 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Multimodal Language Models Really Understand Direction? A Benchmark for Compass Direction Reasoning
Dec 21, 2024



Direction reasoning is essential for intelligent systems to understand the real world. While existing work focuses primarily on spatial reasoning, compass direction reasoning remains underexplored. To address this, we propose the Compass Direction Reasoning (CDR) benchmark, designed to evaluate the direction reasoning capabilities of multimodal language models (MLMs). CDR includes three types images to test spatial (up, down, left, right) and compass (north, south, east, west) directions. Our evaluation reveals that most MLMs struggle with direction reasoning, often performing at random guessing levels. Experiments show that training directly with CDR data yields limited improvements, as it requires an understanding of real-world physical rules. We explore the impact of mixdata and CoT fine-tuning methods, which significantly enhance MLM performance in compass direction reasoning by incorporating diverse data and step-by-step reasoning, improving the model's ability to understand direction relationships.
Learning Granularity-Unified Representations for Text-to-Image Person Re-identification
Jul 16, 2022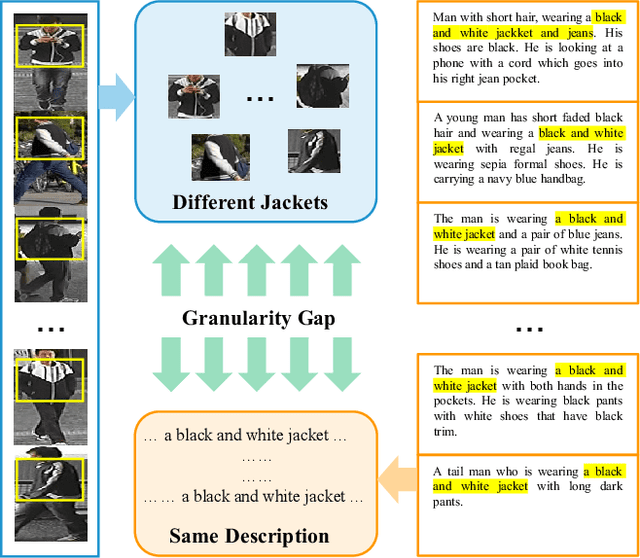
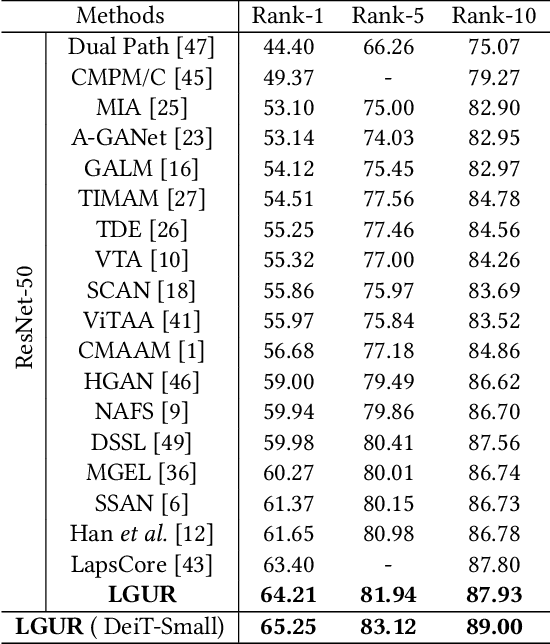
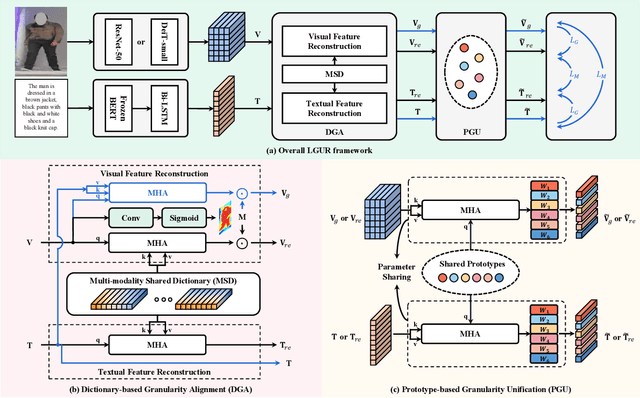
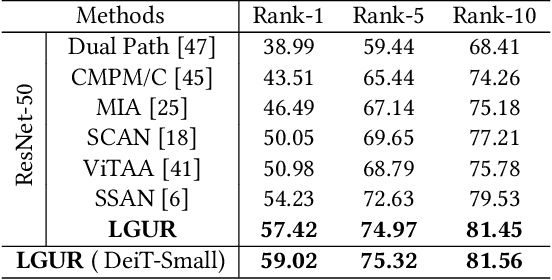
Text-to-image person re-identification (ReID) aims to search for pedestrian images of an interested identity via textual descriptions. It is challenging due to both rich intra-modal variations and significant inter-modal gaps. Existing works usually ignore the difference in feature granularity between the two modalities, i.e., the visual features are usually fine-grained while textual