 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Flow Control in Machine Learning through Modular Model Architecture
Jun 05, 2023

In today's machine learning (ML) models, any part of the training data can affect its output. This lack of control for information flow from training data to model output is a major obstacle in training models on sensitive data when access control only allows individual users to access a subset of data. To enable secure machine learning for access controlled data, we propose the notion of information flow control for machine learning, and develop a secure Transformer-based language model based on the Mixture-of-Experts (MoE) architecture. The secure MoE architecture controls information flow by limiting the influence of training data from each security domain to a single expert module, and only enabling a subset of experts at inference time based on an access control policy. The evaluation using a large corpus of text data shows that the proposed MoE architecture has minimal (1.9%) performance overhead and can significantly improve model accuracy (up to 37%) by enabling training on access-controlled data.
Structured Pruning is All You Need for Pruning CNNs at Initialization
Mar 04, 2022
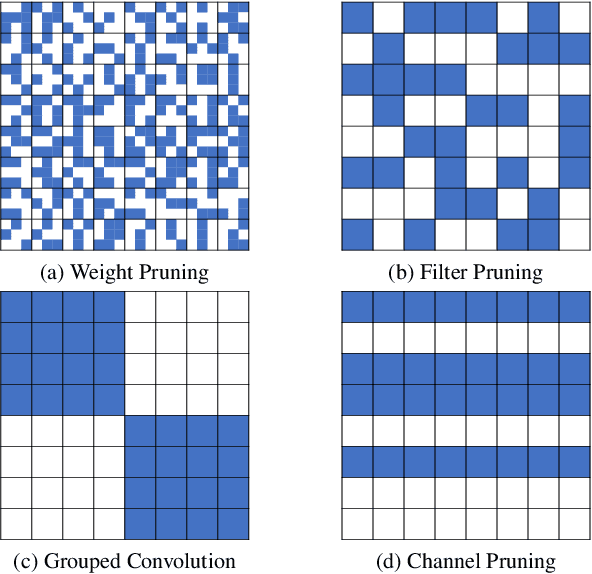
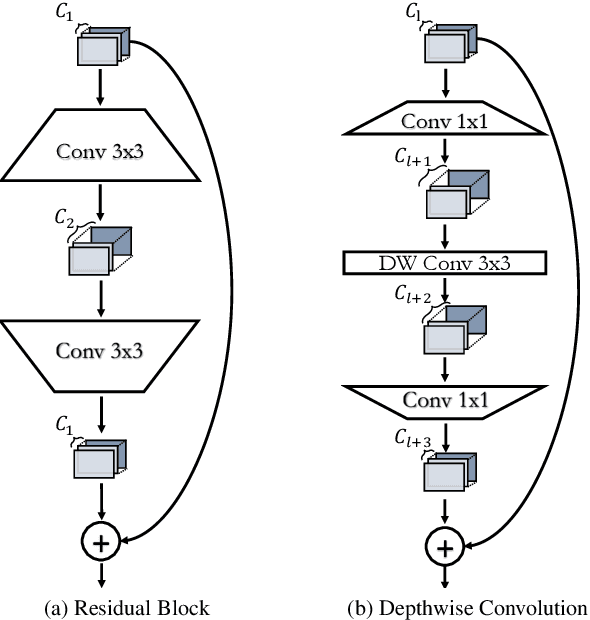
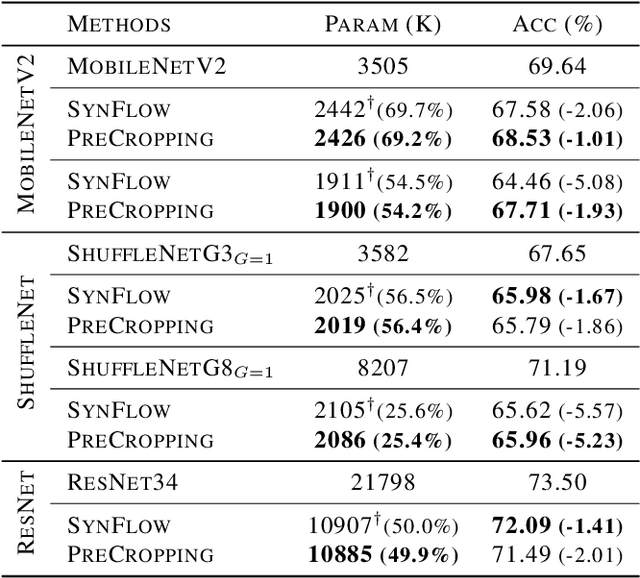
Pruning is a popular technique for reducing the model size and computational cost of convolutional neural networks (CNNs). However, a slow retraining or fine-tuning procedure is often required to recover the accuracy loss caused by pruning. Recently, a new research direction on weight pruning, pruning-at-initialization (PAI), is proposed to directly prune CNNs before training so that fine-tuning or retraining can be avoided. While PAI has shown promising results in reducing the model size, existing approaches rely on fine-grained weight pruning which requires