 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-Level Analysis of Leakage Risk of Training Data in Large Language Models
Dec 15, 2024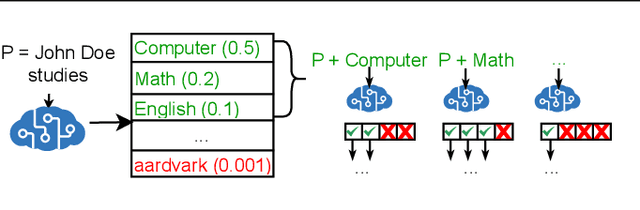



This work advocates for the use of sequence level probabilities for quantifying the risk of extraction training data from Large Language Models (LLMs) as they provide much finer-grained information than has been previously obtained. We re-analyze the effects of decoding schemes, model-size, prefix length, partial sequence leakages, and token positions to uncover new insights that have were not possible in prior work due to their choice of metrics. We perform this study on two pre-trained models, LLaMa and OPT, trained on the Common Crawl and Pile respectively. We discover that 1) Extraction rate, the predominant metric used in prior quantification work, underestimates the threat of leakage of training data in randomized LLMs by as much as 2.14x. 2) Though, on average, larger models and longer prefixes can extract more data, this is not true with a substantial portion of individual sequences. 30.4-41.5% of our sequences are easier to extract with either shorter prefixes or smaller models. 3) Contrary to prior belief, partial leakage in the commonly used decoding schemes like top-k and top-p are not easier than leaking verbatim training data. 4) Extracting later tokens in a sequence is as much as 912% easier than extracting earlier tokens. The insights gained from our analysis show that it is important to look at leakage of training data on a per-sequence basis.
Information Flow Control in Machine Learning through Modular Model Architecture
Jun 05, 2023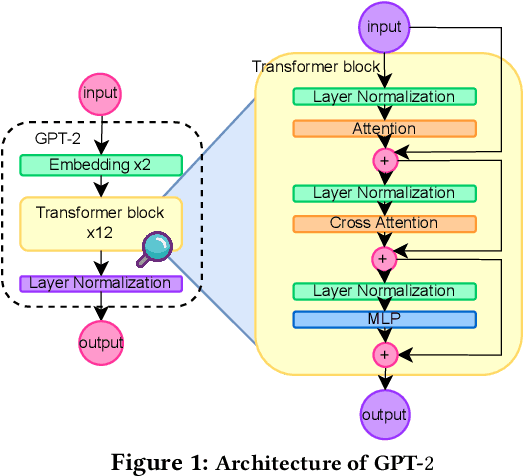
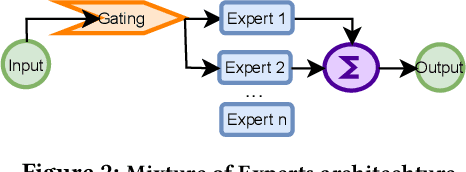

In today's machine learning (ML) models, any part of the training data can affect its output. This lack of control for information flow from training data to model output is a major obstacle in training models on sensitive data when access control only allows individual users to access a subset of data. To enable secure machine learning for access controlled data, we propose the notion of information flow control for machine learning, and develop a secure Transformer-based language model based on the Mixture-of-Experts (MoE) architecture. The secure MoE architecture controls information flow by limiting the influence of training data from each security domain to a single expert module, and only enabling a subset of experts at inference time based on an access control policy. The evaluation using a large corpus of text data shows that the proposed MoE architecture has minimal (1.9%) performance overhead and can significantly improve model accuracy (up to 37%) by enabling training on access-controlled data.