 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Heavy Hitter Detection using Federated Analytics
Jul 21, 2023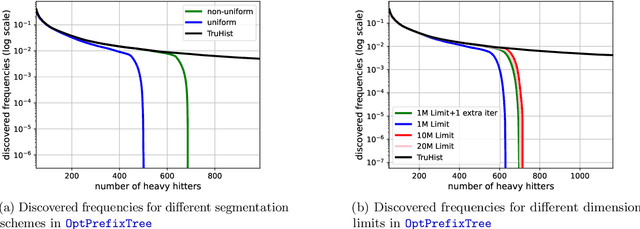
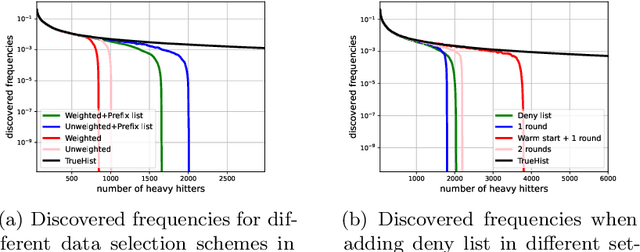

In this work, we study practical heuristics to improve the performance of prefix-tree based algorithms for differentially private heavy hitter detection. Our model assumes each user has multiple data points and the goal is to learn as many of the most frequent data points as possible across all users' data with aggregate and local differential privacy. We propose an adaptive hyperparameter tuning algorithm that improves the performance of the algorithm while satisfying computational, communication and privacy constraints. We explore the impact of different data-selection schemes as well as the impact of introducing deny lists during multiple runs of the algorithm. We test these improvements using extensive experimentation on the Reddit dataset~\cite{caldas2018leaf} on the task of learning the most frequent words.
Data Leakage via Access Patterns of Sparse Features in Deep Learning-based Recommendation Systems
Dec 12, 2022Online personalized recommendation services are generally hosted in the cloud where users query the cloud-based model to receive recommended input such as merchandise of interest or news feed. State-of-the-art recommendation models rely on sparse and dense features to represent users' profile information and the items they interact with. Although sparse features account for 99% of the total model size, there was not enough attention paid to the potential information leakage through sparse features. These sparse features are employed to track users' behavior, e.g., their click history, object interactions, etc., potentially carrying each user's private information. Sparse features are represented as learned embedding vectors that are stored in large tables, and personalized recommendation is performed by using a specific user's sparse feature to index through the tables. Even with recently-proposed methods that hides the computation happening in the cloud, an attacker in the cloud may be able to still track the access patterns to the embedding tables. This paper explores the private information that may be learned by tracking a recommendation model's sparse feature access patterns. We first characterize the types of attacks that can be carried out on sparse features in recommendation models in an untrusted cloud, followed by a demonstration of how each of these attacks leads to extracting users' private information or tracking users by their behavior over time.
DarKnight: An Accelerated Framework for Privacy and Integrity Preserving Deep Learning Using Trusted Hardware
Jun 30, 2022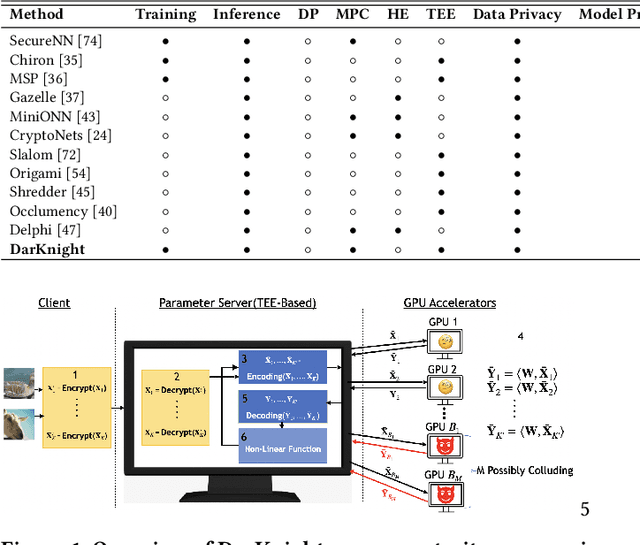

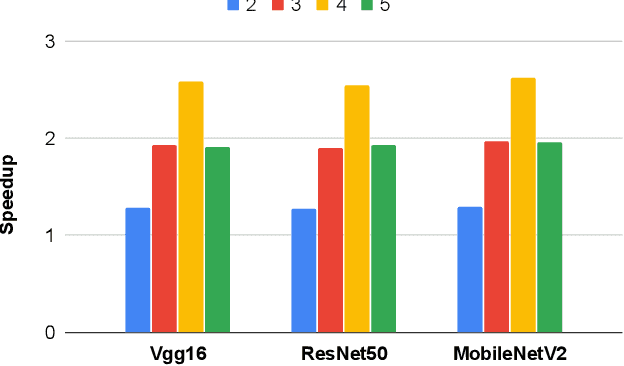
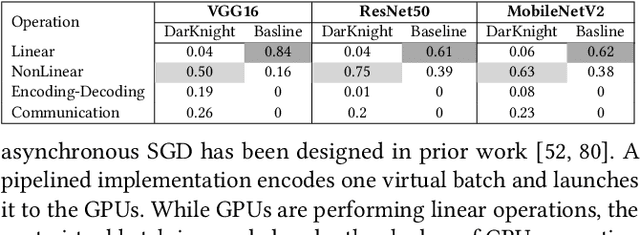
