 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGauS: Differentiable Scheduling Optimization via Gaussian Reparameterization
Feb 23, 2026Efficient operator scheduling is a fundamental challenge in software compilation and hardware synthesis. While recent differentiable approaches have sought to replace traditional ones like exact solvers or heuristics with gradient-based search, they typically rely on categorical distributions that fail to capture the ordinal nature of time and suffer from a parameter space that scales poorly. In this paper, we propose a novel differentiable framework, GauS, that models operator scheduling as a stochastic relaxation using Gaussian distributions, which fully utilize modern parallel computing devices like GPUs. By representing schedules as continuous Gaussian variables, we successfully capture the ordinal nature of time and reduce the optimization space by orders of magnitude. Our method is highly flexible to represent various objectives and constraints, which provides the first differentiable formulation for the complex pipelined scheduling problem. We evaluate our method on a range of benchmarks, demonstrating that Gaus achieves Pareto-optimal results.
HeuriGym: An Agentic Benchmark for LLM-Crafted Heuristics in Combinatorial Optimization
Jun 09, 2025While Large Language Models (LLMs) have demonstrated significant advancements in reasoning and agent-based problem-solving, current evaluation methodologies fail to adequately assess their capabilities: existing benchmarks either rely on closed-ended questions prone to saturation and memorization, or subjective comparisons that lack consistency and rigor. In this work, we introduce HeuriGym, an agentic framework designed for evaluating heuristic algorithms generated by LLMs for combinatorial optimization problems, characterized by clearly defined objectives and expansive solution spaces. HeuriGym empowers LLMs to propose heuristics, receive evaluative feedback via code execution, and iteratively refine their solutions. We evaluate nine state-of-the-art models on nine problems across domains such as computer systems, logistics, and biology, exposing persistent limitations in tool use, planning, and adaptive reasoning. To quantify performance, we propose the Quality-Yield Index (QYI), a metric that captures both solution pass rate and quality. Even top models like GPT-o4-mini-high and Gemini-2.5-Pro attain QYI scores of only 0.6, well below the expert baseline of 1. Our open-source benchmark aims to guide the development of LLMs toward more effective and realistic problem-solving in scientific and engineering domains.
Trainable Fixed-Point Quantization for Deep Learning Acceleration on FPGAs
Jan 31, 2024Quantization is a crucial technique for deploying deep learning models on resource-constrained devices, such as embedded FPGAs. Prior efforts mostly focus on quantizing matrix multiplications, leaving other layers like BatchNorm or shortcuts in floating-point form, even though fixed-point arithmetic is more efficient on FPGAs. A common practice is to fine-tune a pre-trained model to fixed-point for FPGA deployment, but potentially degrading accuracy. This work presents QFX, a novel trainable fixed-point quantization approach that automatically learns the binary-point position during model training. Additionally, we introduce a multiplier-free quantization strategy within QFX to minimize DSP usage. QFX is implemented as a PyTorch-based library that efficiently emulates fixed-point arithmetic, supported by FPGA HLS, in a differentiable manner during backpropagation. With minimal effort, models trained with QFX can readily be deployed through HLS, producing the same numerical results as their software counterparts. Our evaluation shows that compared to post-training quantization, QFX can quantize models trained with element-wise layers quantized to fewer bits and achieve higher accuracy on both CIFAR-10 and ImageNet datasets. We further demonstrate the efficacy of multiplier-free quantization using a state-of-the-art binarized neural network accelerator designed for an embedded FPGA (AMD Xilinx Ultra96 v2). We plan to release QFX in open-source format.
