 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Methods for Studying Latent Neural Activity Dynamics
Jun 09, 2026Recent developments in brain recording are driving a demand for machine learning tools capable of decoding the latent structure of large populations of neurons. In this paper, we provide a comprehensive survey that outlines the trajectory of Latent Variable Models (LVMs) from early state-space models to more recent deep generative models. We organize the literature into three closely related domains: (1) Single-Region Latent Dynamics, which includes models such as linear dynamical systems to more complex dynamics represented by Recurrent Neural Networks (RNNs) and Neural Ordinary Differential Equations (ODEs); (2) Multi-Region Communication, which employs probabilistic as well as subspace methods to study how information is transferred across different brain areas considering synaptic propagation delays and network connectivity; and (3) Behavior-Aligned Modeling, which seeks to disentangle neural activity related to task performance from other internal states via supervised or contrastive learning. This survey also includes large-scale neural foundation models, such as Transformers and diffusion models, that rely on large-scale pre-training for optimal performance across subjects. Finally, we conclude and discuss benchmarks, evaluation criteria, and open challenges, such as the ability to identify causal links or directionality of communication, to facilitate future research for bridging interpretable brain dynamics with reliable neural decoding.
STELLAR: Spatio-Temporal Environmental Learning with Latent Alignment and Refinement for Long-Tailed Species Distribution Modeling
Jun 07, 2026Joint Species Distribution Modeling (JSDM) is a key enabler for biodiversity monitoring and conservation planning. However, accurate JSDM faces two coupled challenges: environmental drivers and species distributions are inherently spatio-temporal, while species co-occurrence patterns exhibit complex non-linear community structure and severe long-tail imbalance driven by rare species. Existing approaches often address these factors in isolation, learning from static covariates or neglecting the historical trajectories of dynamic community structure. To overcome these limitations, we propose STELLAR (Spatio-Temporal Environmental Learning with Latent Alignment and Refinement), a novel framework that learns a shared latent space where dynamic habitat context and community structure are optimized jointly. Our approach integrates three complementary components: (1) a Graph-Temporal Encoder that employs graph attention and recurrent units to aggregate spatial neighborhood effects and capture the co-evolving historical dynamics of environmental context and community structure; (2) a Context-Anchored Latent Alignment mechanism that structures the latent space using a label-activated mixture prior and supervised contrastive learning, actively clustering species based on shared environmental preferences; and (3) an Imbalance-Aware Decoupled Decoding module that utilizes Asymmetric Loss to focus learning on hard, rare species samples, preventing mode collapse in the long tail. Experiments on the large-scale eBird dataset, curated with domain experts, demonstrate that our framework significantly outperforms state-of-the-art baselines, particularly in predicting rare species and revealing interpretable species interactions.
MIRNet: Integrating Constrained Graph-Based Reasoning with Pre-training for Diagnostic Medical Imaging
Nov 13, 2025Automated interpretation of medical images demands robust modeling of complex visual-semantic relationships while addressing annotation scarcity, label imbalance, and clinical plausibility constraints. We introduce MIRNet (Medical Image Reasoner Network), a novel framework that integrates self-supervised pre-training with constrained graph-based reasoning. Tongue image diagnosis is a particularly challenging domain that requires fine-grained visual and semantic understanding. Our approach leverages self-supervised masked autoencoder (MAE) to learn transferable visual representations from unlabeled data; employs graph attention networks (GAT) to model label correlations through expert-defined structured graphs; enforces clinical priors via constraint-aware optimization using KL divergence and regularization losses; and mitigates imbalance using asymmetric loss (ASL) and boosting ensembles. To address annotation scarcity, we also introduce TongueAtlas-4K, a comprehensive expert-curated benchmark comprising 4,000 images annotated with 22 diagnostic labels--representing the largest public dataset in tongue analysis. Validation shows our method achieves state-of-the-art performance. While optimized for tongue diagnosis, the framework readily generalizes to broader diagnostic medical imaging tasks.