Privacy and security-related concerns are growing as machine learning reaches diverse application domains. The data holders want to train or infer with private data while exploiting accelerators, such as GPUs, that are hosted in the cloud. Cloud systems are vulnerable to attackers that compromise the privacy of data and integrity of computations. Tackling such a challenge requires unifying theoretical privacy algorithms with hardware security capabilities. This paper presents DarKnight, a framework for large DNN training while protecting input privacy and computation integrity. DarKnight relies on cooperative execution between trusted execution environments (TEE) and accelerators, where the TEE provides privacy and integrity verification, while accelerators perform the bulk of the linear algebraic computation to optimize the performance. In particular, DarKnight uses a customized data encoding strategy based on matrix masking to create input obfuscation within a TEE. The obfuscated data is then offloaded to GPUs for fast linear algebraic computation. DarKnight's data obfuscation strategy provides provable data privacy and computation integrity in the cloud servers. While prior works tackle inference privacy and cannot be utilized for training, DarKnight's encoding scheme is designed to support both training and inference.
Attribute Inference Attack of Speech Emotion Recognition in Federated Learning Settings
Dec 26, 2021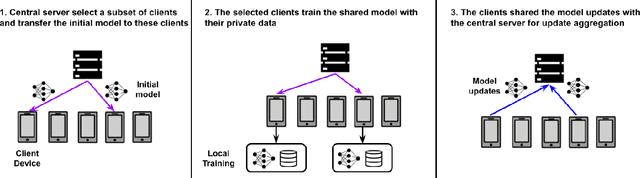
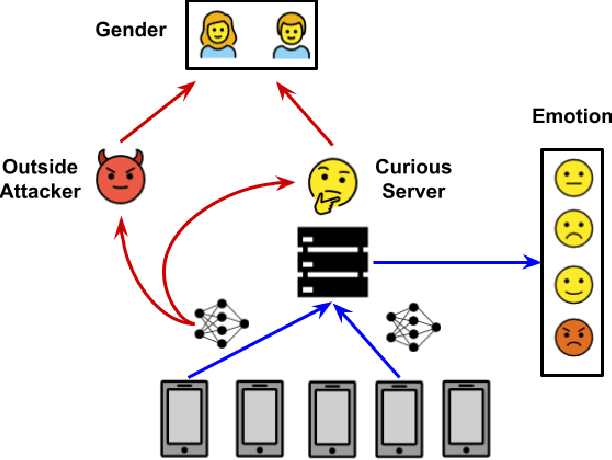
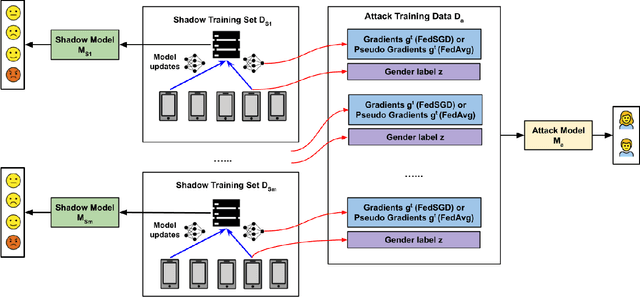
Speech emotion recognition (SER) processes speech signals to detect and characterize expressed perceived emotions. Many SER application systems often acquire and transmit speech data collected at the client-side to remote cloud platforms for inference and decision making. However, speech data carry rich information not only about emotions conveyed in vocal expressions, but also other sensitive demographic traits such as gender, age and language background. Consequently, it is desirable for SER systems to have the ability to classify emotion constructs while preventing unintended/improper inferences of sensitive and demographic information. Federated learning (FL) is a distributed machine learning paradigm that coordinates clients to train a model collaboratively without sharing their local data. This training approach appears secure and can improve privacy for SER. However, recent works have demonstrated that FL approaches are still vulnerable to various privacy attacks like reconstruction attacks and membership inference attacks. Although most of these have focused on computer vision applications, such information leakages exist in the SER systems trained using the FL technique. To assess the information leakage of SER systems trained using FL, we propose an attribute inference attack framework that infers sensitive attribute information of the clients from shared gradients or model parameters, corresponding to the FedSGD and the FedAvg training algorithms, respectively. As a use case, we empirically evaluate our approach for predicting the client's gender information using three SER benchmark datasets: IEMOCAP, CREMA-D, and MSP-Improv. We show that the attribute inference attack is achievable for SER systems trained using FL. We further identify that most information leakage possibly comes from the first layer in the SER model.