unstructured sparse matrix computation, making it difficult to achieve real speedup in practice unless the sparsity is very high. This work is the first to show that fine-grained weight pruning is in fact not necessary for PAI. Instead, the layerwise compression ratio is the main critical factor to determine the accuracy of a CNN model pruned at initialization. Based on this key observation, we propose PreCropping, a structured hardware-efficient model compression scheme. PreCropping directly compresses the model at the channel level following the layerwise compression ratio. Compared to weight pruning, the proposed scheme is regular and dense in both storage and computation without sacrificing accuracy. In addition, since PreCropping compresses CNNs at initialization, the computational and memory costs of CNNs are reduced for both training and inference on commodity hardware. We empirically demonstrate our approaches on several modern CNN architectures, including ResNet, ShuffleNet, and MobileNet for both CIFAR-10 and ImageNet.
Transformer Quality in Linear Time
Feb 21, 2022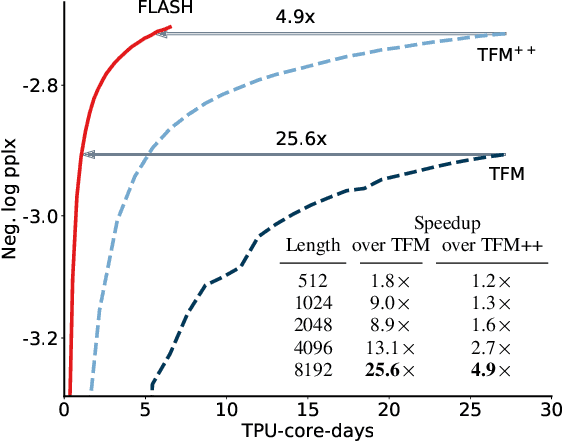
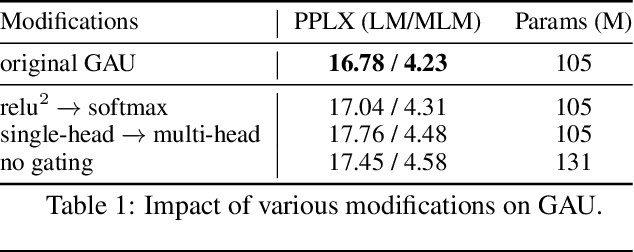
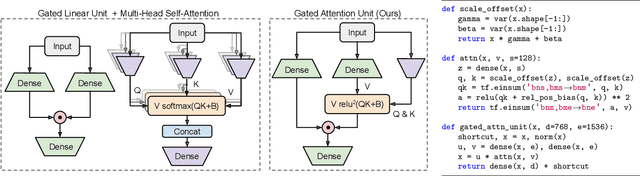

We revisit the design choices in Transformers, and propose methods to address their weaknesses in handling long sequences. First, we propose a simple layer named gated attention unit, which allows the use of a weaker single-head attention with minimal quality loss. We then propose a linear approximation method complementary to this new layer, which is accelerator-friendly and highly competitive in quality. The resulting model, named FLASH, matches the perplexity of improved Transformers over both short (512) and long (8K) context lengths, achieving training speedups of up to 4.9$\times$ on Wiki-40B and 12.1$\times$ on PG-19 for auto-regressive language modeling, and 4.8$\times$ on C4 for masked language modeling.
