 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Learning of Point Clouds via Orientation Estimation
Aug 01, 2020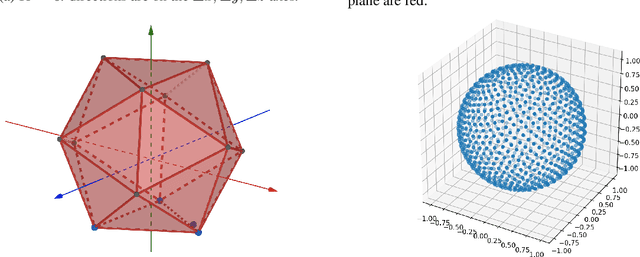

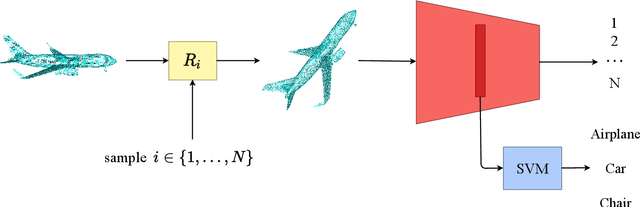
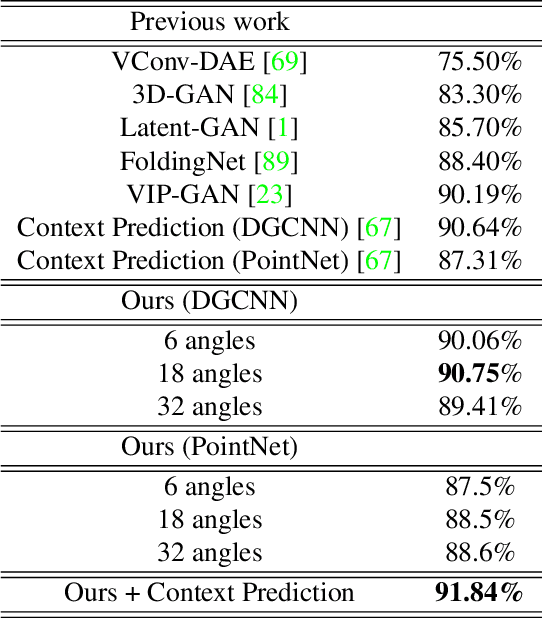
Point clouds provide a compact and efficient representation of 3D shapes. While deep neural networks have achieved impressive results on point cloud learning tasks, they require massive amounts of manually labeled data, which can be costly and time-consuming to collect. In this paper, we leverage 3D self-supervision for learning downstream tasks on point clouds with fewer labels. A point cloud can be rotated in infinitely many ways, which provides a rich label-free source for self-supervision. We consider the auxiliary task of predicting rotations that in turn leads to useful features for other tasks such as shape classification and 3D keypoint prediction. Using experiments on ShapeNet and ModelNet, we demonstrate that our approach outperforms the state-of-the-art. Moreover, features learned by our model are complementary to other self-supervised methods and combining them leads to further performance improvement.
Precision Gating: Improving Neural Network Efficiency with Dynamic Dual-Precision Activations
Feb 17, 2020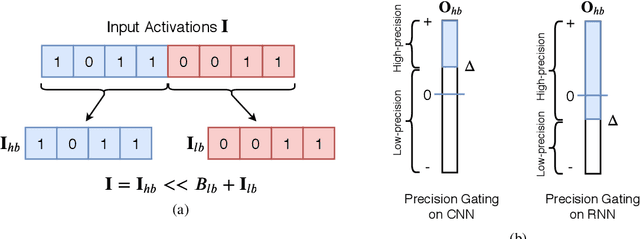
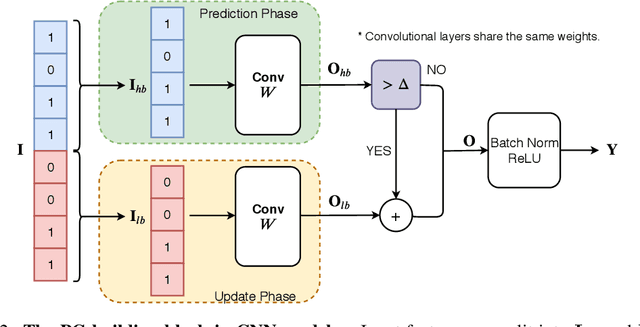
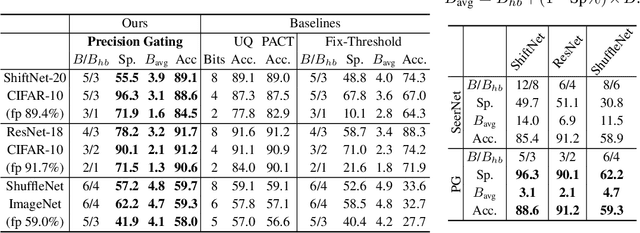
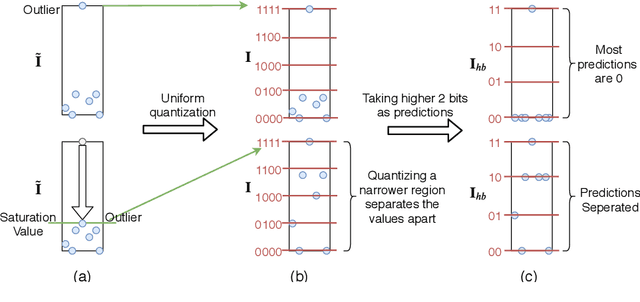
We propose precision gating (PG), an end-to-end trainable dynamic dual-precision quantization technique for deep neural networks. PG computes most features in a low precision and only a small proportion of important features in a higher precision to preserve accuracy. The proposed approach is applicable to a variety of DNN architectures and significantly reduces the computational cost of DNN execution with almost no accuracy loss. Our experiments indicate that PG achieves excellent results on CNNs, including statically compressed mobile-friendly networks such as ShuffleNet. Compared to the state-of-the-art prediction-based quantization schemes, PG achieves the same or higher accuracy with 2.4$\times$ less compute on ImageNet. PG furthermore applies to RNNs. Compared to 8-bit uniform quantization, PG obtains a 1.2% improvement in perplexity per word with 2.7$\times$ computational cost reduction on LSTM on the Penn Tree Bank dataset.
Autonomous Driving in Reality with Reinforcement Learning and Image Translation
Jan 13, 2018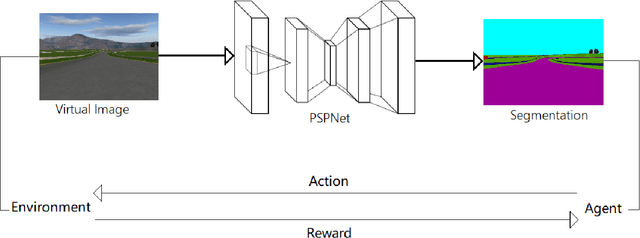



Supervised learning is widely used in training autonomous driving vehicle. However, it is trained with large amount of supervised labeled data. Reinforcement learning can be trained without abundant labeled data, but we cannot train it in reality because it would involve many unpredictable accidents. Nevertheless, training an agent with good performance in virtual environment is relatively much easier. Because of the huge difference between virtual and real, how to fill the gap between virtual and real is challenging. In this paper, we proposed a novel framework of reinforcement learning with image semantic segmentation network to make the whole model adaptable to reality. The agent is trained in TORCS, a car racing simulator.