 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollage Inference: Achieving low tail latency during distributed image classification using coded redundancy models
Jun 05, 2019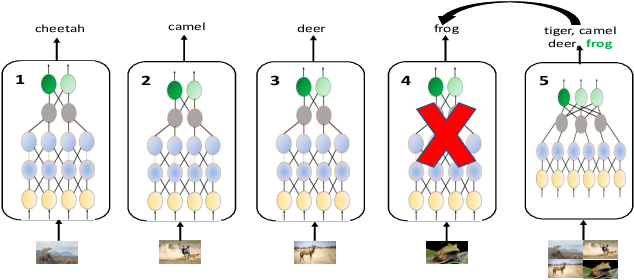
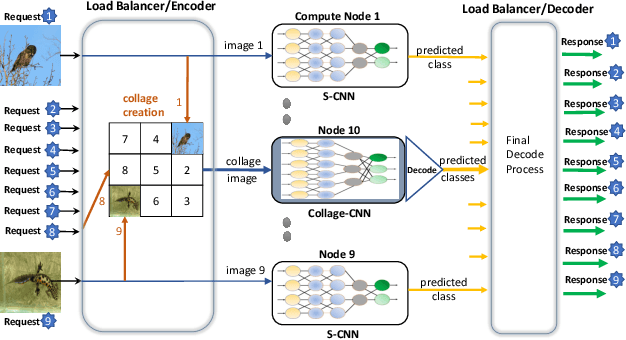
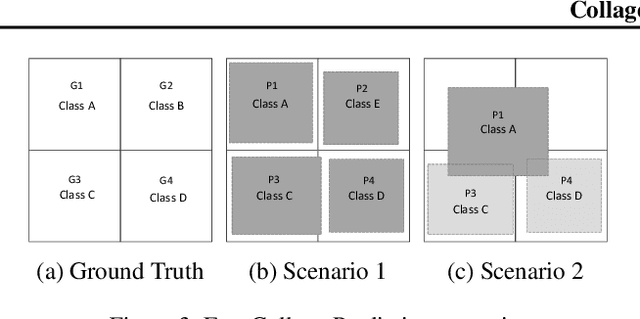
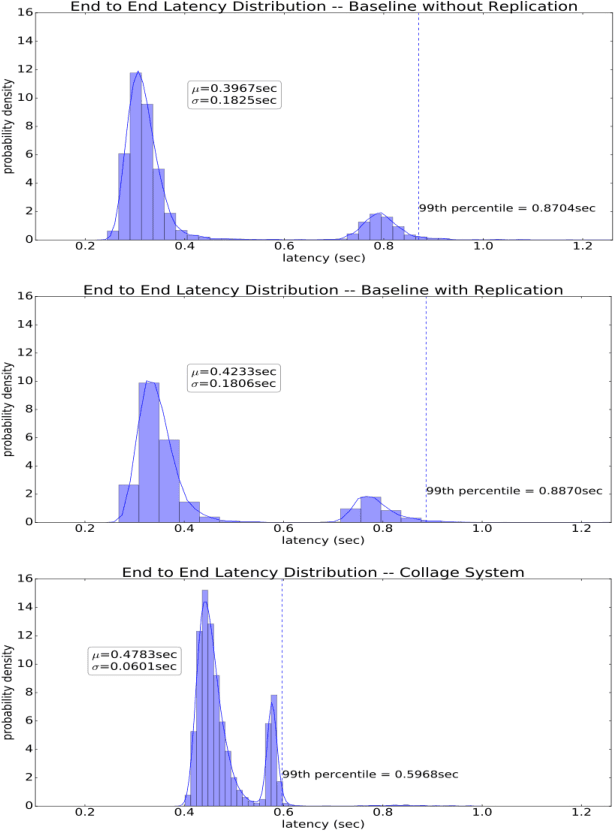
Reducing the latency variance in machine learning inference is a key requirement in many applications. Variance is harder to control in a cloud deployment in the presence of stragglers. In spite of this challenge, inference is increasingly being done in the cloud, due to the advent of affordable machine learning as a service (MLaaS) platforms. Existing approaches to reduce variance rely on replication which is expensive and partially negates the affordability of MLaaS. In this work, we argue that MLaaS platforms also provide unique opportunities to cut the cost of redundancy. In MLaaS platforms, multiple inference requests are concurrently received by a load balancer which can then create a more cost-efficient redundancy coding across a larger collection of images. We propose a novel convolutional neural network model, Collage-CNN, to provide a low-cost redundancy framework. A Collage-CNN model takes a collage formed by combining multiple images and performs multi-image classification in one shot, albeit at slightly lower accuracy. We then augment a collection of traditional single image classifiers with a single Collage-CNN classifier which acts as a low-cost redundant backup. Collage-CNN then provides backup classification results if a single image classification straggles. Deploying the Collage-CNN models in the cloud, we demonstrate that the 99th percentile tail latency of inference can be reduced by 1.47X compared to replication based approaches while providing high accuracy. Also, variation in inference latency can be reduced by 9X with a slight increase in average inference latency.
GradiVeQ: Vector Quantization for Bandwidth-Efficient Gradient Aggregation in Distributed CNN Training
Nov 08, 2018

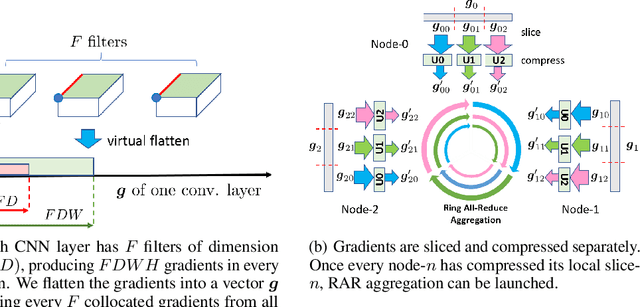
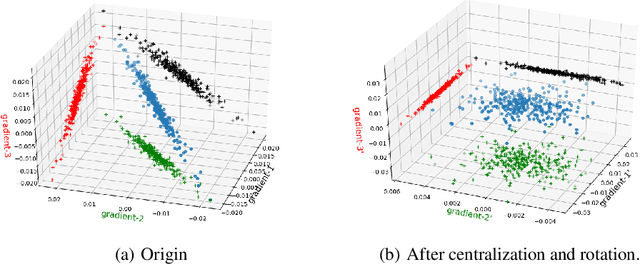
Data parallelism can boost the training speed of convolutional neural networks (CNN), but could suffer from significant communication costs caused by gradient aggregation. To alleviate this problem, several scalar quantization techniques have been developed to compress the gradients. But these techniques could perform poorly when used together with decentralized aggregation protocols like ring all-reduce (RAR), mainly due to their inability to directly aggregate compressed gradients. In this paper, we empirically demonstrate the strong linear correlations between CNN gradients, and propose a gradient vector quantization technique, named GradiVeQ, to exploit these correlations through principal component analysis (PCA) for substantial gradient dimension reduction. GradiVeQ enables direct aggregation of compressed gradients, hence allows us to build a distributed learning system that parallelizes GradiVeQ gradient compression and RAR communications. Extensive experiments on popular CNNs demonstrate that applying GradiVeQ slashes the wall-clock gradient aggregation time of the original RAR by more than 5X without noticeable accuracy loss, and reduces the end-to-end training time by almost 50%. The results also show that GradiVeQ is compatible with scalar quantization techniques such as QSGD (Quantized SGD), and achieves a much higher speed-up gain under the same compression ratio.