BulletTrain: Accelerating Robust Neural Network Training via Boundary Example Mining
Sep 29, 2021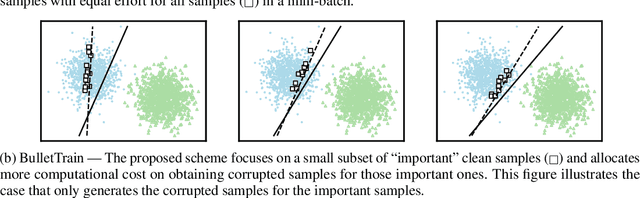

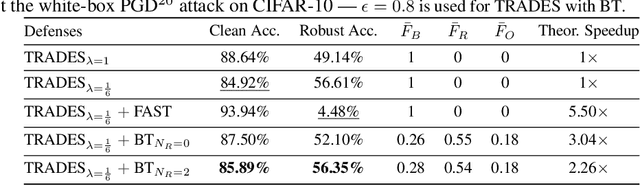
Neural network robustness has become a central topic in machine learning in recent years. Most training algorithms that improve the model's robustness to adversarial and common corruptions also introduce a large computational overhead, requiring as many as ten times the number of forward and backward passes in order to converge. To combat this inefficiency, we propose BulletTrain $-$ a boundary example mining technique to drastically reduce the computational cost of robust training. Our key observation is that only a small fraction of examples are beneficial for improving robustness. BulletTrain dynamically predicts these important examples and optimizes robust training algorithms to focus on the important examples. We apply our technique to several existing robust training algorithms and achieve a 2.1$\times$ speed-up for TRADES and MART on CIFAR-10 and a 1.7$\times$ speed-up for AugMix on CIFAR-10-C and CIFAR-100-C without any reduction in clean and robust accuracy.
Sinan: Data-Driven, QoS-Aware Cluster Management for Microservices
May 27, 2021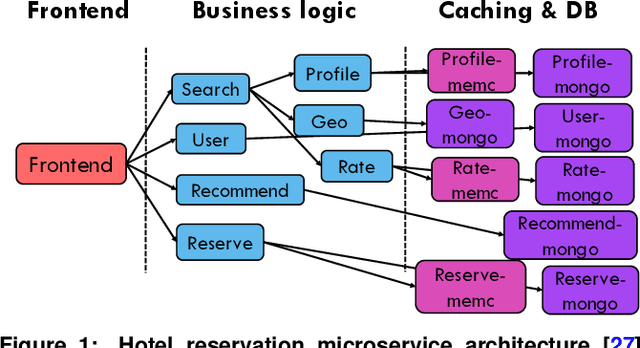
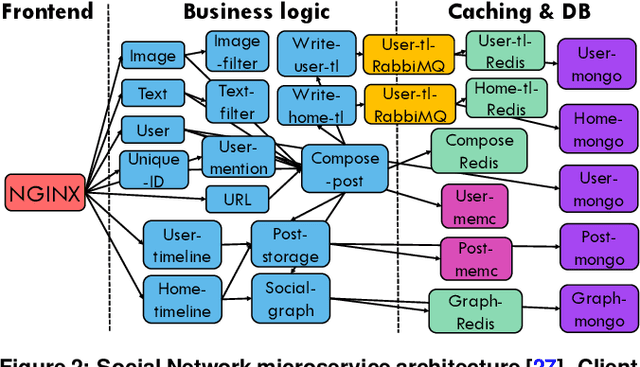

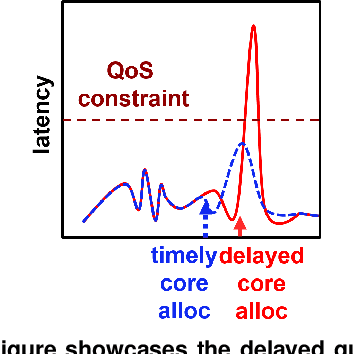
Cloud applications are increasingly shifting from large monolithic services, to large numbers of loosely-coupled, specialized microservices. Despite their advantages in terms of facilitating development, deployment, modularity, and isolation, microservices complicate resource management, as dependencies between them introduce backpressure effects and cascading QoS violations. We present Sinan, a data-driven cluster manager for interactive cloud microservices that is online and QoS-aware. Sinan leverages a set of scalable and validated machine learning models to determine the performance impact of dependencies between microservices, and allocate appropriate resources per tier in a way that preserves the end-to-end tail latency target. We evaluate Sinan both on dedicated local clusters and large-scale deployments on Google Compute Engine (GCE) across representative end-to-end applications built with microservices, such as social networks and hotel reservation sites. We show that Sinan always meets QoS, while also maintaining cluster utilization high, in contrast to prior work which leads to unpredictable performance or sacrifices resource efficiency. Furthermore, the techniques in Sinan are explainable, meaning that cloud operators can yield insights from the ML models on how to better deploy and design their applications to reduce unpredictable performance.