features are coarse, which is mainly responsible for the large inter-modal gaps. In this paper, we propose an end-to-end framework based on transformers to learn granularity-unified representations for both modalities, denoted as LGUR. LGUR framework contains two modules: a Dictionary-based Granularity Alignment (DGA) module and a Prototype-based Granularity Unification (PGU) module. In DGA, in order to align the granularities of two modalities, we introduce a Multi-modality Shared Dictionary (MSD) to reconstruct both visual and textual features. Besides, DGA has two important factors, i.e., the cross-modality guidance and the foreground-centric reconstruction, to facilitate the optimization of MSD. In PGU, we adopt a set of shared and learnable prototypes as the queries to extract diverse and semantically aligned features for both modalities in the granularity-unified feature space, which further promotes the ReID performance. Comprehensive experiments show that our LGUR consistently outperforms state-of-the-arts by large margins on both CUHK-PEDES and ICFG-PEDES datasets. Code will be released at https://github.com/ZhiyinShao-H/LGUR.
Privacy-Preserving Inference in Machine Learning Services Using Trusted Execution Environments
Dec 07, 2019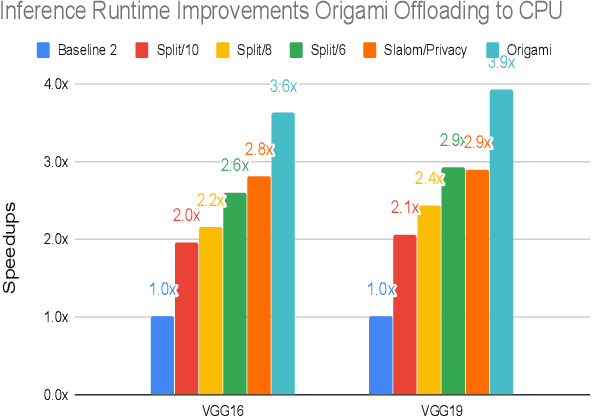
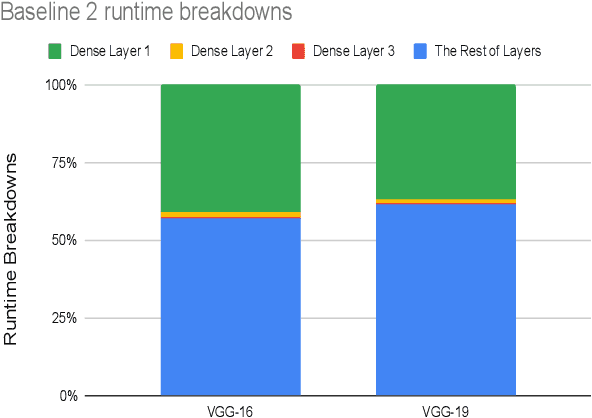
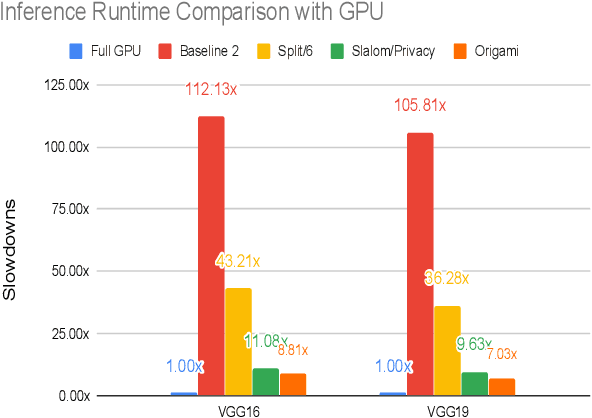
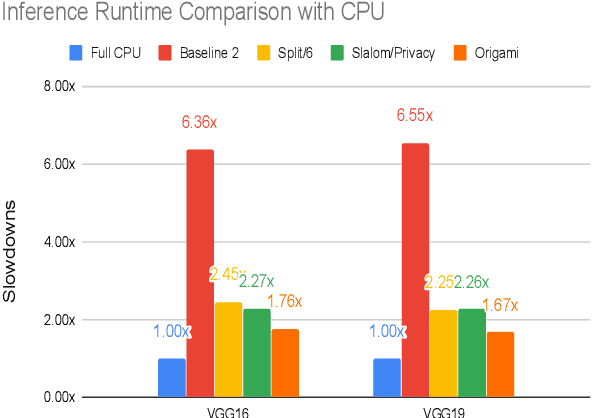
This work presents Origami, which provides privacy-preserving inference for large deep neural network (DNN) models through a combination of enclave execution, cryptographic blinding, interspersed with accelerator-based computation. Origami partitions the ML model into multiple partitions. The first partition receives the encrypted user input within an SGX enclave. The enclave decrypts the input and then applies cryptographic