 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Retrieval-Augmented Generation
Feb 16, 2026Retrieval-augmented generation (RAG) is a widely used framework for reducing hallucinations in large language models (LLMs) on domain-specific tasks by retrieving relevant documents from a database to support accurate responses. However, when the database contains sensitive corpora, such as medical records or legal documents, RAG poses serious privacy risks by potentially exposing private information through its outputs. Prior work has demonstrated that one can practically craft adversarial prompts that force an LLM to regurgitate the augmented contexts. A promising direction is to integrate differential privacy (DP), a privacy notion that offers strong formal guarantees, into RAG systems. However, naively applying DP mechanisms into existing systems often leads to significant utility degradation. Particularly for RAG systems, DP can reduce the usefulness of the augmented contexts leading to increase risk of hallucination from the LLMs. Motivated by these challenges, we present DP-KSA, a novel privacy-preserving RAG algorithm that integrates DP using the propose-test-release paradigm. DP-KSA follows from a key observation that most question-answering (QA) queries can be sufficiently answered with a few keywords. Hence, DP-KSA first obtains an ensemble of relevant contexts, each of which will be used to generate a response from an LLM. We utilize these responses to obtain the most frequent keywords in a differentially private manner. Lastly, the keywords are augmented into the prompt for the final output. This approach effectively compresses the semantic space while preserving both utility and privacy. We formally show that DP-KSA provides formal DP guarantees on the generated output with respect to the RAG database. We evaluate DP-KSA on two QA benchmarks using three instruction-tuned LLMs, and our empirical results demonstrate that DP-KSA achieves a strong privacy-utility tradeoff.
LRD-MPC: Efficient MPC Inference through Low-rank Decomposition
Feb 16, 2026Secure Multi-party Computation (MPC) enables untrusted parties to jointly compute a function without revealing their inputs. Its application to machine learning (ML) has gained significant attention, particularly for secure inference services deployed across multiple cloud virtual machines (VMs), where each VM acts as an MPC party. Model providers secret-share model weights, and users secret-share inputs, ensuring that each server operates only on random shares. While MPC provides strong cryptographic guarantees, it incurs substantial computational and communication overhead. Deep neural networks rely heavily on convolutional and fully connected layers, which require costly matrix multiplications in MPC. To reduce this cost, we propose leveraging low-rank decomposition (LRD) for linear layers, replacing one large matrix multiplication with two smaller ones. Each matrix multiplication in MPC incurs a round of communication, meaning decomposing one matrix multiplication into two leads to an additional communication round. Second, the added matrix multiplication requires an additional truncation step to maintain numerical precision. Since truncation itself requires communication and computation, these overheads can offset the gains from decomposition. To address this, we introduce two complementary optimizations: truncation skipping and efficient linear layer concatenation. Truncation skipping removes the extra truncation induced by LRD, while linear layer concatenation pipelines operations to hide the additional communication round. Together, these techniques mitigate the main overheads of LRD in MPC and improve overall efficiency. Our approach is broadly applicable across MPC protocols. Experiments show up to 25% speedup in n-PC and 33% in 3-PC protocols over full-rank baselines, along with up to 52% GPU energy savings and 88% reduction in offline-phase latency.