Understanding the Potential of FPGA-Based Spatial Acceleration for Large Language Model Inference
Dec 23, 2023



Recent advancements in large language models (LLMs) boasting billions of parameters have generated a significant demand for efficient deployment in inference workloads. The majority of existing approaches rely on temporal architectures that reuse hardware units for different network layers and operators. However, these methods often encounter challenges in achieving low latency due to considerable memory access overhead. This paper investigates the feasibility and potential of model-specific spatial acceleration for LLM inference on FPGAs. Our approach involves the specialization of distinct hardware units for specific operators or layers, facilitating direct communication between them through a dataflow architecture while minimizing off-chip memory accesses. We introduce a comprehensive analytical model for estimating the performance of a spatial LLM accelerator, taking into account the on-chip compute and memory resources available on an FPGA. Through our analysis, we can determine the scenarios in which FPGA-based spatial acceleration can outperform its GPU-based counterpart. To enable more productive implementations of an LLM model on FPGAs, we further provide a library of high-level synthesis (HLS) kernels that are composable and reusable. This library will be made available as open-source. To validate the effectiveness of both our analytical model and HLS library, we have implemented BERT and GPT2 on an AMD Alveo U280 FPGA device. Experimental results demonstrate our approach can achieve up to 16.1x speedup when compared to previous FPGA-based accelerators for the BERT model. For GPT generative inference, we attain a 2.2x speedup compared to DFX, an FPGA overlay, in the prefill stage, while achieving a 1.9x speedup and a 5.7x improvement in energy efficiency compared to the NVIDIA A100 GPU in the decode stage.
QuIP: 2-Bit Quantization of Large Language Models With Guarantees
Jul 25, 2023This work studies post-training parameter quantization in large language models (LLMs). We introduce quantization with incoherence processing (QuIP), a new method based on the insight that quantization benefits from incoherent weight and Hessian matrices, i.e., from the weights and the directions in which it is important to round them accurately being unaligned with the coordinate axes. QuIP consists of two steps: (1) an adaptive rounding