blinding to the input data and the model parameters. Cryptographic blinding is a technique that adds noise to obfuscate data. Origami sends the obfuscated data for computation to an untrusted GPU/CPU. The blinding and de-blinding factors are kept private by the SGX enclave, thereby preventing any adversary from denoising the data, when the computation is offloaded to a GPU/CPU. The computed output is returned to the enclave, which decodes the computation on noisy data using the unblinding factors privately stored within SGX. This process may be repeated for each DNN layer, as has been done in prior work Slalom. However, the overhead of blinding and unblinding the data is a limiting factor to scalability. Origami relies on the empirical observation that the feature maps after the first several layers can not be used, even by a powerful conditional GAN adversary to reconstruct input. Hence, Origami dynamically switches to executing the rest of the DNN layers directly on an accelerator without needing any further cryptographic blinding intervention to preserve privacy. We empirically demonstrate that using Origami, a conditional GAN adversary, even with an unlimited inference budget, cannot reconstruct the input. We implement and demonstrate the performance gains of Origami using the VGG-16 and VGG-19 models. Compared to running the entire VGG-19 model within SGX, Origami inference improves the performance of private inference from 11x while using Slalom to 15.1x.
Train Where the Data is: A Case for Bandwidth Efficient Coded Training
Oct 22, 2019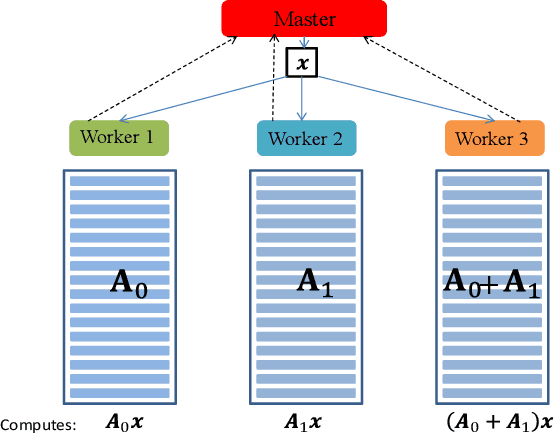
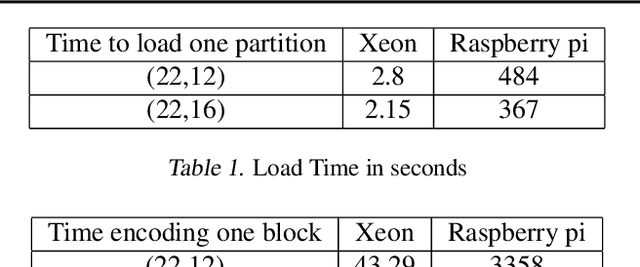
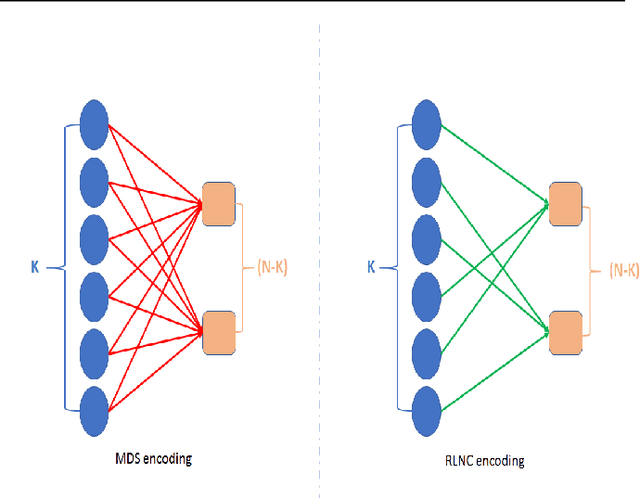
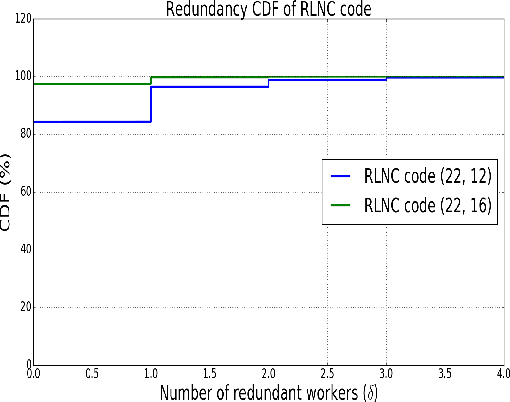