MPC-Pipe: an Efficient Pipeline Scheme for Secure Multi-party Machine Learning Inference
Sep 27, 2022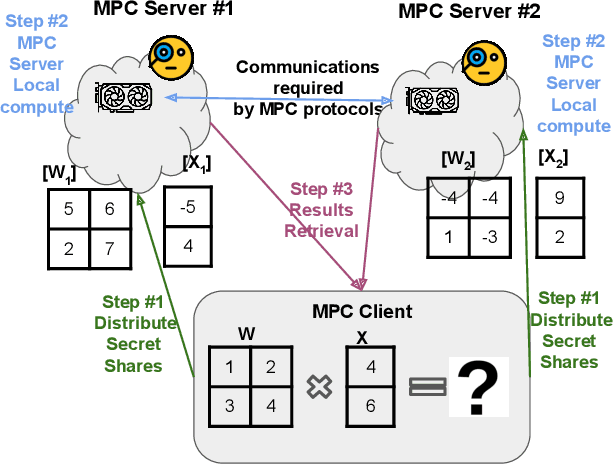
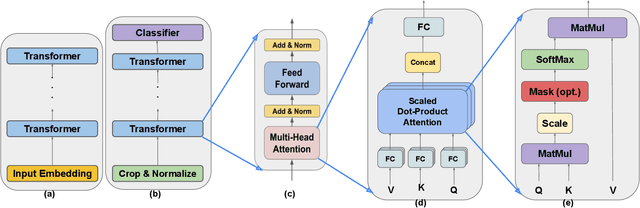
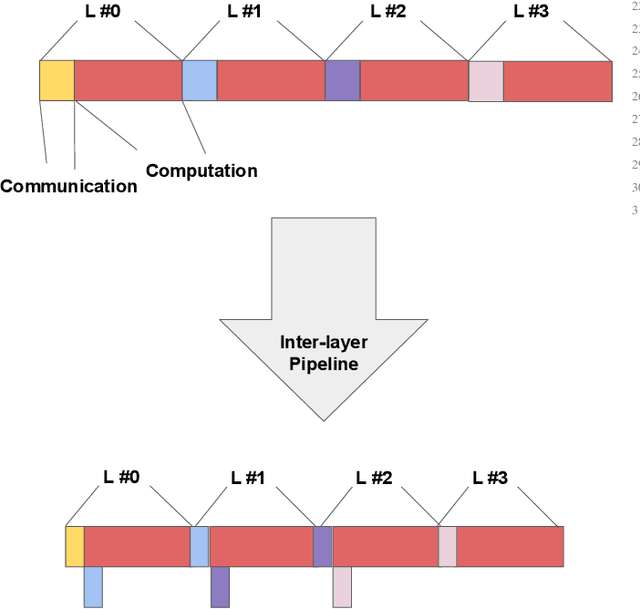
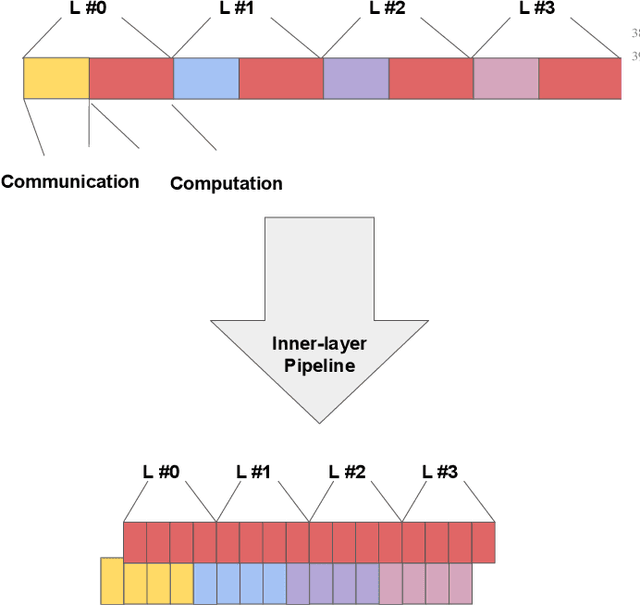
Multi-party computing (MPC) has been gaining popularity over the past years as a secure computing model, particularly for machine learning (ML) inference. Compared with its competitors, MPC has fewer overheads than homomorphic encryption (HE) and has a more robust threat model than hardware-based trusted execution environments (TEE) such as Intel SGX. Despite its apparent advantages, MPC protocols still pay substantial performance penalties compared to plaintext when applied to ML algorithms. The overhead is due to added computation and communication costs. For multiplications that are ubiquitous in ML algorithms, MPC protocols add 32x more computational costs and 1 round of broadcasting among MPC servers. Moreover, ML computations that have trivial costs in plaintext, such as Softmax, ReLU, and other non-linear operations become very expensive due to added communication. Those added overheads make MPC less palatable to deploy in real-time ML inference frameworks, such as speech translation. In this work, we present MPC-Pipe, an MPC pipeline inference technique that uses two ML-specific approaches. 1) inter-linear-layer pipeline and 2) inner layer pipeline. Those two techniques shorten the total inference runtime for machine learning models. Our experiments have shown to reduce ML inference latency by up to 12.6% when model weights are private and 14.48\% when model weights are public, compared to current MPC protocol implementations.