Verifiable Coded Computing: Towards Fast, Secure and Private Distributed Machine Learning
Jul 27, 2021
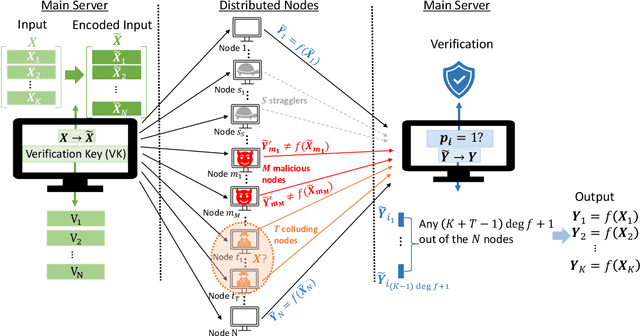
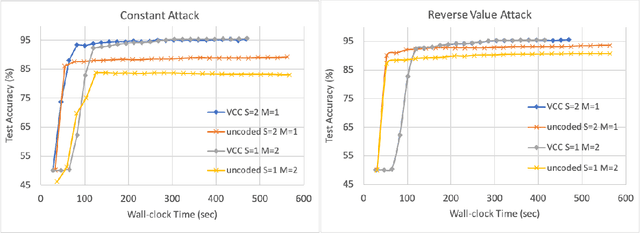
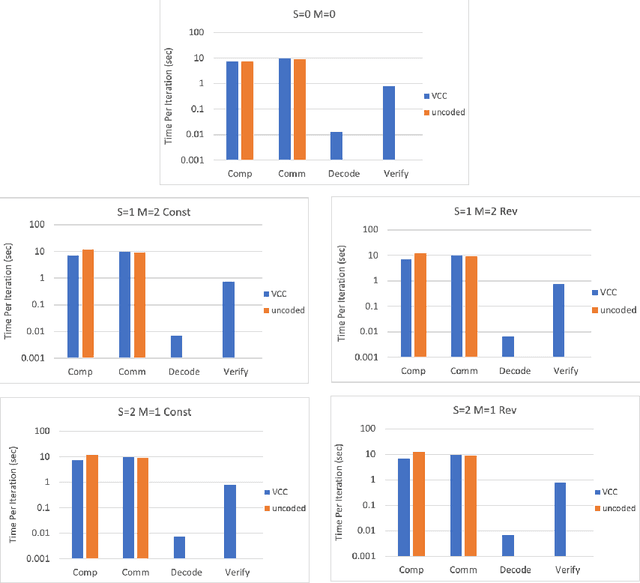
Stragglers, Byzantine workers, and data privacy are the main bottlenecks in distributed cloud computing. Several prior works proposed coded computing strategies to jointly address all three challenges. They require either a large number of workers, a significant communication cost or a significant computational complexity to tolerate malicious workers. Much of the overhead in prior schemes comes from the fact that they tightly couple coding for all three problems into a single framework. In this work, we propose Verifiable Coded Computing (VCC) framework that decouples Byzantine node detection challenge from the straggler tolerance. VCC leverages coded computing just for handling stragglers and privacy, and then uses an orthogonal approach of verifiable computing to tackle Byzantine nodes. Furthermore, VCC dynamically adapts its coding scheme to tradeoff straggler tolerance with Byzantine protection and vice-versa. We evaluate VCC on compute intensive distributed logistic regression application. Our experiments show that VCC speeds up the conventional uncoded implementation of distributed logistic regression by $3.2\times-6.9\times$, and also improves the test accuracy by up to $12.6\%$.