Training a machine learning model is both compute and data-intensive. Most of the model training is performed on high performance compute nodes and the training data is stored near these nodes for faster training. But there is a growing interest in enabling training near the data. For instance, mobile devices are rich sources of training data. It may not be feasible to consolidate the data from mobile devices into a cloud service, due to bandwidth and data privacy reasons. Training at mobile devices is however fraught with challenges. First mobile devices may join or leave the distributed setting, either voluntarily or due to environmental uncertainties, such as lack of power. Tolerating uncertainties is critical to the success of distributed mobile training. One proactive approach to tolerate computational uncertainty is to store data in a coded format and perform training on coded data. Encoding data is a challenging task since erasure codes require multiple devices to exchange their data to create a coded data partition, which places a significant bandwidth constraint. Furthermore, coded computing traditionally relied on a central node to encode and distribute data to all the worker nodes, which is not practical in a distributed mobile setting. In this paper, we tackle the uncertainty in distributed mobile training using a bandwidth-efficient encoding strategy. We use a Random Linear Network coding (RLNC) which reduces the need to exchange data partitions across all participating mobile devices, while at the same time preserving the property of coded computing to tolerate uncertainties. We implement gradient descent for logistic regression and SVM to evaluate the effectiveness of our mobile training framework. We demonstrate a 50% reduction in total required communication bandwidth compared to MDS coded computation, one of the popular erasure codes.
Collage Inference: Achieving low tail latency during distributed image classification using coded redundancy models