DarKnight: An Accelerated Framework for Privacy and Integrity Preserving Deep Learning Using Trusted Hardware
Jun 30, 2022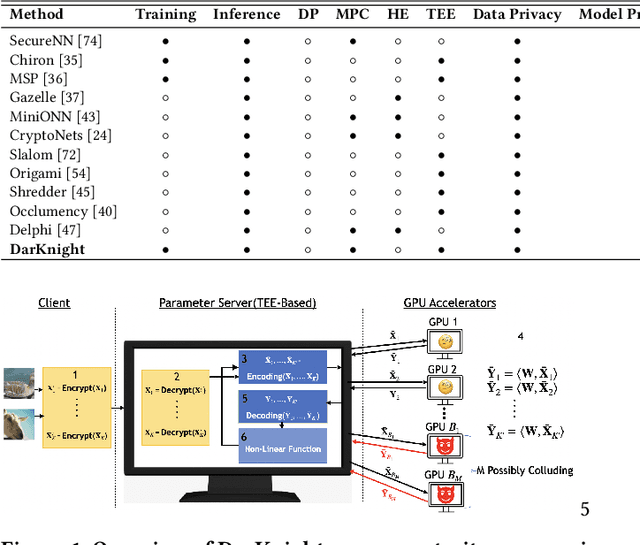

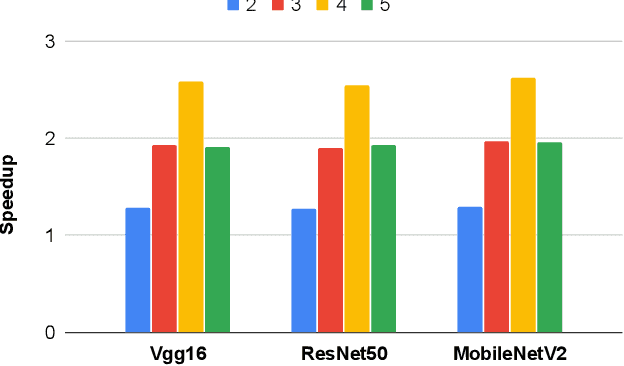
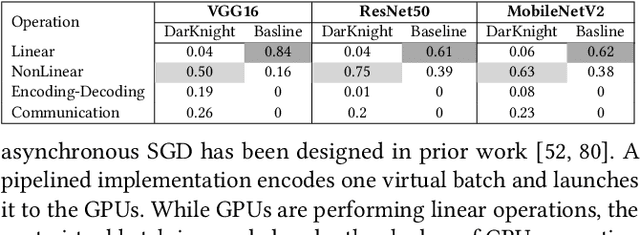
Privacy and security-related concerns are growing as machine learning reaches diverse application domains. The data holders want to train or infer with private data while exploiting accelerators, such as GPUs, that are hosted in the cloud. Cloud systems are vulnerable to attackers that compromise the privacy of data and integrity of computations. Tackling such a challenge requires unifying theoretical privacy algorithms with hardware security capabilities. This paper presents DarKnight, a framework for large DNN training while protecting input privacy and computation integrity. DarKnight relies on cooperative execution between trusted execution environments (TEE) and accelerators, where the TEE provides privacy and integrity verification, while accelerators perform the bulk of the linear algebraic computation to optimize the performance. In particular, DarKnight uses a customized data encoding strategy based on matrix masking to create input obfuscation within a TEE. The obfuscated data is then offloaded to GPUs for fast linear algebraic computation. DarKnight's data obfuscation strategy provides provable data privacy and computation integrity in the cloud servers. While prior works tackle inference privacy and cannot be utilized for training, DarKnight's encoding scheme is designed to support both training and inference.
