 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sustainable AI Economy Needs Data Deals That Work for Generators
Jan 15, 2026We argue that the machine learning value chain is structurally unsustainable due to an economic data processing inequality: each state in the data cycle from inputs to model weights to synthetic outputs refines technical signal but strips economic equity from data generators. We show, by analyzing seventy-three public data deals, that the majority of value accrues to aggregators, with documented creator royalties rounding to zero and widespread opacity of deal terms. This is not just an economic welfare concern: as data and its derivatives become economic assets, the feedback loop that sustains current learning algorithms is at risk. We identify three structural faults - missing provenance, asymmetric bargaining power, and non-dynamic pricing - as the operational machinery of this inequality. In our analysis, we trace these problems along the machine learning value chain and propose an Equitable Data-Value Exchange (EDVEX) Framework to enable a minimal market that benefits all participants. Finally, we outline research directions where our community can make concrete contributions to data deals and contextualize our position with related and orthogonal viewpoints.
Towards Reinforcement Learning for Exploration of Speculative Execution Vulnerabilities
Feb 24, 2025Speculative attacks such as Spectre can leak secret information without being discovered by the operating system. Speculative execution vulnerabilities are finicky and deep in the sense that to exploit them, it requires intensive manual labor and intimate knowledge of the hardware. In this paper, we introduce SpecRL, a framework that utilizes reinforcement learning to find speculative execution leaks in post-silicon (black box) microprocessors.
Information Flow Control in Machine Learning through Modular Model Architecture
Jun 05, 2023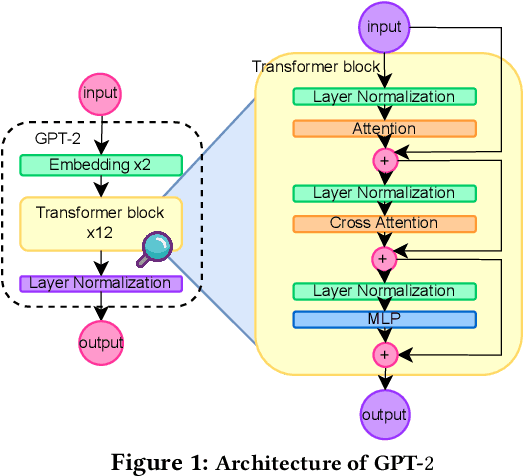
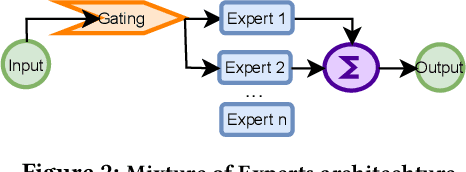

In today's machine learning (ML) models, any part of the training data can affect its output. This lack of control for information flow from training data to model output is a major obstacle in training models on sensitive data when access control only allows individual users to access a subset of data. To enable secure machine learning for access controlled data, we propose the notion of information flow control for machine learning, and develop a secure Transformer-based language model based on the Mixture-of-Experts (MoE) architecture. The secure MoE architecture controls information flow by limiting the influence of training data from each security domain to a single expert module, and only enabling a subset of experts at inference time based on an access control policy. The evaluation using a large corpus of text data shows that the proposed MoE architecture has minimal (1.9%) performance overhead and can significantly improve model accuracy (up to 37%) by enabling training on access-controlled data.
GPU-based Private Information Retrieval for On-Device Machine Learning Inference
Jan 27, 2023



On-device machine learning (ML) inference can enable the use of private user data on user devices without remote servers. However, a pure on-device solution to private ML inference is impractical for many applications that rely on embedding tables that are too large to be stored on-device. To overcome this barrier, we propose the use of private information retrieval (PIR) to efficiently and privately retrieve embeddings from servers without sharing any private information during on-device ML inference. As off-the-shelf PIR algorithms are usually too computationally intensive to directly use for latency-sensitive inference tasks, we 1) develop a novel algorithm for accelerating PIR on GPUs, and 2) co-design PIR with the downstream ML application to obtain further speedup. Our GPU acceleration strategy improves system throughput by more than $20 \times$ over an optimized CPU PIR implementation, and our co-design techniques obtain over $5 \times$ additional throughput improvement at fixed model quality. Together, on various on-device ML applications such as recommendation and language modeling, our system on a single V100 GPU can serve up to $100,000$ queries per second -- a $>100 \times$ throughput improvement over a naively implemented system -- while maintaining model accuracy, and limiting inference communication and response latency to within $300$KB and $<100$ms respectively.
Data Leakage via Access Patterns of Sparse Features in Deep Learning-based Recommendation Systems
Dec 12, 2022Online personalized recommendation services are generally hosted in the cloud where users query the cloud-based model to receive recommended input such as merchandise of interest or news feed. State-of-the-art recommendation models rely on sparse and dense features to represent users' profile information and the items they interact with. Although sparse features account for 99% of the total model size, there was not enough attention paid to the potential information leakage through sparse features. These sparse features are employed to track users' behavior, e.g., their click history, object interactions, etc., potentially carrying each user's private information. Sparse features are represented as learned embedding vectors that are stored in large tables, and personalized recommendation is performed by using a specific user's sparse feature to index through the tables. Even with recently-proposed methods that hides the computation happening in the cloud, an attacker in the cloud may be able to still track the access patterns to the embedding tables. This paper explores the private information that may be learned by tracking a recommendation model's sparse feature access patterns. We first characterize the types of attacks that can be carried out on sparse features in recommendation models in an untrusted cloud, followed by a demonstration of how each of these attacks leads to extracting users' private information or tracking users by their behavior over time.
MPCViT: Searching for MPC-friendly Vision Transformer with Heterogeneous Attention
Nov 25, 2022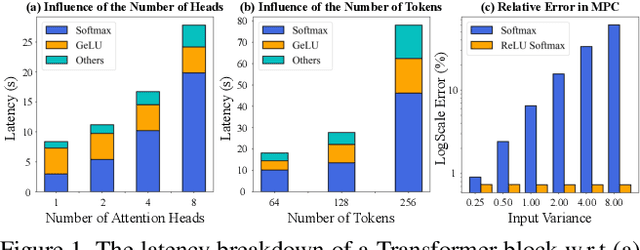