Contrastive Weight Regularization for Large Minibatch SGD
Nov 17, 2020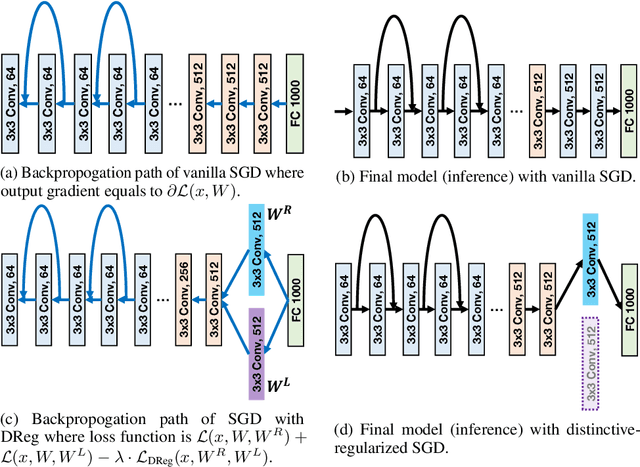
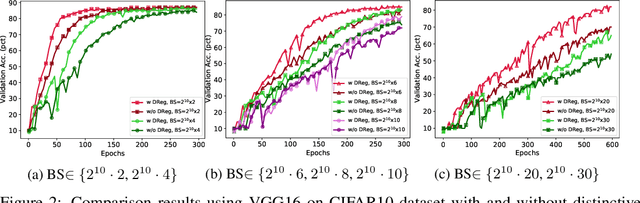
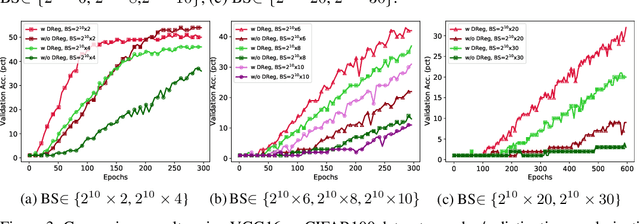
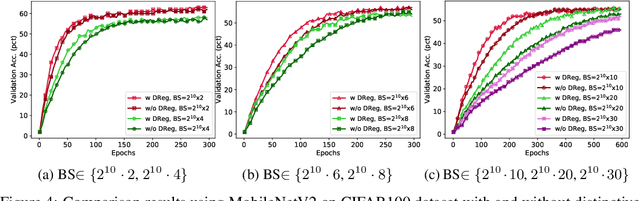
The minibatch stochastic gradient descent method (SGD) is widely applied in deep learning due to its efficiency and scalability that enable training deep networks with a large volume of data. Particularly in the distributed setting, SGD is usually applied with large batch size. However, as opposed to small-batch SGD, neural network models trained with large-batch SGD can hardly generalize well, i.e., the validation accuracy is low. In this work, we introduce a novel regularization technique, namely distinctive regularization (DReg), which replicates a certain layer of the deep network and encourages the parameters of both layers to be diverse. The DReg technique introduces very little computation overhead. Moreover, we empirically show that optimizing the neural network with DReg using large-batch SGD achieves a significant boost in the convergence and improved generalization performance. We also demonstrate that DReg can boost the convergence of large-batch SGD with momentum. We believe that DReg can be used as a simple regularization trick to accelerate large-batch training in deep learning.