Byzantine-Robust and Privacy-Preserving Framework for FedML
May 05, 2021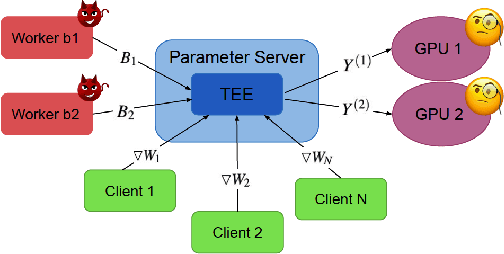
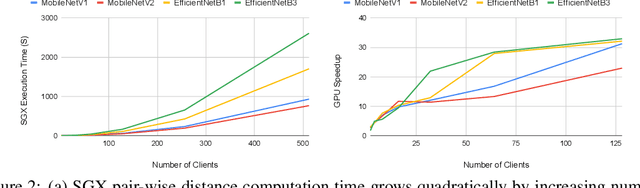
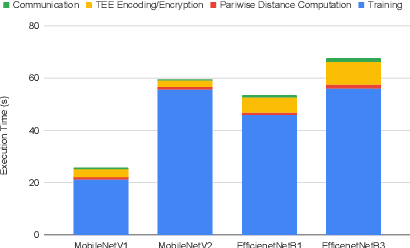
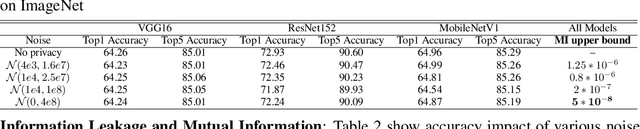
Federated learning has emerged as a popular paradigm for collaboratively training a model from data distributed among a set of clients. This learning setting presents, among others, two unique challenges: how to protect privacy of the clients' data during training, and how to ensure integrity of the trained model. We propose a two-pronged solution that aims to address both challenges under a single framework. First, we propose to create secure enclaves using a trusted execution environment (TEE) within the server. Each client can then encrypt their gradients and send them to verifiable enclaves. The gradients are decrypted within the enclave without the fear of privacy breaches. However, robustness check computations in a TEE are computationally prohibitive. Hence, in the second step, we perform a novel gradient encoding that enables TEEs to encode the gradients and then offloading Byzantine check computations to accelerators such as GPUs. Our proposed approach provides theoretical bounds on information leakage and offers a significant speed-up over the baseline in empirical evaluation.
Privacy and Integrity Preserving Training Using Trusted Hardware
May 01, 2021
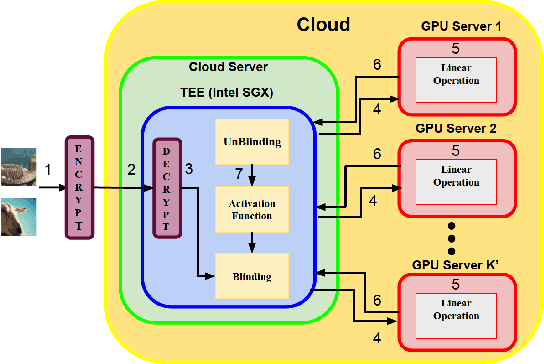
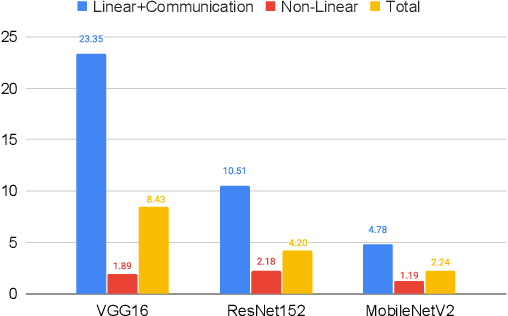
Privacy and security-related concerns are growing as machine learning reaches diverse application domains. The data holders want to train with private data while exploiting accelerators, such as GPUs, that are hosted in the cloud. However, Cloud systems are vulnerable to attackers that compromise the privacy of data and integrity of computations. This work presents DarKnight, a framework for large DNN training while protecting input privacy and computation integrity. DarKnight relies on cooperative execution between trusted execution environments (TEE) and accelerators, where the TEE provides privacy and integrity verification, while accelerators perform the computation heavy linear algebraic operations.