procedure minimizing a quadratic proxy objective; (2) efficient pre- and post-processing that ensures weight and Hessian incoherence via multiplication by random orthogonal matrices. We complement QuIP with the first theoretical analysis for an LLM-scale quantization algorithm, and show that our theory also applies to an existing method, OPTQ. Empirically, we find that our incoherence preprocessing improves several existing quantization algorithms and yields the first LLM quantization methods that produce viable results using only two bits per weight. Our code can be found at https://github.com/jerry-chee/QuIP .
Structured Pruning is All You Need for Pruning CNNs at Initialization
Mar 04, 2022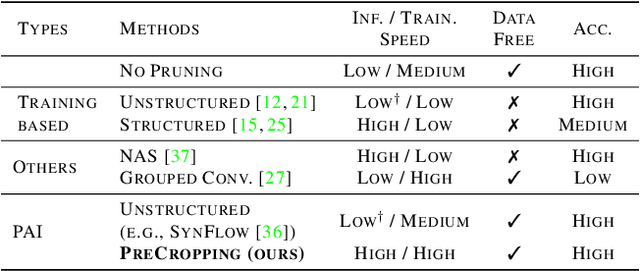
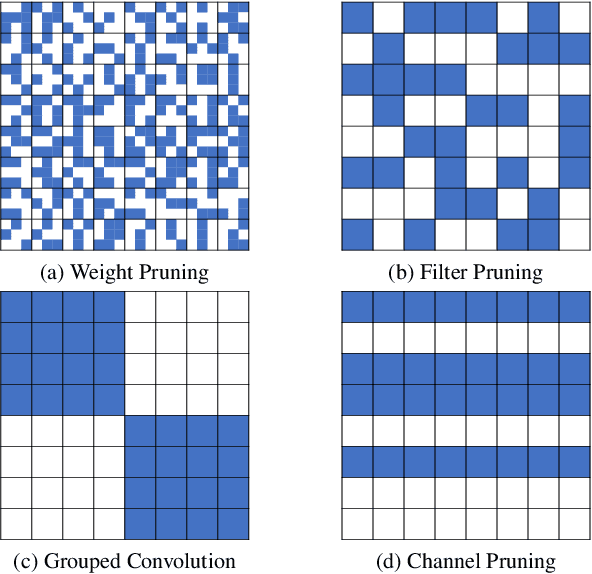
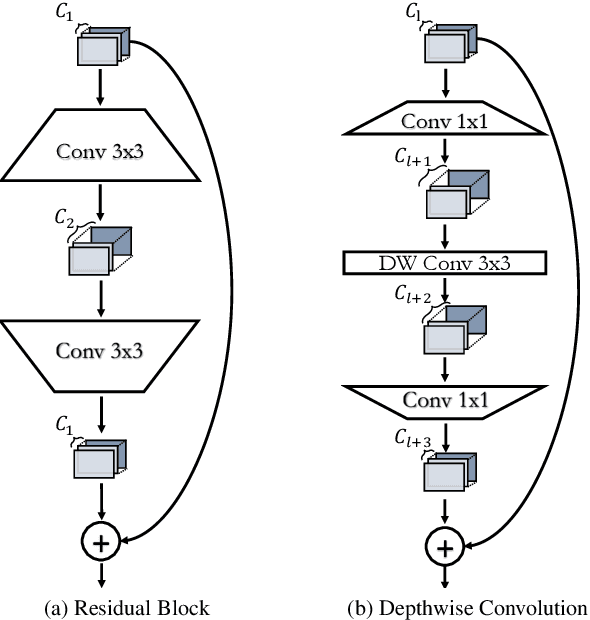
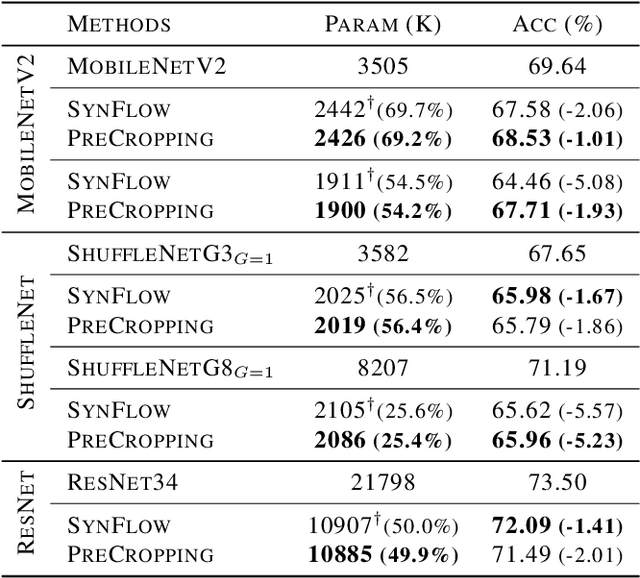
Pruning is a popular technique for reducing the model size and computational cost of convolutional neural networks (CNNs). However, a slow retraining or fine-tuning procedure is often required to recover the accuracy loss caused by pruning. Recently, a new research direction on weight pruning, pruning-at-initialization (PAI), is proposed to directly prune CNNs before training so that fine-tuning or retraining can be avoided. While PAI has shown promising results in reducing the model size, existing approaches rely on fine-grained weight pruning which requires unstructured sparse matrix computation, making it difficult to achieve real speedup in practice unless the sparsity is very high. This work is the first to show that fine-grained weight pruning is in fact not necessary for PAI. Instead, the layerwise compression ratio is the main critical factor to determine the accuracy of a CNN model pruned at initialization. Based on this key observation, we propose PreCropping, a structured hardware-efficient model compression scheme. PreCropping directly compresses the model at the channel level following the layerwise compression ratio. Compared to weight pruning, the proposed scheme is regular and dense in both storage and computation without sacrificing accuracy. In addition, since PreCropping compresses CNNs at initialization, the computational and memory costs of CNNs are reduced for both training and inference on commodity hardware. We empirically demonstrate our approaches on several modern CNN architectures, including ResNet, ShuffleNet, and MobileNet for both CIFAR-10 and ImageNet.