GuardNN: Secure DNN Accelerator for Privacy-Preserving Deep Learning
Aug 26, 2020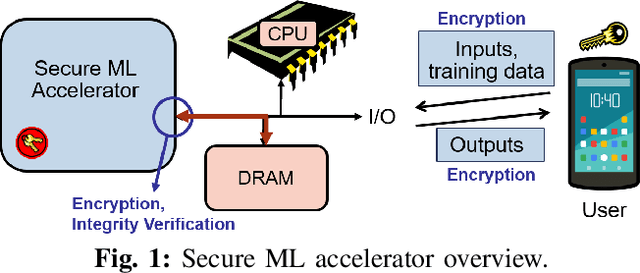
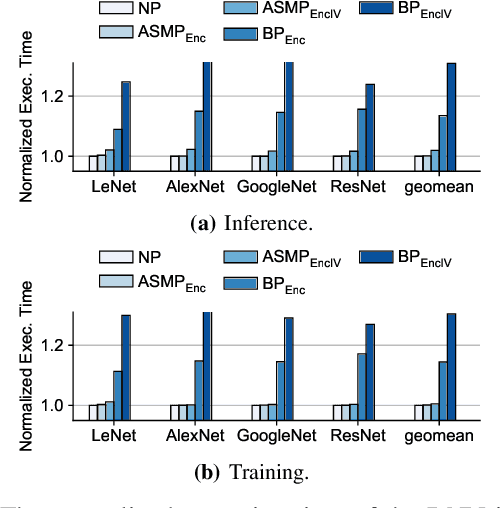
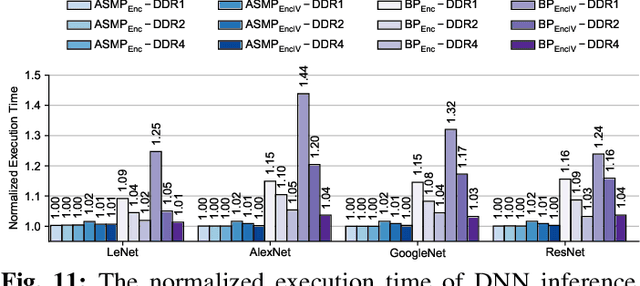
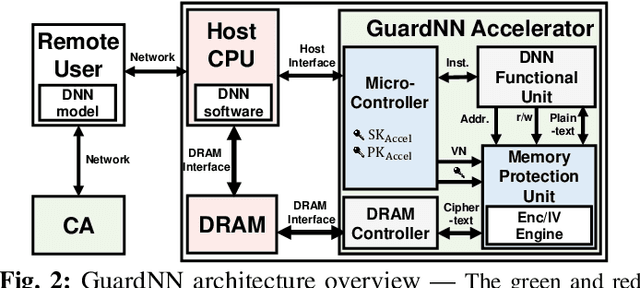
This paper proposes GuardNN, a secure deep neural network (DNN) accelerator, which provides strong hardware-based protection for user data and model parameters even in an untrusted environment. GuardNN shows that the architecture and protection can be customized for a specific application to provide strong confidentiality and integrity protection with negligible overhead. The design of the GuardNN instruction set reduces the TCB to just the accelerator and enables confidentiality protection without the overhead of integrity protection. GuardNN also introduces a new application-specific memory protection scheme to minimize the overhead of memory encryption and integrity verification. The scheme shows that most of the off-chip meta-data in today's state-of-the-art memory protection can be removed by exploiting the known memory access patterns of a DNN accelerator. GuardNN is implemented as an FPGA prototype, which demonstrates effective protection with less than 2% performance overhead for inference over a variety of modern DNN models.
