 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLower-dimensional projections of cellular expression improves cell type classification from single-cell RNA sequencing
Oct 13, 2024



Single-cell RNA sequencing (scRNA-seq) enables the study of cellular diversity at single cell level. It provides a global view of cell-type specification during the onset of biological mechanisms such as developmental processes and human organogenesis. Various statistical, machine and deep learning-based methods have been proposed for cell-type classification. Most of the methods utilizes unsupervised lower dimensional projections obtained from for a large reference data. In this work, we proposed a reference-based method for cell type classification, called EnProCell. The EnProCell, first, computes lower dimensional projections that capture both the high variance and class separability through an ensemble of principle component analysis and multiple discriminant analysis. In the second phase, EnProCell trains a deep neural network on the lower dimensional representation of data to classify cell types. The proposed method outperformed the existing state-of-the-art methods when tested on four different data sets produced from different single-cell sequencing technologies. The EnProCell showed higher accuracy (98.91) and F1 score (98.64) than other methods for predicting reference from reference datasets. Similarly, EnProCell also showed better performance than existing methods in predicting cell types for data with unknown cell types (query) from reference datasets (accuracy:99.52; F1 score: 99.07). In addition to improved performance, the proposed methodology is simple and does not require more computational resources and time. the EnProCell is available at https://github.com/umar1196/EnProCell.
FLIQS: One-Shot Mixed-Precision Floating-Point and Integer Quantization Search
Aug 07, 2023


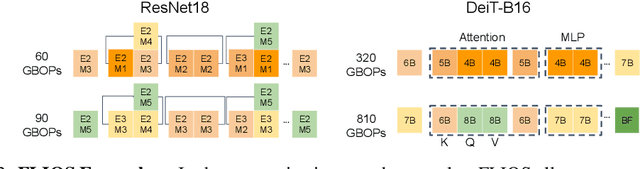
Quantization has become a mainstream compression technique for reducing model size, computational requirements, and energy consumption for modern deep neural networks (DNNs). With the improved numerical support in recent hardware, including multiple variants of integer and floating point, mixed-precision quantization has become necessary to achieve high-quality results with low model cost. Prior mixed-precision quantization methods have performed a post-training quantization search, which compromises on accuracy, or a differentiable quantization search, which leads to high memory usage from branching. Therefore, we propose the first one-shot mixed-precision quantization search that eliminates the need for retraining in both integer and low-precision floating point models. We evaluate our floating-point and integer quantization search (FLIQS) on multiple convolutional networks and vision transformer models to discover Pareto-optimal models. Our approach discovers models that improve upon uniform precision, manual mixed-precision, and recent integer quantization search methods. With the proposed integer quantization search, we increase the accuracy of ResNet-18 on ImageNet by 1.31% points and ResNet-50 by 0.90% points with equivalent model cost over previous methods. Additionally, for the first time, we explore a novel mixed-precision floating-point search and improve MobileNetV2 by up to 0.98% points compared to prior state-of-the-art FP8 models. Finally, we extend FLIQS to simultaneously search a joint quantization and neural architecture space and improve the ImageNet accuracy by 2.69% points with similar model cost on a MobileNetV2 search space.
GuardNN: Secure DNN Accelerator for Privacy-Preserving Deep Learning
Aug 26, 2020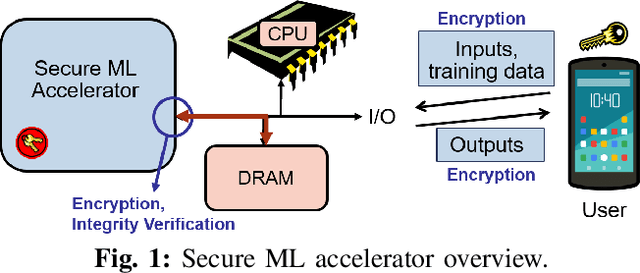
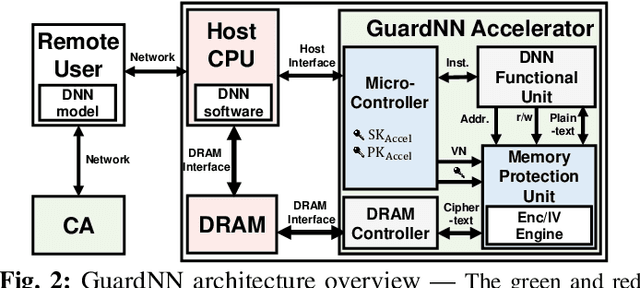
This paper proposes GuardNN, a secure deep neural network (DNN) accelerator, which provides strong hardware-based protection for user data and model parameters even in an untrusted environment. GuardNN shows that the architecture and protection can be customized for a specific application to provide strong confidentiality and integrity protection with negligible overhead. The design of the GuardNN instruction set reduces the TCB to just the accelerator and enables confidentiality protection without the overhead of integrity protection. GuardNN also introduces a new application-specific memory protection scheme to minimize the overhead of memory encryption and integrity verification. The scheme shows that most of the off-chip meta-data in today's state-of-the-art memory protection can be removed by exploiting the known memory access patterns of a DNN accelerator. GuardNN is implemented as an FPGA prototype, which demonstrates effective protection with less than 2% performance overhead for inference over a variety of modern DNN models.
MgX: Near-Zero Overhead Memory Protection with an Application to Secure DNN Acceleration
Apr 20, 2020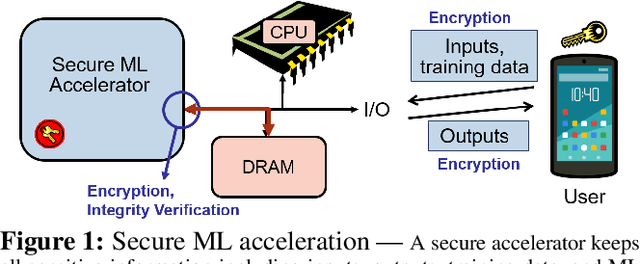

