 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Inference, Biomarker Discovery, Graph Neural Network, Feature Selection
Nov 17, 2025Biomarker discovery from high-throughput transcriptomic data is crucial for advancing precision medicine. However, existing methods often neglect gene-gene regulatory relationships and lack stability across datasets, leading to conflation of spurious correlations with genuine causal effects. To address these issues, we develop a causal graph neural network (Causal-GNN) method that integrates causal inference with multi-layer graph neural networks (GNNs). The key innovation is the incorporation of causal effect estimation for identifying stable biomarkers, coupled with a GNN-based propensity scoring mechanism that leverages cross-gene regulatory networks. Experimental results demonstrate that our method achieves consistently high predictive accuracy across four distinct datasets and four independent classifiers. Moreover, it enables the identification of more stable biomarkers compared to traditional methods. Our work provides a robust, efficient, and biologically interpretable tool for biomarker discovery, demonstrating strong potential for broad application across medical disciplines.
MIRNet: Integrating Constrained Graph-Based Reasoning with Pre-training for Diagnostic Medical Imaging
Nov 13, 2025Automated interpretation of medical images demands robust modeling of complex visual-semantic relationships while addressing annotation scarcity, label imbalance, and clinical plausibility constraints. We introduce MIRNet (Medical Image Reasoner Network), a novel framework that integrates self-supervised pre-training with constrained graph-based reasoning. Tongue image diagnosis is a particularly challenging domain that requires fine-grained visual and semantic understanding. Our approach leverages self-supervised masked autoencoder (MAE) to learn transferable visual representations from unlabeled data; employs graph attention networks (GAT) to model label correlations through expert-defined structured graphs; enforces clinical priors via constraint-aware optimization using KL divergence and regularization losses; and mitigates imbalance using asymmetric loss (ASL) and boosting ensembles. To address annotation scarcity, we also introduce TongueAtlas-4K, a comprehensive expert-curated benchmark comprising 4,000 images annotated with 22 diagnostic labels--representing the largest public dataset in tongue analysis. Validation shows our method achieves state-of-the-art performance. While optimized for tongue diagnosis, the framework readily generalizes to broader diagnostic medical imaging tasks.
Capturing Rich Behavior Representations: A Dynamic Action Semantic-Aware Graph Transformer for Video Captioning
Feb 19, 2025Existing video captioning methods merely provide shallow or simplistic representations of object behaviors, resulting in superficial and ambiguous descriptions. However, object behavior is dynamic and complex. To comprehensively capture the essence of object behavior, we propose a dynamic action semantic-aware graph transformer. Firstly, a multi-scale temporal modeling module is designed to flexibly learn long and short-term latent action features. It not only acquires latent action features across time scales, but also considers local latent action details, enhancing the coherence and sensitiveness of latent action representations. Secondly, a visual-action semantic aware module is proposed to adaptively capture semantic representations related to object behavior, enhancing the richness and accurateness of action representations. By harnessing the collaborative efforts of these two modules,we can acquire rich behavior representations to generate human-like natural descriptions. Finally, this rich behavior representations and object representations are used to construct a temporal objects-action graph, which is fed into the graph transformer to model the complex temporal dependencies between objects and actions. To avoid adding complexity in the inference phase, the behavioral knowledge of the objects will be distilled into a simple network through knowledge distillation. The experimental results on MSVD and MSR-VTT datasets demonstrate that the proposed method achieves significant performance improvements across multiple metrics.