MgX: Near-Zero Overhead Memory Protection with an Application to Secure DNN Acceleration
Apr 20, 2020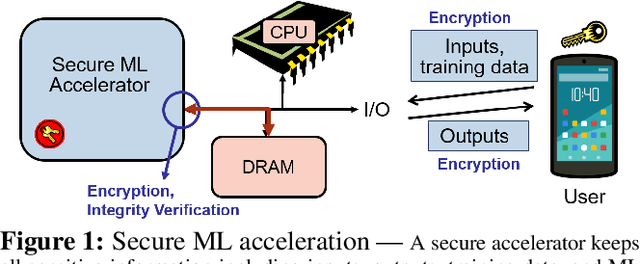

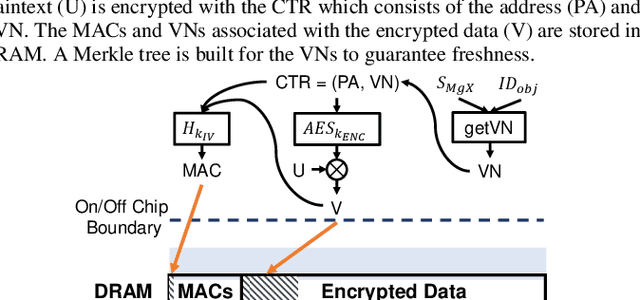
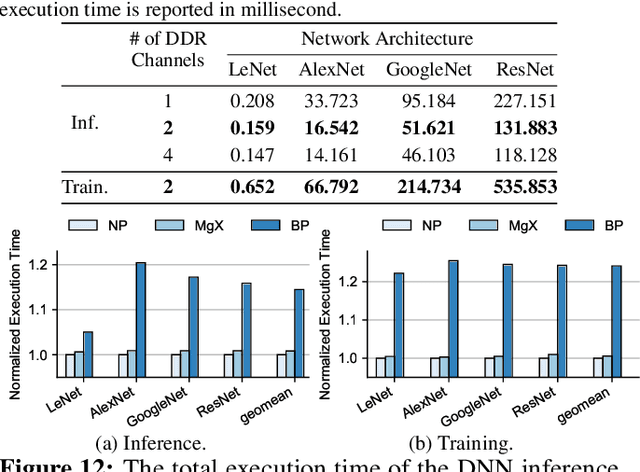
In this paper, we propose MgX, a near-zero overhead memory protection scheme for hardware accelerators. MgX minimizes the performance overhead of off-chip memory encryption and integrity verification by exploiting the application-specific aspect of accelerators. Accelerators tend to explicitly manage data movement between on-chip and off-chip memory, typically at an object granularity that is much larger than cache lines. Exploiting these accelerator-specific characteristics, MgX generates version numbers used in memory encryption and integrity verification only using on-chip state without storing them in memory, and also customizes the granularity of the memory protection to match the granularity used by the accelerator. To demonstrate the applicability of MgX, we present an in-depth study of MgX for deep neural network (DNN) and also describe implementations for H.264 video decoding and genome alignment. Experimental results show that applying MgX has less than 1% performance overhead for both DNN inference and training on state-of-the-art DNN architectures.
Precision Gating: Improving Neural Network Efficiency with Dynamic Dual-Precision Activations
Feb 17, 2020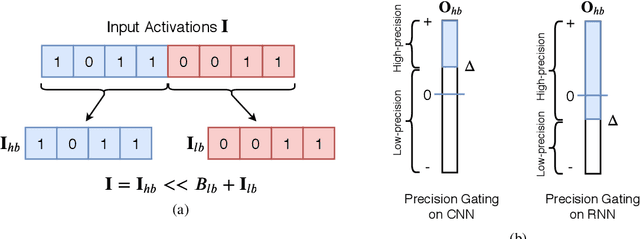
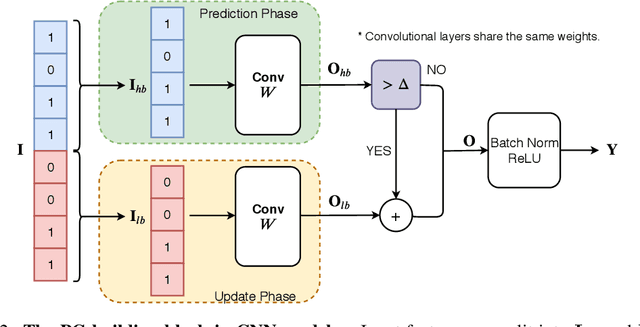
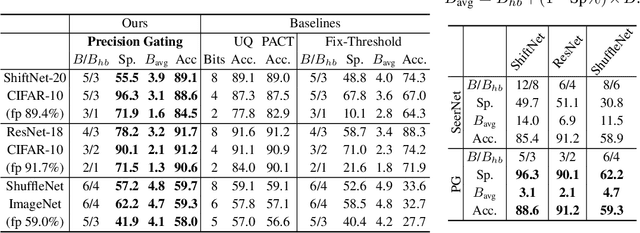
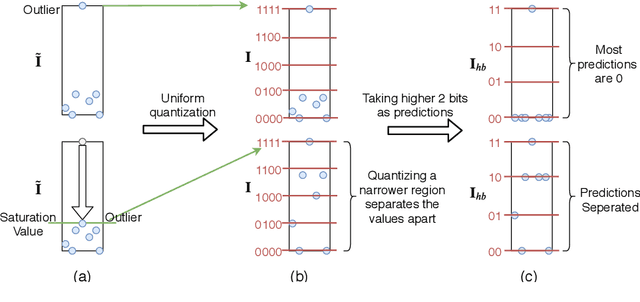
We propose precision gating (PG), an end-to-end trainable dynamic dual-precision quantization technique for deep neural networks. PG computes most features in a low precision and only a small proportion of important features in a higher precision to preserve accuracy. The proposed approach is