 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Pruning is All You Need for Pruning CNNs at Initialization
Paper and Code
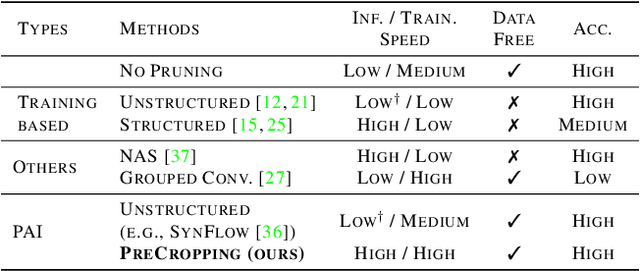
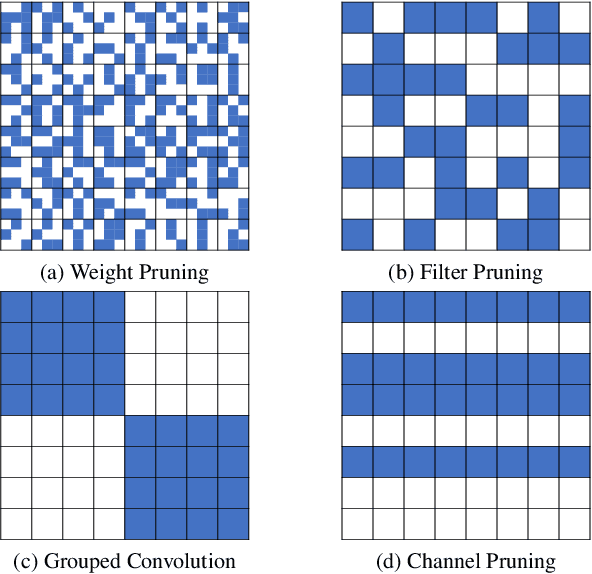
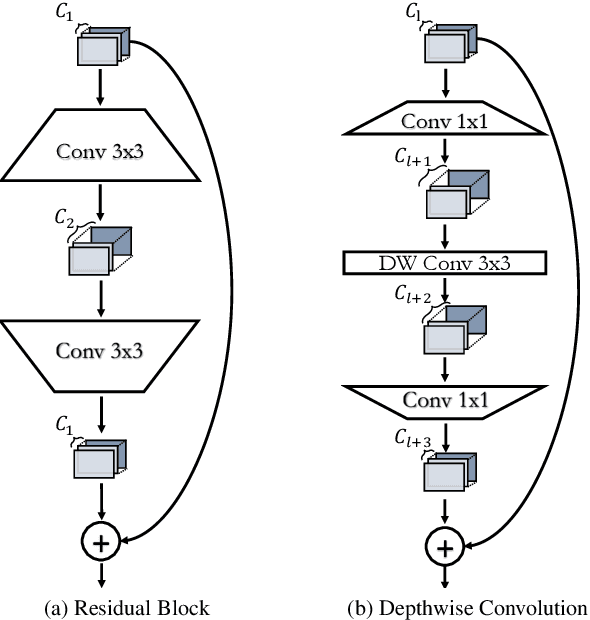
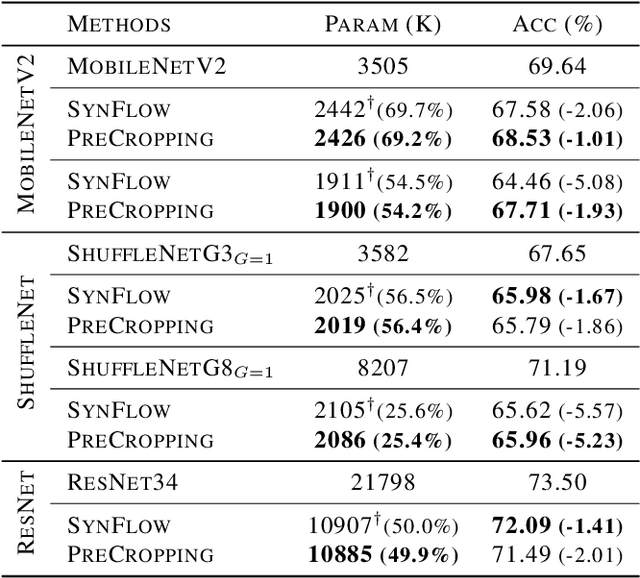
Pruning is a popular technique for reducing the model size and computational cost of convolutional neural networks (CNNs). However, a slow retraining or fine-tuning procedure is often required to recover the accuracy loss caused by pruning. Recently, a new research direction on weight pruning, pruning-at-initialization (PAI), is proposed to directly prune CNNs before training so that fine-tuning or retraining can be avoided. While PAI has shown promising results in reducing the model size, existing approaches rely on fine-grained weight pruning which requires unstructured sparse matrix computation, making it difficult to achieve real speedup in practice unless the sparsity is very high. This work is the first to show that fine-grained weight pruning is in fact not necessary for PAI. Instead, the layerwise compression ratio is the main critical factor to determine the accuracy of a CNN model pruned at initialization. Based on this key observation, we propose PreCropping, a structured hardware-efficient model compression scheme. PreCropping directly compresses the model at the channel level following the layerwise compression ratio. Compared to weight pruning, the proposed scheme is regular and dense in both storage and computation without sacrificing accuracy. In addition, since PreCropping compresses CNNs at initialization, the computational and memory costs of CNNs are reduced for both training and inference on commodity hardware. We empirically demonstrate our approaches on several modern CNN architectures, including ResNet, ShuffleNet, and MobileNet for both CIFAR-10 and ImageNet.