Deep Attentive Belief Propagation: Integrating Reasoning and Learning for Solving Constraint Optimization Problems
Sep 24, 2022
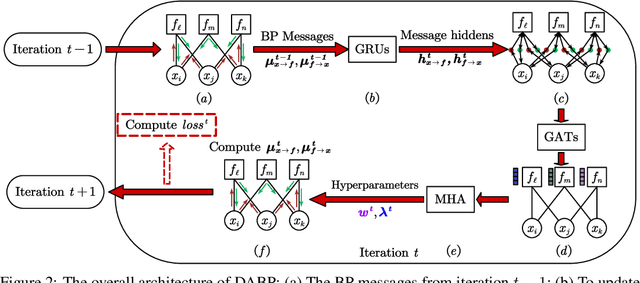
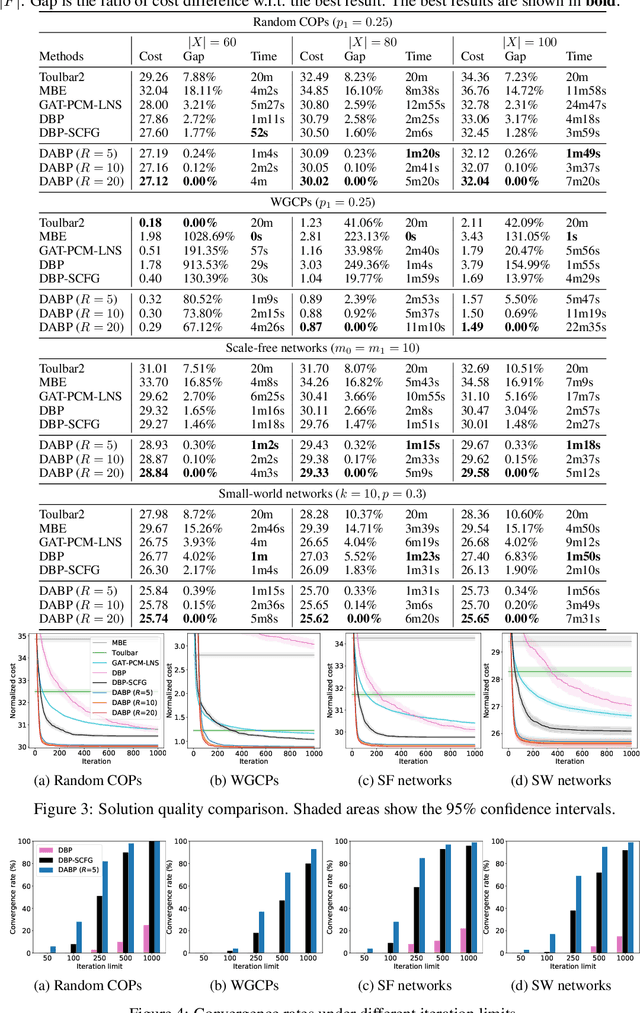
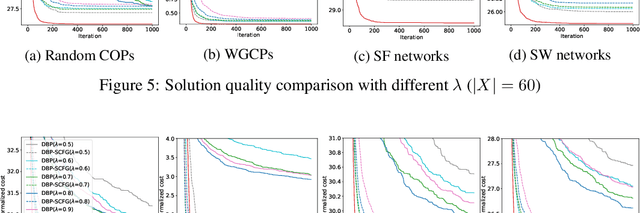
Belief Propagation (BP) is an important message-passing algorithm for various reasoning tasks over graphical models, including solving the Constraint Optimization Problems (COPs). It has been shown that BP can achieve state-of-the-art performance on various benchmarks by mixing old and new messages before sending the new one, i.e., damping. However, existing methods of tuning a static damping factor for BP not only are laborious but also harm their performance. Moreover, existing BP algorithms treat each variable node's neighbors equally when composing a new message, which also limits their exploration ability. To address these issues, we seamlessly integrate BP, Gated Recurrent Units (GRUs), and Graph Attention Networks (GATs) within the message-passing framework to reason about dynamic weights and damping factors for composing new BP messages. Our model, Deep Attentive Belief Propagation (DABP), takes the factor graph and the BP messages in each iteration as the input and infers the optimal weights and damping factors through GRUs and GATs, followed by a multi-head attention layer. Furthermore, unlike existing neural-based BP variants, we propose a novel self-supervised learning algorithm for DABP with a smoothed solution cost, which does not require expensive training labels and also avoids the common out-of-distribution issue through efficient online learning. Extensive experiments show that our model significantly outperforms state-of-the-art baselines.