Byzantine-Robust and Privacy-Preserving Framework for FedML
May 05, 2021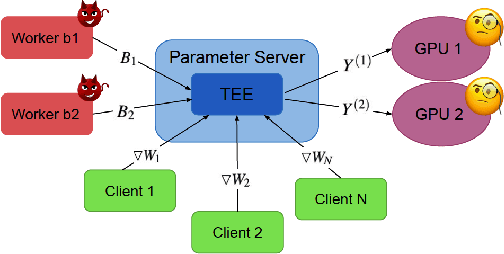
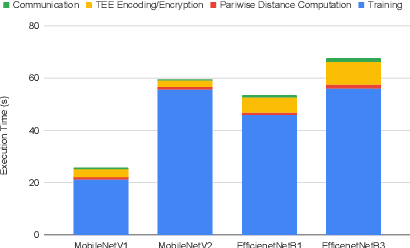
Federated learning has emerged as a popular paradigm for collaboratively training a model from data distributed among a set of clients. This learning setting presents, among others, two unique challenges: how to protect privacy of the clients' data during training, and how to ensure integrity of the trained model. We propose a two-pronged solution that aims to address both challenges under a single framework. First, we propose to create secure enclaves using a trusted execution environment (TEE) within the server. Each client can then encrypt their gradients and send them to verifiable enclaves. The gradients are decrypted within the enclave without the fear of privacy breaches. However, robustness check computations in a TEE are computationally prohibitive. Hence, in the second step, we perform a novel gradient encoding that enables TEEs to encode the gradients and then offloading Byzantine check computations to accelerators such as GPUs. Our proposed approach provides theoretical bounds on information leakage and offers a significant speed-up over the baseline in empirical evaluation.
Privacy and Integrity Preserving Training Using Trusted Hardware
May 01, 2021
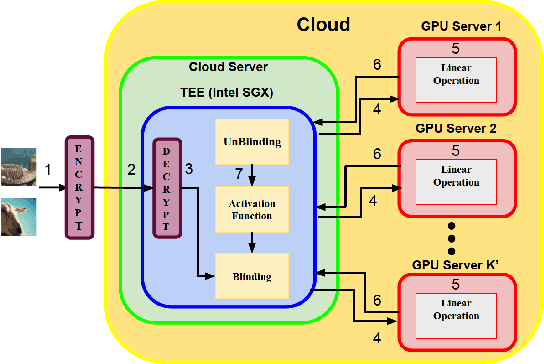
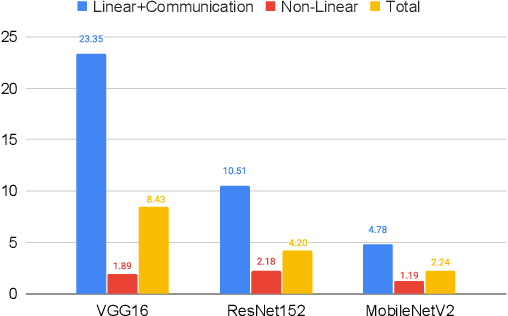
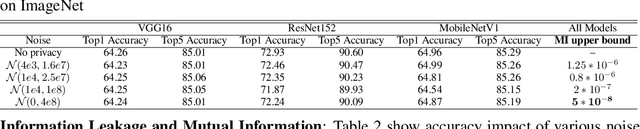
Privacy and security-related concerns are growing as machine learning reaches diverse application domains. The data holders want to train with private data while exploiting accelerators, such as GPUs, that are hosted in the cloud. However, Cloud systems are vulnerable to attackers that compromise the privacy of data and integrity of computations. This work presents DarKnight, a framework for large DNN training while protecting input privacy and computation integrity. DarKnight relies on cooperative execution between trusted execution environments (TEE) and accelerators, where the TEE provides privacy and integrity verification, while accelerators perform the computation heavy linear algebraic operations.