 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Inference in Machine Learning Services Using Trusted Execution Environments
Dec 07, 2019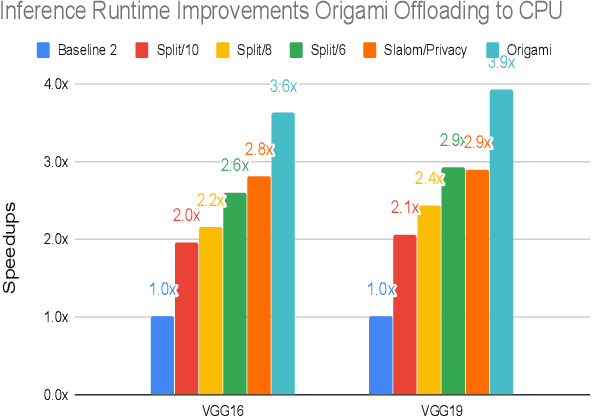
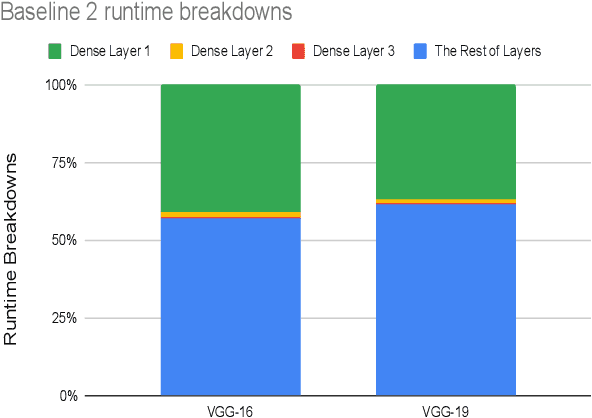
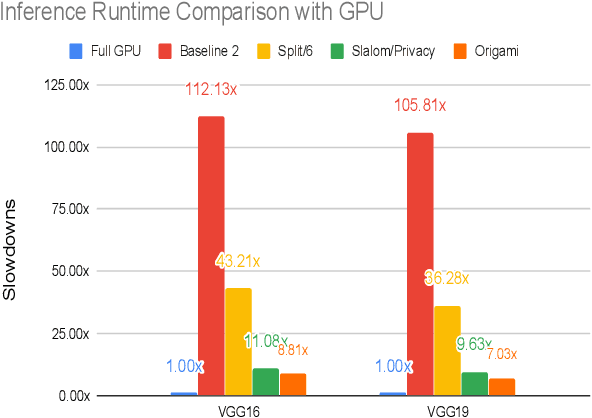
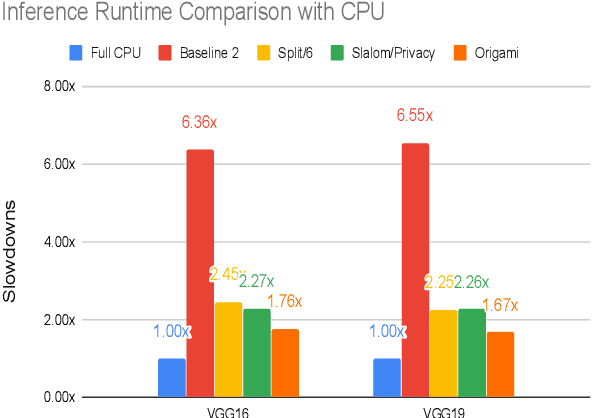
This work presents Origami, which provides privacy-preserving inference for large deep neural network (DNN) models through a combination of enclave execution, cryptographic blinding, interspersed with accelerator-based computation. Origami partitions the ML model into multiple partitions. The first partition receives the encrypted user input within an SGX enclave. The enclave decrypts the input and then applies cryptographic blinding to the input data and the model parameters. Cryptographic blinding is a technique that adds noise to obfuscate data. Origami sends the obfuscated data for computation to an untrusted GPU/CPU. The blinding and de-blinding factors are kept private by the SGX enclave, thereby preventing any adversary from denoising the data, when the computation is offloaded to a GPU/CPU. The computed output is returned to the enclave, which decodes the computation on noisy data using the unblinding factors privately stored within SGX. This process may be repeated for each DNN layer, as has been done in prior work Slalom. However, the overhead of blinding and unblinding the data is a limiting factor to scalability. Origami relies on the empirical observation that the feature maps after the first several layers can not be used, even by a powerful conditional GAN adversary to reconstruct input. Hence, Origami dynamically switches to executing the rest of the DNN layers directly on an accelerator without needing any further cryptographic blinding intervention to preserve privacy. We empirically demonstrate that using Origami, a conditional GAN adversary, even with an unlimited inference budget, cannot reconstruct the input. We implement and demonstrate the performance gains of Origami using the VGG-16 and VGG-19 models. Compared to running the entire VGG-19 model within SGX, Origami inference improves the performance of private inference from 11x while using Slalom to 15.1x.