Jun 05, 2019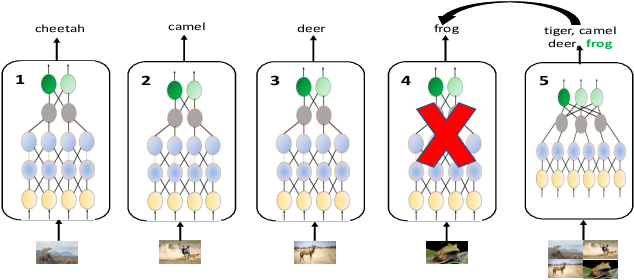
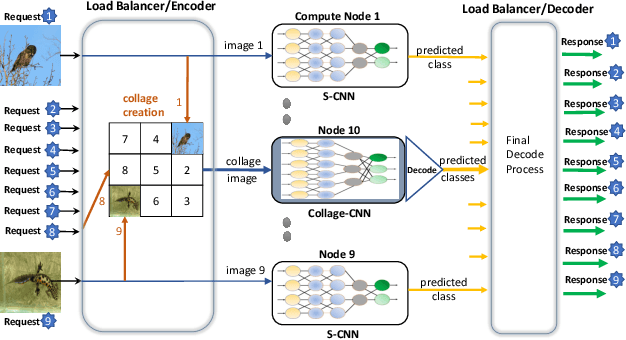
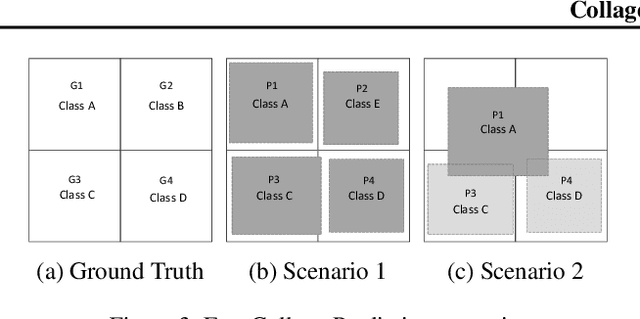
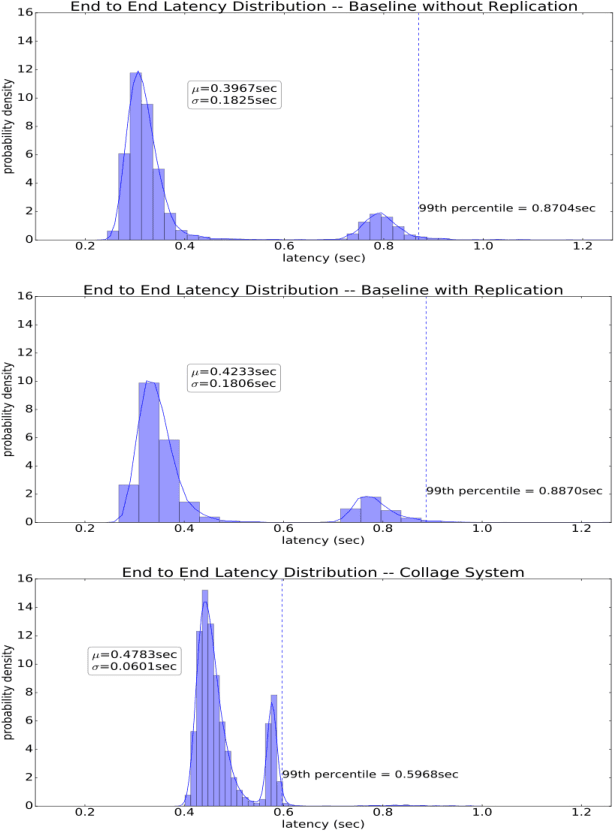
Reducing the latency variance in machine learning inference is a key requirement in many applications. Variance is harder to control in a cloud deployment in the presence of stragglers. In spite of this challenge, inference is increasingly being done in the cloud, due to the advent of affordable machine learning as a service (MLaaS) platforms. Existing approaches to reduce variance rely on replication which is expensive and partially negates the affordability of MLaaS. In this work, we argue that MLaaS platforms also provide unique opportunities to cut the cost of redundancy. In MLaaS platforms, multiple inference requests are concurrently received by a load balancer which can then create a more cost-efficient redundancy coding across a larger collection of images. We propose a novel convolutional neural network model, Collage-CNN, to provide a low-cost redundancy framework. A Collage-CNN model takes a collage formed by combining multiple images and performs multi-image classification in one shot, albeit at slightly lower accuracy. We then augment a collection of traditional single image classifiers with a single Collage-CNN classifier which acts as a low-cost redundant backup. Collage-CNN then provides backup classification results if a single image classification straggles. Deploying the Collage-CNN models in the cloud, we demonstrate that the 99th percentile tail latency of inference can be reduced by 1.47X compared to replication based approaches while providing high accuracy. Also, variation in inference latency can be reduced by 9X with a slight increase in average inference latency.