HeuriGym: An Agentic Benchmark for LLM-Crafted Heuristics in Combinatorial Optimization
Jun 09, 2025While Large Language Models (LLMs) have demonstrated significant advancements in reasoning and agent-based problem-solving, current evaluation methodologies fail to adequately assess their capabilities: existing benchmarks either rely on closed-ended questions prone to saturation and memorization, or subjective comparisons that lack consistency and rigor. In this work, we introduce HeuriGym, an agentic framework designed for evaluating heuristic algorithms generated by LLMs for combinatorial optimization problems, characterized by clearly defined objectives and expansive solution spaces. HeuriGym empowers LLMs to propose heuristics, receive evaluative feedback via code execution, and iteratively refine their solutions. We evaluate nine state-of-the-art models on nine problems across domains such as computer systems, logistics, and biology, exposing persistent limitations in tool use, planning, and adaptive reasoning. To quantify performance, we propose the Quality-Yield Index (QYI), a metric that captures both solution pass rate and quality. Even top models like GPT-o4-mini-high and Gemini-2.5-Pro attain QYI scores of only 0.6, well below the expert baseline of 1. Our open-source benchmark aims to guide the development of LLMs toward more effective and realistic problem-solving in scientific and engineering domains.
Xtal2DoS: Attention-based Crystal to Sequence Learning for Density of States Prediction
Feb 03, 2023Modern machine learning techniques have been extensively applied to materials science, especially for property prediction tasks. A majority of these methods address scalar property predictions, while more challenging spectral properties remain less emphasized. We formulate a crystal-to-sequence learning task and propose a novel attention-based learning method, Xtal2DoS, which decodes the sequential representation of the material density of states (DoS) properties by incorporating the learned atomic embeddings through attention networks. Experiments show Xtal2DoS is faster than the existing models, and consistently outperforms other state-of-the-art methods on four metrics for two fundamental spectral properties, phonon and electronic DoS.
Deep Attentive Belief Propagation: Integrating Reasoning and Learning for Solving Constraint Optimization Problems
Sep 24, 2022
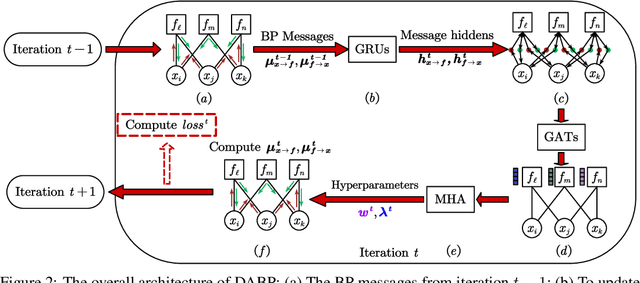
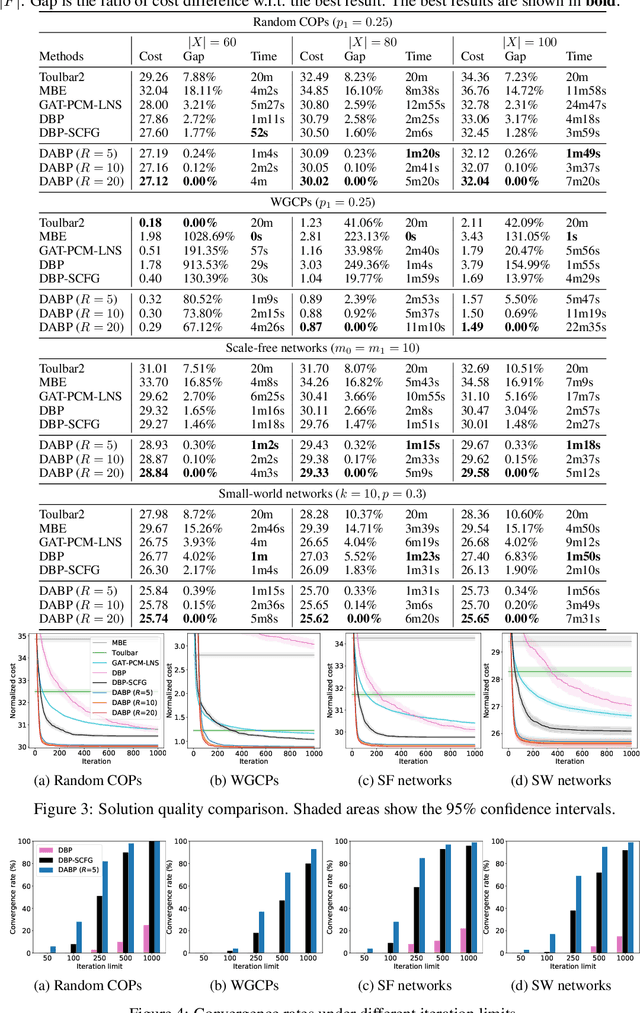
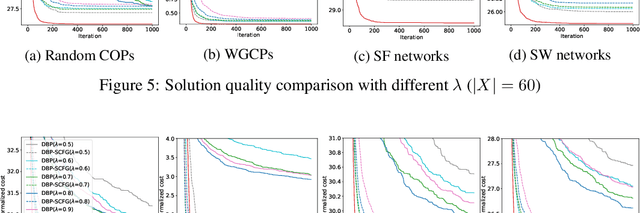