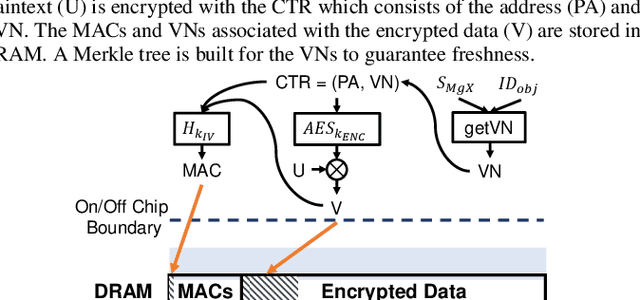
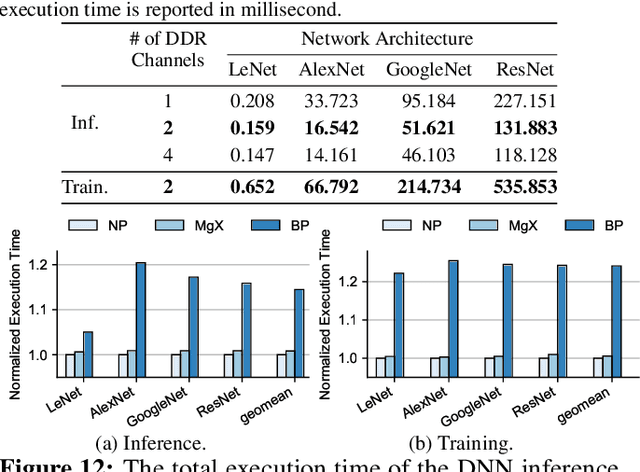
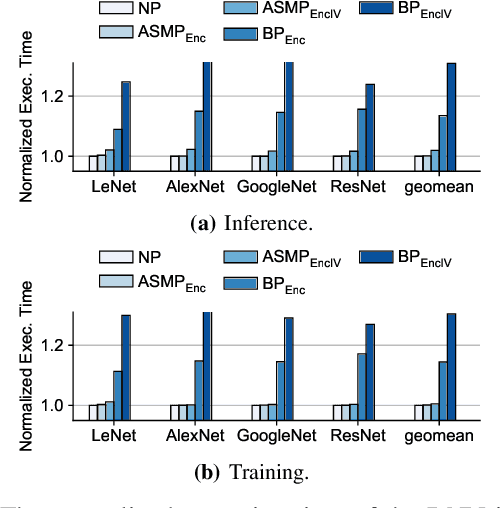
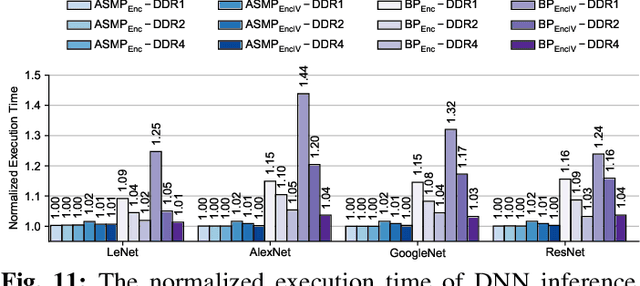
In this paper, we propose MgX, a near-zero overhead memory protection scheme for hardware accelerators. MgX minimizes the performance overhead of off-chip memory encryption and integrity verification by exploiting the application-specific aspect of accelerators. Accelerators tend to explicitly manage data movement between on-chip and off-chip memory, typically at an object granularity that is much larger than cache lines. Exploiting these accelerator-specific characteristics, MgX generates version numbers used in memory encryption and integrity verification only using on-chip state without storing them in memory, and also customizes the granularity of the memory protection to match the granularity used by the accelerator. To demonstrate the applicability of MgX, we present an in-depth study of MgX for deep neural network (DNN) and also describe implementations for H.264 video decoding and genome alignment. Experimental results show that applying MgX has less than 1% performance overhead for both DNN inference and training on state-of-the-art DNN architectures.