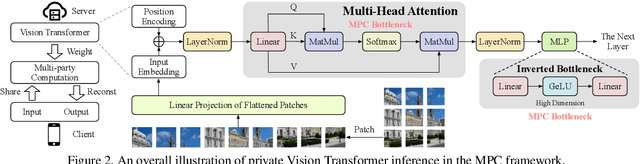
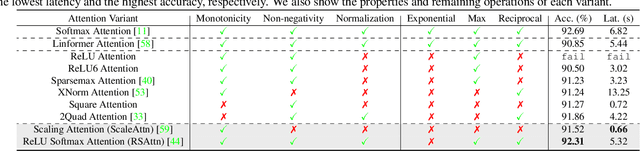
Secure multi-party computation (MPC) enables computation directly on encrypted data on non-colluding untrusted servers and protects both data and model privacy in deep learning inference. However, existing neural network (NN) architectures, including Vision Transformers (ViTs), are not designed or optimized for MPC protocols and incur significant latency overhead due to the Softmax function in the multi-head attention (MHA). In this paper, we propose an MPC-friendly ViT, dubbed MPCViT, to enable accurate yet efficient ViT inference in MPC. We systematically compare different attention variants in MPC and propose a heterogeneous attention search space, which combines the high-accuracy and MPC-efficient attentions with diverse structure granularities. We further propose a simple yet effective differentiable neural architecture search (NAS) algorithm for fast ViT optimization. MPCViT significantly outperforms prior-art ViT variants in MPC. With the proposed NAS algorithm, our extensive experiments demonstrate that MPCViT achieves 7.9x and 2.8x latency reduction with better accuracy compared to Linformer and MPCFormer on the Tiny-ImageNet dataset, respectively. Further, with proper knowledge distillation (KD), MPCViT even achieves 1.9% better accuracy compared to the baseline ViT with 9.9x latency reduction on the Tiny-ImageNet dataset.
Cocktail Party Attack: Breaking Aggregation-Based Privacy in Federated Learning using Independent Component Analysis
Sep 12, 2022


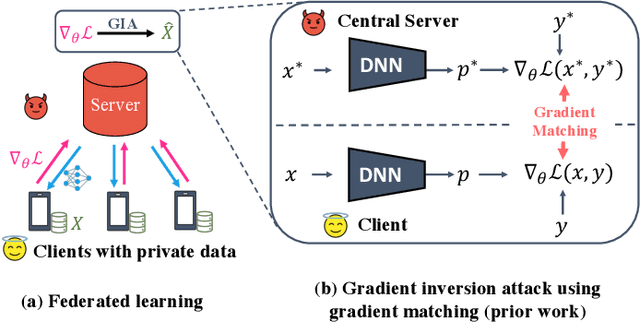
Federated learning (FL) aims to perform privacy-preserving machine learning on distributed data held by multiple data owners. To this end, FL requires the data owners to perform training locally and share the gradient updates (instead of the private inputs) with the central server, which are then securely aggregated over multiple data owners. Although aggregation by itself does not provably offer privacy protection, prior work showed that it may suffice if the batch size is sufficiently large. In this paper, we propose the Cocktail Party Attack (CPA) that, contrary to prior belief, is able to recover the private inputs from gradients aggregated over a very large batch size. CPA leverages the crucial insight that aggregate gradients from a fully connected layer is a linear combination of its inputs, which leads us to frame gradient inversion as a blind source separation (BSS) problem (informally called the cocktail party problem). We adapt independent component analysis (ICA)--a classic solution to the BSS problem--to recover private inputs for fully-connected and convolutional networks, and show that CPA significantly outperforms prior gradient inversion attacks, scales to ImageNet-sized inputs, and works on large batch sizes of up to 1024.