Belief Propagation (BP) is an important message-passing algorithm for various reasoning tasks over graphical models, including solving the Constraint Optimization Problems (COPs). It has been shown that BP can achieve state-of-the-art performance on various benchmarks by mixing old and new messages before sending the new one, i.e., damping. However, existing methods of tuning a static damping factor for BP not only are laborious but also harm their performance. Moreover, existing BP algorithms treat each variable node's neighbors equally when composing a new message, which also limits their exploration ability. To address these issues, we seamlessly integrate BP, Gated Recurrent Units (GRUs), and Graph Attention Networks (GATs) within the message-passing framework to reason about dynamic weights and damping factors for composing new BP messages. Our model, Deep Attentive Belief Propagation (DABP), takes the factor graph and the BP messages in each iteration as the input and infers the optimal weights and damping factors through GRUs and GATs, followed by a multi-head attention layer. Furthermore, unlike existing neural-based BP variants, we propose a novel self-supervised learning algorithm for DABP with a smoothed solution cost, which does not require expensive training labels and also avoids the common out-of-distribution issue through efficient online learning. Extensive experiments show that our model significantly outperforms state-of-the-art baselines.
Pretrained Cost Model for Distributed Constraint Optimization Problems
Dec 15, 2021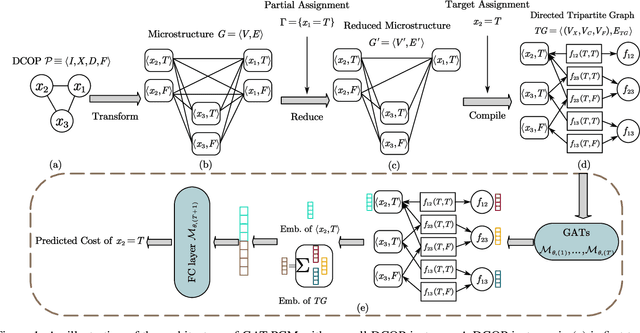
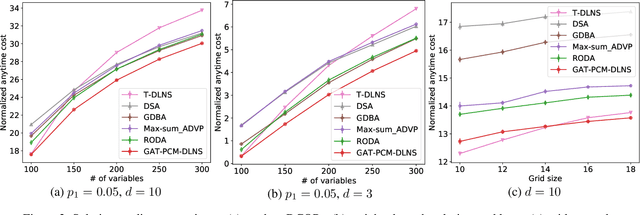
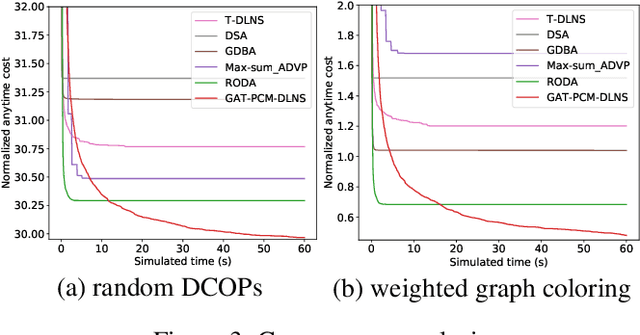
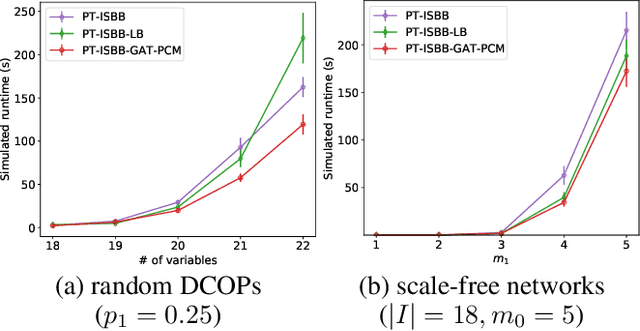
Distributed Constraint Optimization Problems (DCOPs) are an important subclass of combinatorial optimization problems, where information and controls are distributed among multiple autonomous agents. Previously, Machine Learning (ML) has been largely applied to solve combinatorial optimization problems by learning effective heuristics. However, existing ML-based heuristic methods are often not generalizable to different search algorithms. Most importantly, these methods usually require full knowledge about the problems to be solved, which are not suitable for distributed settings where centralization is not realistic due to geographical limitations or privacy concerns. To address the generality issue, we propose a novel directed acyclic graph representation schema for DCOPs and leverage the Graph Attention Networks (GATs) to embed graph representations. Our model, GAT-PCM, is then pretrained with optimally labelled data in an offline manner, so as to construct effective heuristics to boost a broad range of DCOP algorithms where evaluating the quality of a partial assignment is critical, such as local search or backtracking search. Furthermore, to enable decentralized model inference, we propose a distributed embedding schema of GAT-PCM where each agent exchanges only embedded vectors, and show its soundness and complexity. Finally, we demonstrate the effectiveness of our model by combining it with a local search or a backtracking search algorithm. Extensive empirical evaluations indicate that the GAT-PCM-boosted algorithms significantly outperform the state-of-the-art methods in various benchmarks. The pretrained model is available at https://github.com/dyc941126/GAT-PCM.