Collage Inference: Tolerating Stragglers in Distributed Neural Network Inference using Coding
Apr 27, 2019
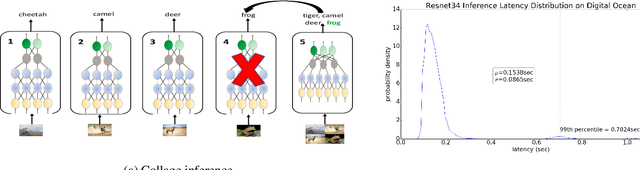

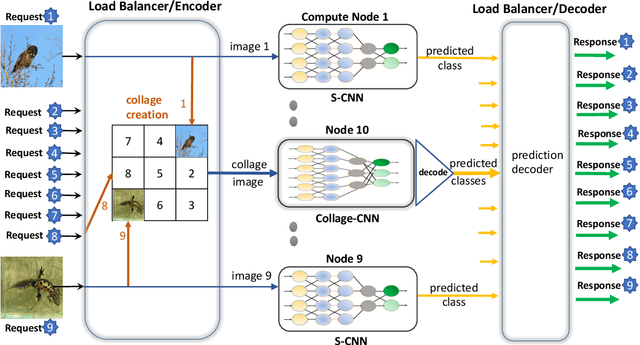
MLaaS (ML-as-a-Service) offerings by cloud computing platforms are becoming increasingly popular these days. Pre-trained machine learning models are deployed on the cloud to support prediction based applications and services. For achieving higher throughput, incoming requests are served by running multiple replicas of the model on different machines concurrently. Incidence of straggler nodes in distributed inference is a significant concern since it can increase inference latency, violate SLOs of the service. In this paper, we propose a novel coded inference model to deal with stragglers in distributed image classification. We propose modified single shot object detection models, Collage-CNN models, to provide necessary resilience efficiently. A Collage-CNN model takes collage images formed by combining multiple images as its input and performs multi-image classification in one shot. We generate custom training collages using images from standard image classification datasets and train the model to achieve high classification accuracy. Deploying the Collage-CNN models in the cloud, we demonstrate that the 99th percentile latency can be reduced by 1.45X to 2.46X compared to replication based approaches and without compromising prediction accuracy.
GradiVeQ: Vector Quantization for Bandwidth-Efficient Gradient Aggregation in Distributed CNN Training
Nov 08, 2018

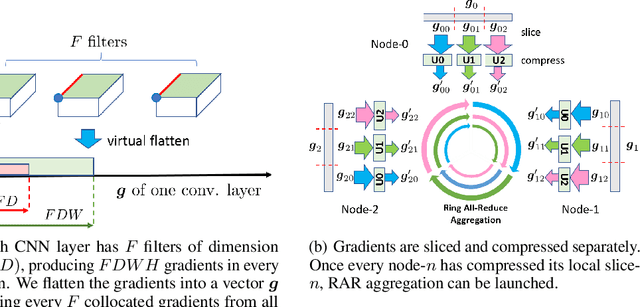
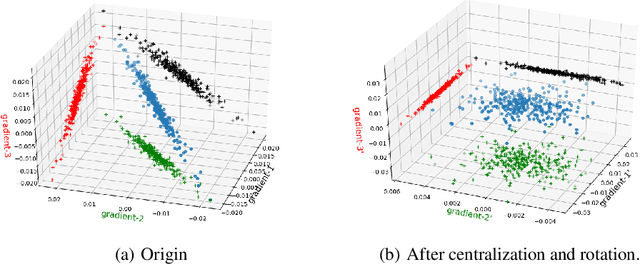
Data parallelism can boost the training speed of convolutional neural networks (CNN), but could suffer from significant communication costs caused by gradient aggregation. To alleviate this problem, several scalar quantization techniques have been developed to compress the gradients. But these techniques could perform poorly when used together with decentralized aggregation protocols like ring all-reduce (RAR), mainly due to their inability to directly aggregate compressed gradients. In this paper, we empirically demonstrate the strong linear correlations between CNN gradients, and propose a gradient vector quantization technique, named GradiVeQ, to exploit these correlations through principal component analysis (PCA) for substantial gradient dimension reduction. GradiVeQ enables direct aggregation of compressed gradients, hence allows us to build a distributed learning system that parallelizes GradiVeQ gradient compression and RAR communications. Extensive experiments on popular CNNs demonstrate that applying GradiVeQ slashes the wall-clock gradient aggregation time of the original RAR by more than 5X without noticeable accuracy loss, and reduces the end-to-end training time by almost 50%. The results also show that GradiVeQ is compatible with scalar quantization techniques such as QSGD (Quantized SGD), and achieves a much higher speed-up gain under the same compression ratio.