SPADE: A Spectral Method for Black-Box Adversarial Robustness Evaluation
Feb 07, 2021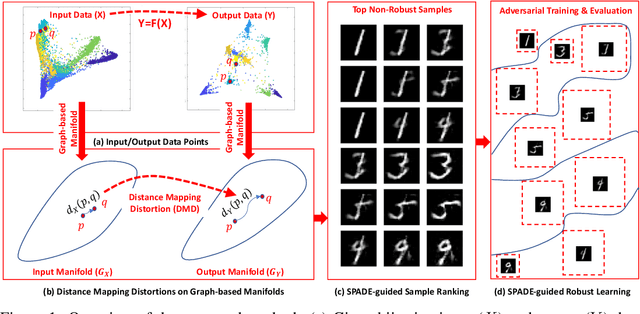
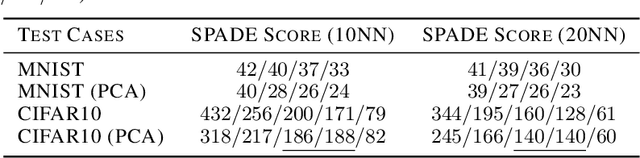
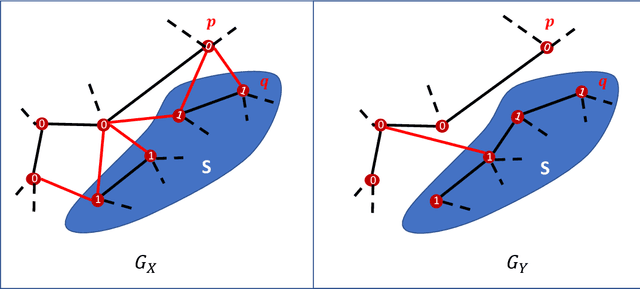

A black-box spectral method is introduced for evaluating the adversarial robustness of a given machine learning (ML) model. Our approach, named SPADE, exploits bijective distance mapping between the input/output graphs constructed for approximating the manifolds corresponding to the input/output data. By leveraging the generalized Courant-Fischer theorem, we propose a SPADE score for evaluating the adversarial robustness of a given model, which is proved to be an upper bound of the best Lipschitz constant under the manifold setting. To reveal the most non-robust data samples highly vulnerable to adversarial attacks, we develop a spectral graph embedding procedure leveraging dominant generalized eigenvectors. This embedding step allows assigning each data sample a robustness score that can be further harnessed for more effective adversarial training. Our experiments show the proposed SPADE method leads to promising empirical results for neural network models adversarially trained with the MNIST and CIFAR-10 data sets.
CoDeNet: Algorithm-hardware Co-design for Deformable Convolution
Jun 12, 2020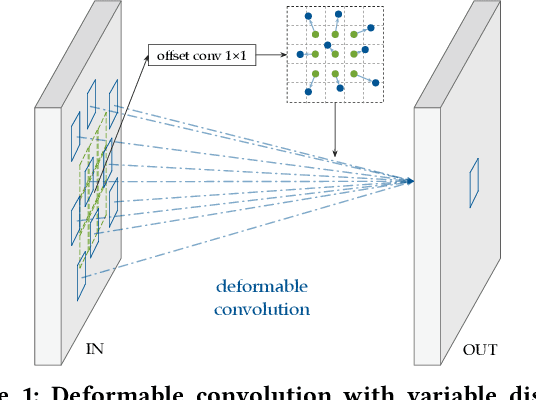
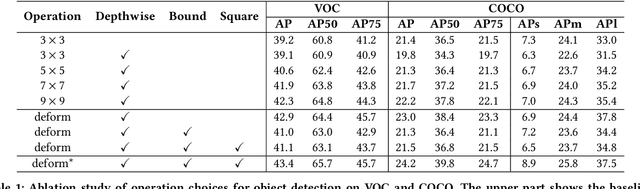
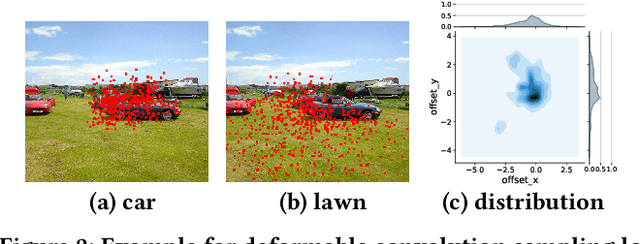
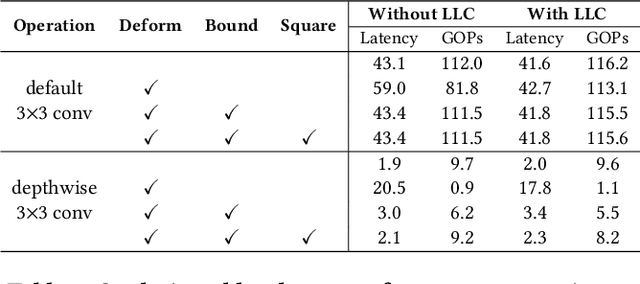
Deploying deep learning models on embedded systems for computer vision tasks has been challenging due to limited compute resources and strict energy budgets. The majority of existing work focuses on accelerating image classification, while other fundamental vision problems, such as object detection, have not been adequately addressed. Compared with image classification, detection problems are more sensitive to the spatial variance of objects, and therefore, require specialized convolutions to aggregate spatial information. To address this, recent work proposes dynamic deformable convolution to augment regular convolutions. Regular convolutions process a fixed grid of pixels across all the spatial locations in an image, while dynamic deformable convolution may access arbitrary pixels in the image and the access pattern is input-dependent and varies per spatial location. These properties lead to inefficient memory accesses of inputs with existing hardware. In this work, we first investigate the overhead of the deformable convolution on embedded FPGA SoCs, and introduce a depthwise deformable convolution to reduce the total number of