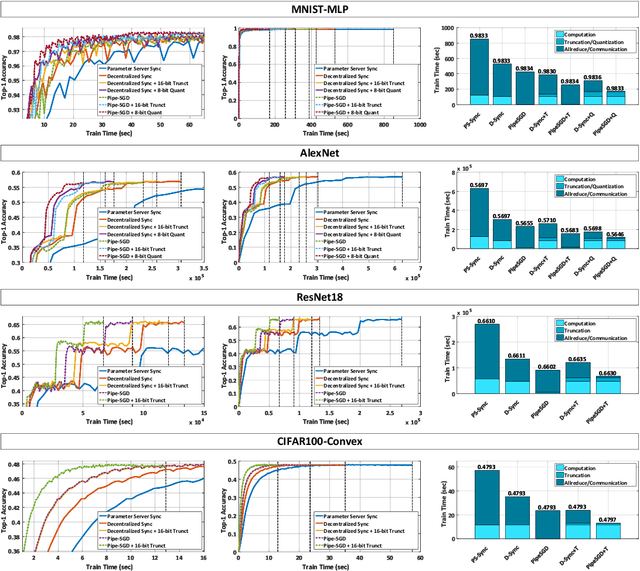
Distributed training of deep nets is an important technique to address some of the present day computing challenges like memory consumption and computational demands. Classical distributed approaches, synchronous or asynchronous, are based on the parameter server architecture, i.e., worker nodes compute gradients which are communicated to the parameter server while updated parameters are returned. Recently, distributed training with AllReduce operations gained popularity as well. While many of those operations seem appealing, little is reported about wall-clock training time improvements. In this paper, we carefully analyze the AllReduce based setup, propose timing models which include network latency, bandwidth, cluster size and compute time, and demonstrate that a pipelined training with a width of two combines the best of both synchronous and asynchronous training. Specifically, for a setup consisting of a four-node GPU cluster we show wall-clock time training improvements of up to 5.4x compared to conventional approaches.
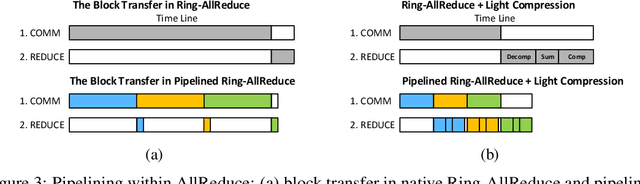
GradiVeQ: Vector Quantization for Bandwidth-Efficient Gradient Aggregation in Distributed CNN Training
Nov 08, 2018

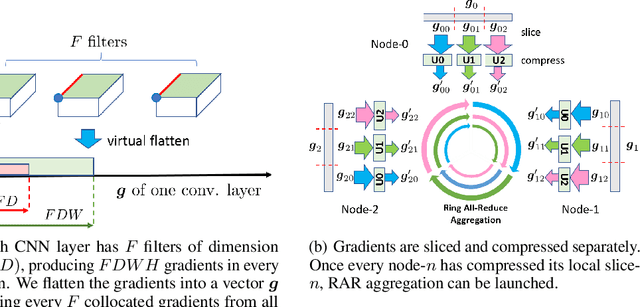
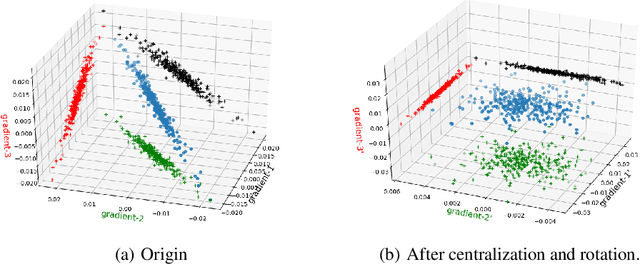
Data parallelism can boost the training speed of convolutional neural networks (CNN), but could suffer from significant communication costs caused by gradient aggregation. To alleviate this problem, several scalar quantization techniques have been developed to compress the gradients. But these techniques could perform poorly when used together with decentralized aggregation protocols like ring all-reduce (RAR), mainly due to their inability to directly aggregate compressed gradients. In this paper, we empirically demonstrate the strong linear correlations between CNN gradients, and propose a gradient vector quantization technique, named GradiVeQ, to exploit these correlations through principal component analysis (PCA) for substantial gradient dimension reduction. GradiVeQ enables direct aggregation of compressed gradients, hence allows us to build a distributed learning system that parallelizes GradiVeQ gradient compression and RAR communications. Extensive experiments on popular CNNs demonstrate that applying GradiVeQ slashes the wall-clock gradient aggregation time of the original RAR by more than 5X without noticeable accuracy loss, and reduces the end-to-end training time by almost 50%. The results also show that GradiVeQ is compatible with scalar quantization techniques such as QSGD (Quantized SGD), and achieves a much higher speed-up gain under the same compression ratio.