Gaussian Mixture Variational Autoencoder with Contrastive Learning for Multi-Label Classification
Dec 02, 2021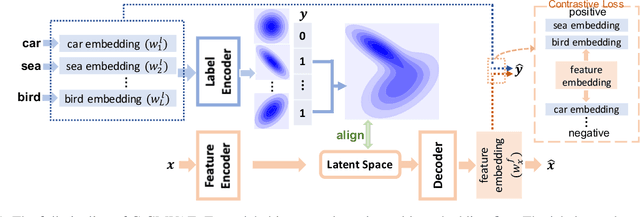
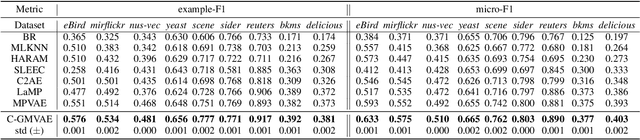
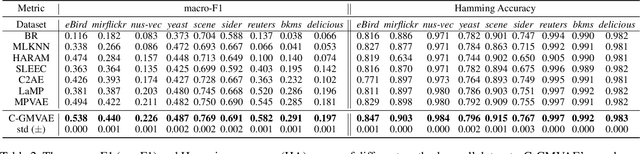
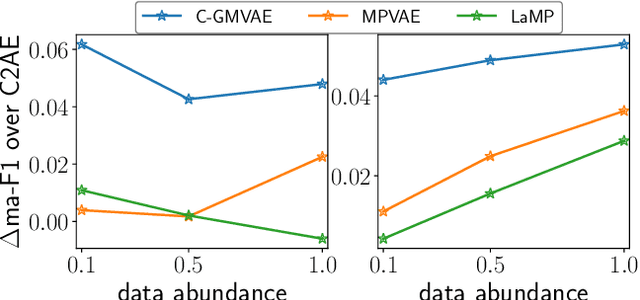
Multi-label classification (MLC) is a prediction task where each sample can have more than one label. We propose a novel contrastive learning boosted multi-label prediction model based on a Gaussian mixture variational autoencoder (C-GMVAE), which learns a multimodal prior space and employs a contrastive loss. Many existing methods introduce extra complex neural modules to capture the label correlations, in addition to the prediction modules. We found that by using contrastive learning in the supervised setting, we can exploit label information effectively, and learn meaningful feature and label embeddings capturing both the label correlations and predictive power, without extra neural modules. Our method also adopts the idea of learning and aligning latent spaces for both features and labels. C-GMVAE imposes a Gaussian mixture structure on the latent space, to alleviate posterior collapse and over-regularization issues, in contrast to previous works based on a unimodal prior. C-GMVAE outperforms existing methods on multiple public datasets and can often match other models' full performance with only 50% of the training data. Furthermore, we show that the learnt embeddings provide insights into the interpretation of label-label interactions.