operations required. We then show the speed-accuracy tradeoffs for a set of algorithm modifications including irregular-access versus limited-range and fixed-shape. We evaluate these algorithmic changes with corresponding hardware optimizations. Results show a 1.36x and 9.76x speedup respectively for the full and depthwise deformable convolution on the embedded FPGA accelerator with minor accuracy loss on the object detection task. We then co-design an efficient network CoDeNet with the modified deformable convolution for object detection and quantize the network to 4-bit weights and 8-bit activations. Results show that our designs lie on the pareto-optimal front of the latency-accuracy tradeoff for the object detection task on embedded FPGAs
Algorithm-hardware Co-design for Deformable Convolution
Feb 19, 2020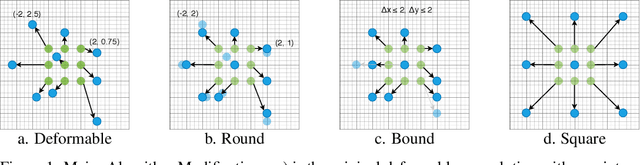
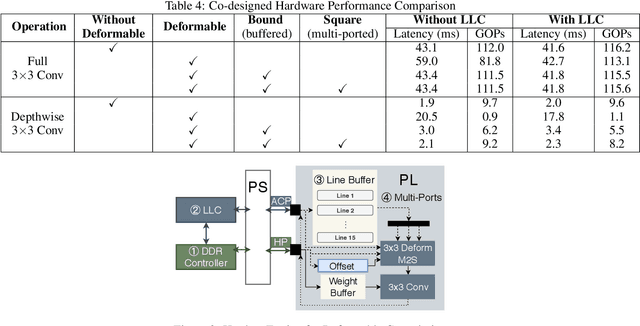
FPGAs provide a flexible and efficient platform to accelerate rapidly-changing algorithms for computer vision. The majority of existing work focuses on accelerating image classification, while other fundamental vision problems, including object detection and instance segmentation, have not been adequately addressed. Compared with image classification, detection problems are more sensitive to the spatial variance of objects, and therefore, require specialized convolutions to aggregate spatial information. To address this, recent work proposes dynamic deformable convolution to augment regular convolutions. Regular convolutions process a fixed grid of pixels across all the spatial locations in an image, while dynamic deformable convolutions may access arbitrary pixels in the image and the access pattern is input-dependent and varies per spatial location. These properties lead to inefficient memory accesses of inputs with existing hardware. In this work, we first investigate the overhead of the deformable convolution on embedded FPGA SoCs, and then show the accuracy-latency tradeoffs for a set of algorithm modifications including full versus depthwise, fixed-shape, and limited-range. These modifications benefit the energy efficiency for embedded devices in general as they reduce the compute complexity. We then build an efficient object detection network with modified deformable convolutions and quantize the network using state-of-the-art quantization methods. We implement a unified hardware engine on FPGA to support all the operations in the network. Preliminary experiments show that little accuracy is compromised and speedup can be achieved with our co-design optimization for the deformable convolution.