Privacy-Preserving Inference in Machine Learning Services Using Trusted Execution Environments
Dec 07, 2019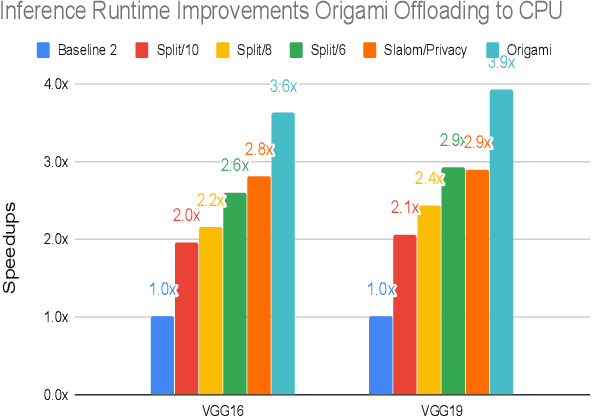
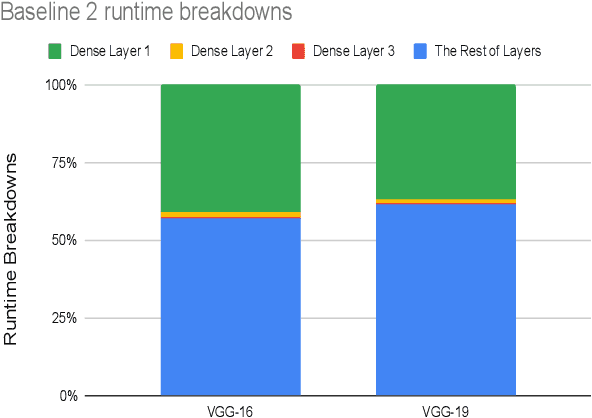
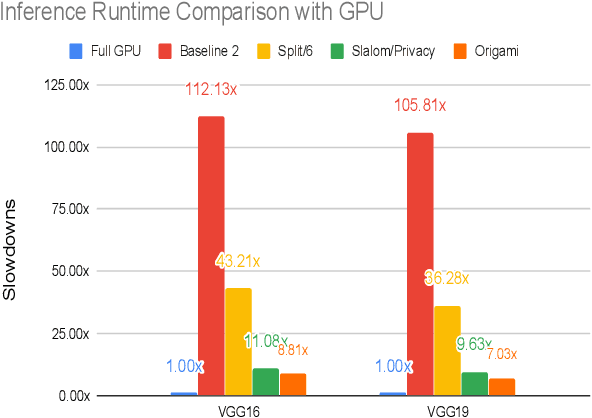
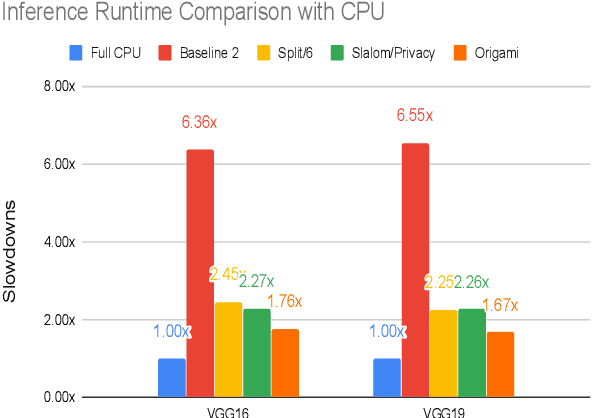
This work presents Origami, which provides privacy-preserving inference for large deep neural network (DNN) models through a combination of enclave execution, cryptographic blinding, interspersed with accelerator-based computation. Origami partitions the ML model into multiple partitions. The first partition receives the encrypted user input within an SGX enclave. The enclave decrypts the input and then applies cryptographic blinding to the input data and the model parameters. Cryptographic blinding is a technique that adds noise to obfuscate data. Origami sends the obfuscated data for computation to an untrusted GPU/CPU. The blinding and de-blinding factors are kept private by the SGX enclave, thereby preventing any adversary from denoising the data, when the computation is offloaded to a GPU/CPU. The computed output is returned to the enclave, which decodes the computation on noisy data using the unblinding factors privately stored within SGX. This process may be repeated for each DNN layer, as has been done in prior work Slalom. However, the overhead of blinding and unblinding the data is a limiting factor to scalability. Origami relies on the empirical observation that the feature maps after the first several layers can not be used, even by a powerful conditional GAN adversary to reconstruct input. Hence, Origami dynamically switches to executing the rest of the DNN layers directly on an accelerator without needing any further cryptographic blinding intervention to preserve privacy. We empirically demonstrate that using Origami, a conditional GAN adversary, even with an unlimited inference budget, cannot reconstruct the input. We implement and demonstrate the performance gains of Origami using the VGG-16 and VGG-19 models. Compared to running the entire VGG-19 model within SGX, Origami inference improves the performance of private inference from 11x while using Slalom to 15.1x.