 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPC-Pipe: an Efficient Pipeline Scheme for Secure Multi-party Machine Learning Inference
Sep 27, 2022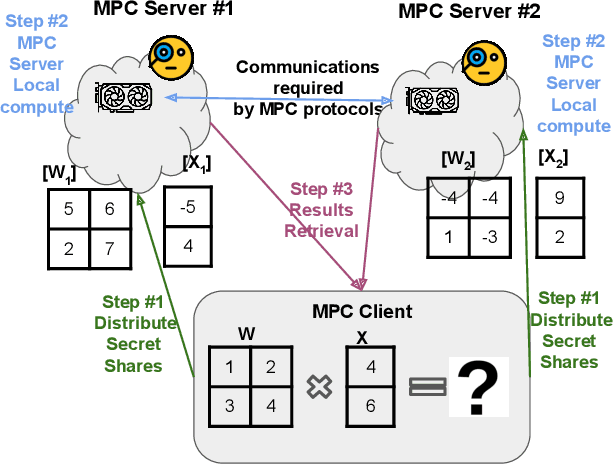
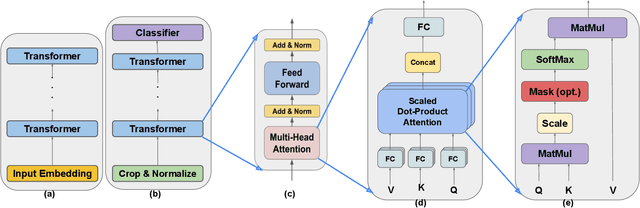
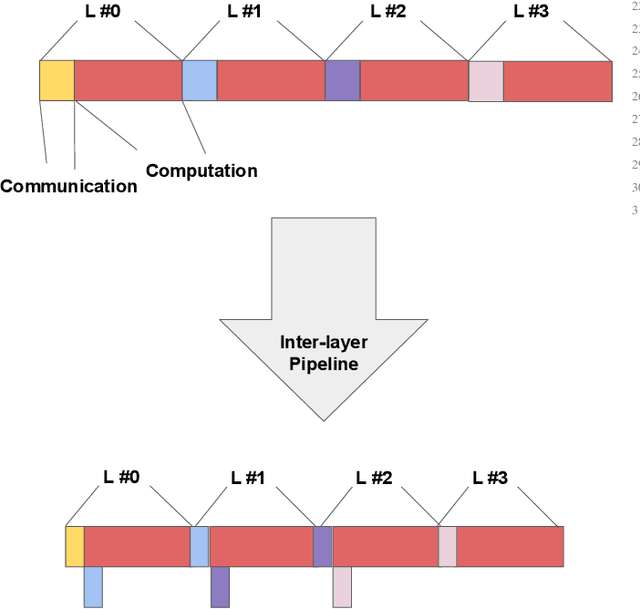
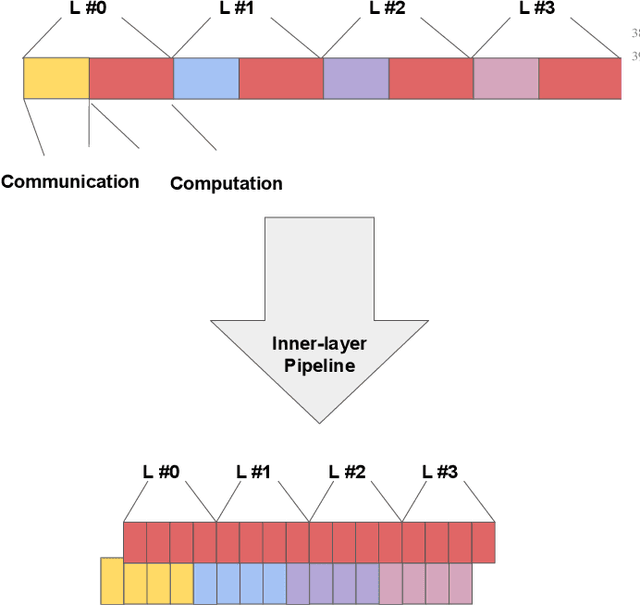
Multi-party computing (MPC) has been gaining popularity over the past years as a secure computing model, particularly for machine learning (ML) inference. Compared with its competitors, MPC has fewer overheads than homomorphic encryption (HE) and has a more robust threat model than hardware-based trusted execution environments (TEE) such as Intel SGX. Despite its apparent advantages, MPC protocols still pay substantial performance penalties compared to plaintext when applied to ML algorithms. The overhead is due to added computation and communication costs. For multiplications that are ubiquitous in ML algorithms, MPC protocols add 32x more computational costs and 1 round of broadcasting among MPC servers. Moreover, ML computations that have trivial costs in plaintext, such as Softmax, ReLU, and other non-linear operations become very expensive due to added communication. Those added overheads make MPC less palatable to deploy in real-time ML inference frameworks, such as speech translation. In this work, we present MPC-Pipe, an MPC pipeline inference technique that uses two ML-specific approaches. 1) inter-linear-layer pipeline and 2) inner layer pipeline. Those two techniques shorten the total inference runtime for machine learning models. Our experiments have shown to reduce ML inference latency by up to 12.6% when model weights are private and 14.48\% when model weights are public, compared to current MPC protocol implementations.