ZeroQ: A Novel Zero Shot Quantization Framework
Jan 01, 2020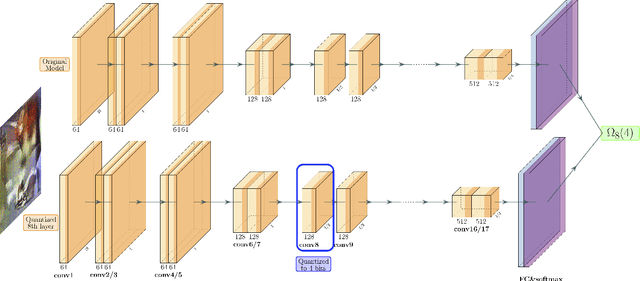
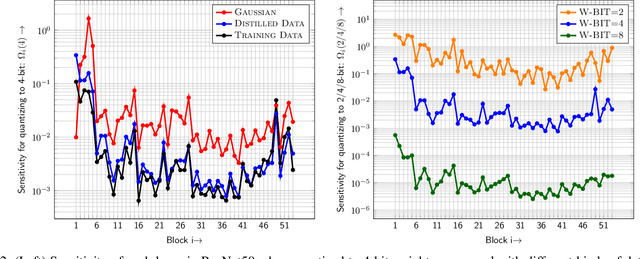

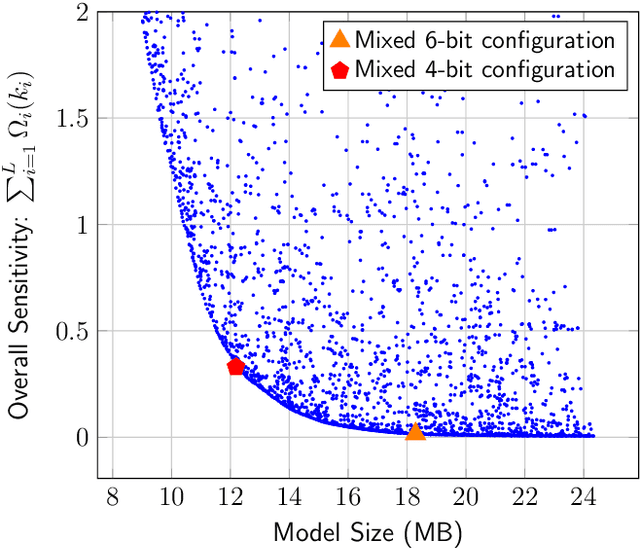
Quantization is a promising approach for reducing the inference time and memory footprint of neural networks. However, most existing quantization methods require access to the original training dataset for retraining during quantization. This is often not possible for applications with sensitive or proprietary data, e.g., due to privacy and security concerns. Existing zero-shot quantization methods use different heuristics to address this, but they result in poor performance, especially when quantizing to ultra-low precision. Here, we propose ZeroQ , a novel zero-shot quantization framework to address this. ZeroQ enables mixed-precision quantization without any access to the training or validation data. This is achieved by optimizing for a Distilled Dataset, which is engineered to match the statistics of batch normalization across different layers of the network. ZeroQ supports both uniform and mixed-precision quantization. For the latter, we introduce a novel Pareto frontier based method to automatically determine the mixed-precision bit setting for all layers, with no manual search involved. We extensively test our proposed method on a diverse set of models, including ResNet18/50/152, MobileNetV2, ShuffleNet, SqueezeNext, and InceptionV3 on ImageNet, as well as RetinaNet-ResNet50 on the Microsoft COCO dataset. In particular, we show that ZeroQ can achieve 1.71\% higher accuracy on MobileNetV2, as compared to the recently proposed DFQ method. Importantly, ZeroQ has a very low computational overhead, and it can finish the entire quantization process in less than 30s (0.5\% of one epoch training time of ResNet50 on ImageNet). We have open-sourced the ZeroQ framework\footnote{https://github.com/amirgholami/ZeroQ}.