applicable to a variety of DNN architectures and significantly reduces the computational cost of DNN execution with almost no accuracy loss. Our experiments indicate that PG achieves excellent results on CNNs, including statically compressed mobile-friendly networks such as ShuffleNet. Compared to the state-of-the-art prediction-based quantization schemes, PG achieves the same or higher accuracy with 2.4$\times$ less compute on ImageNet. PG furthermore applies to RNNs. Compared to 8-bit uniform quantization, PG obtains a 1.2% improvement in perplexity per word with 2.7$\times$ computational cost reduction on LSTM on the Penn Tree Bank dataset.
Channel Gating Neural Networks
May 29, 2018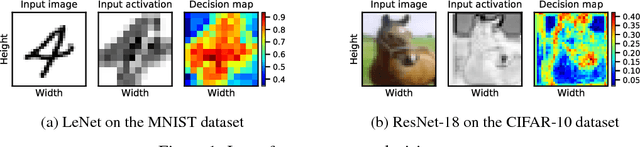
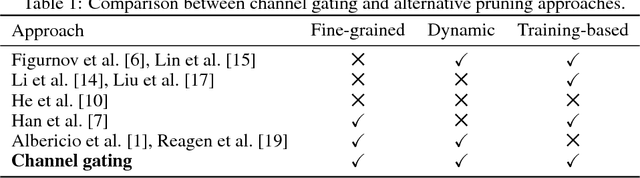
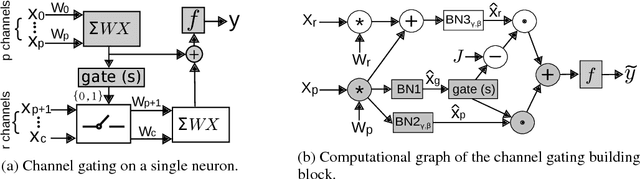
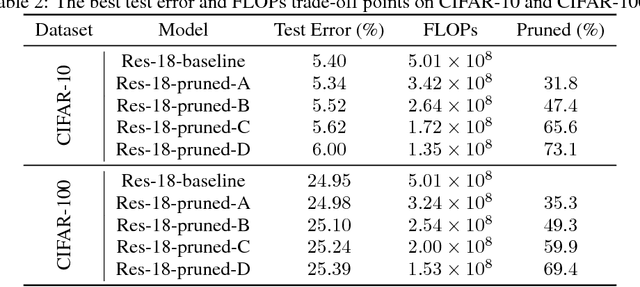
Employing deep neural networks to obtain state-of-the-art performance on computer vision tasks can consume billions of floating point operations and several Joules of energy per evaluation. Network pruning, which statically removes unnecessary features and weights, has emerged as a promising way to reduce this computation cost. In this paper, we propose channel gating, a dynamic, fine-grained, training-based computation-cost-reduction scheme. Channel gating works by identifying the regions in the features which contribute less to the classification result and turning off a subset of the channels for computing the pixels within these uninteresting regions. Unlike static network pruning, the channel gating optimizes computations exploiting characteristics specific to each input at run-time. We show experimentally that applying channel gating in state-of-the-art networks can achieve 66% and 60% reduction in FLOPs with 0.22% and 0.29% accuracy loss on the CIFAR-10 and CIFAR-100 datasets, respectively.