Materials Representation and Transfer Learning for Multi-Property Prediction
Jun 18, 2021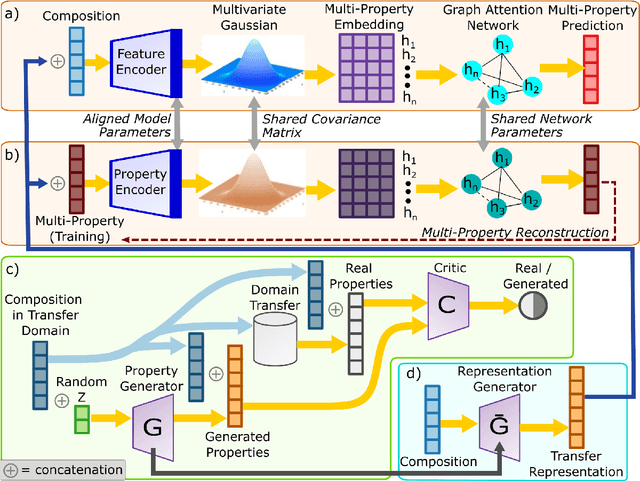
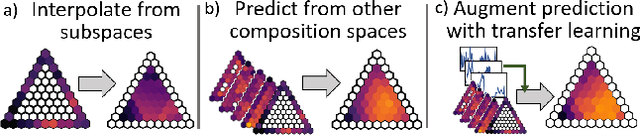

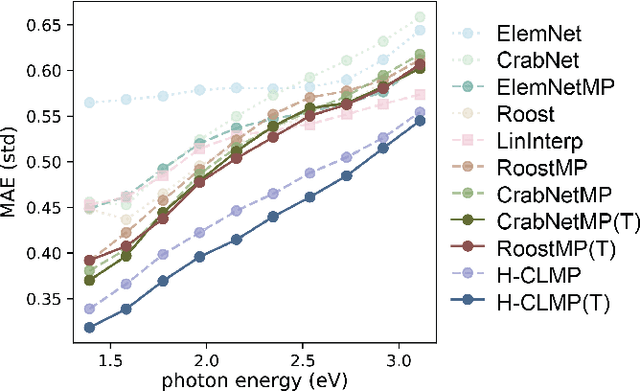
The adoption of machine learning in materials science has rapidly transformed materials property prediction. Hurdles limiting full capitalization of recent advancements in machine learning include the limited development of methods to learn the underlying interactions of multiple elements, as well as the relationships among multiple properties, to facilitate property prediction in new composition spaces. To address these issues, we introduce the Hierarchical Correlation Learning for Multi-property Prediction (H-CLMP) framework that seamlessly integrates (i) prediction using only a material's composition, (ii) learning and exploitation of correlations among target properties in multi-target regression, and (iii) leveraging training data from tangential domains via generative transfer learning. The model is demonstrated for prediction of spectral optical absorption of complex metal oxides spanning 69 3-cation metal oxide composition spaces. H-CLMP accurately predicts non-linear composition-property relationships in composition spaces for which no training data is available, which broadens the purview of machine learning to the discovery of materials with exceptional properties. This achievement results from the principled integration of latent embedding learning, property correlation learning, generative transfer learning, and attention models. The best performance is obtained using H-CLMP with Transfer learning (H-CLMP(T)) wherein a generative adversarial network is trained on computational density of states data and deployed in the target domain to augment prediction of optical absorption from composition. H-CLMP(T) aggregates multiple knowledge sources with a framework that is well-suited for multi-target regression across the physical sciences.
HOT-VAE: Learning High-Order Label Correlation for Multi-Label Classification via Attention-Based Variational Autoencoders
Mar 09, 2021


Understanding how environmental characteristics affect bio-diversity patterns, from individual species to communities of species, is critical for mitigating effects of global change. A central goal for conservation planning and monitoring is the ability to accurately predict the occurrence of species communities and how these communities change over space and time. This in turn leads to a challenging and long-standing problem in the field of computer science - how to perform ac-curate multi-label classification with hundreds of labels? The key challenge of this problem is its exponential-sized output space with regards to the number of labels to be predicted.Therefore, it is essential to facilitate the learning process by exploiting correlations (or dependency) among labels. Previous methods mostly focus on modelling the correlation on label pairs; however, complex relations between real-world objects often go beyond second order. In this paper, we pro-pose a novel framework for multi-label classification, High-order Tie-in Variational Autoencoder (HOT-VAE), which per-forms adaptive high-order label correlation learning. We experimentally verify that our model outperforms the existing state-of-the-art approaches on a bird distribution dataset on both conventional F1 scores and a variety of ecological metrics. To show our method is general, we also perform empirical analysis on seven other public real-world datasets in several application domains, and Hot-VAE exhibits superior performance to previous methods.