 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentMoE: Toward Optimal Accuracy per FLOP and Parameter in Mixture of Experts
Jan 26, 2026Mixture of Experts (MoEs) have become a central component of many state-of-the-art open-source and proprietary large language models. Despite their widespread adoption, it remains unclear how close existing MoE architectures are to optimal with respect to inference cost, as measured by accuracy per floating-point operation and per parameter. In this work, we revisit MoE design from a hardware-software co-design perspective, grounded in empirical and theoretical considerations. We characterize key performance bottlenecks across diverse deployment regimes, spanning offline high-throughput execution and online, latency-critical inference. Guided by these insights, we introduce LatentMoE, a new model architecture resulting from systematic design exploration and optimized for maximal accuracy per unit of compute. Empirical design space exploration at scales of up to 95B parameters and over a 1T-token training horizon, together with supporting theoretical analysis, shows that LatentMoE consistently outperforms standard MoE architectures in terms of accuracy per FLOP and per parameter. Given its strong performance, the LatentMoE architecture has been adopted by the flagship Nemotron-3 Super and Ultra models and scaled to substantially larger regimes, including longer token horizons and larger model sizes, as reported in Nvidia et al. (arXiv:2512.20856).
Beyond the Buzz: A Pragmatic Take on Inference Disaggregation
Jun 05, 2025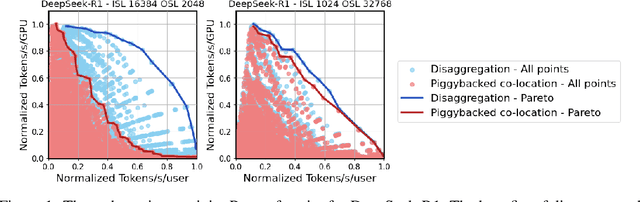

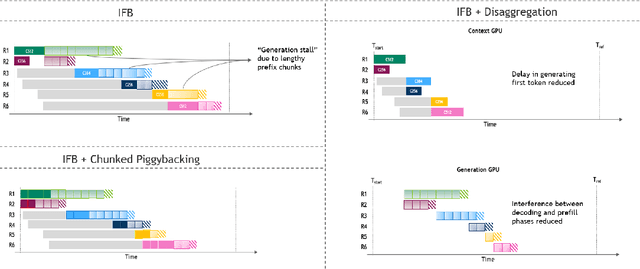
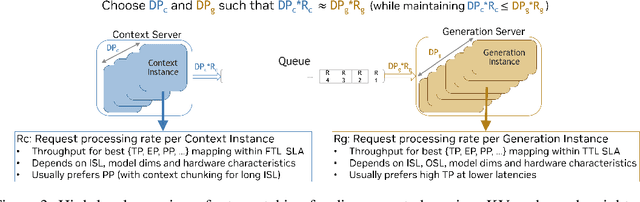
As inference scales to multi-node deployments, disaggregation - splitting inference into distinct phases - offers a promising path to improving the throughput-interactivity Pareto frontier. Despite growing enthusiasm and a surge of open-source efforts, practical deployment of disaggregated serving remains limited due to the complexity of the optimization search space and system-level coordination. In this paper, we present the first systematic study of disaggregated inference at scale, evaluating hundreds of thousands of design points across diverse workloads and hardware configurations. We find that disaggregation is most effective for prefill-heavy traffic patterns and larger models. Our results highlight the critical role of dynamic rate matching and elastic scaling in achieving Pareto-optimal performance. Our findings offer actionable insights for efficient disaggregated deployments to navigate the trade-off between system throughput and interactivity.
ResMoE: Space-efficient Compression of Mixture of Experts LLMs via Residual Restoration
Mar 10, 2025Mixture-of-Experts (MoE) Transformer, the backbone architecture of multiple phenomenal language models, leverages sparsity by activating only a fraction of model parameters for each input token. The sparse structure, while allowing constant time costs, results in space inefficiency: we still need to load all the model parameters during inference. We introduce ResMoE, an innovative MoE approximation framework that utilizes Wasserstein barycenter to extract a common expert (barycenter expert) and approximate the residuals between this barycenter expert and the original ones. ResMoE enhances the space efficiency for inference of large-scale MoE Transformers in a one-shot and data-agnostic manner without retraining while maintaining minimal accuracy loss, thereby paving the way for broader accessibility to large language models. We demonstrate the effectiveness of ResMoE through extensive experiments on Switch Transformer, Mixtral, and DeepSeekMoE models. The results show that ResMoE can reduce the number of parameters in an expert by up to 75% while maintaining comparable performance. The code is available at https://github.com/iDEA-iSAIL-Lab-UIUC/ResMoE.
RocketKV: Accelerating Long-Context LLM Inference via Two-Stage KV Cache Compression
Feb 19, 2025



Transformer-based Large Language Models rely critically on KV cache to efficiently handle extended contexts during the decode phase. Yet, the size of the KV cache grows proportionally with the input length, burdening both memory bandwidth and capacity as decoding progresses. To address this challenge, we present RocketKV, a training-free KV cache compression strategy designed specifically to reduce both memory bandwidth and capacity demand of KV cache during the decode phase. RocketKV contains two consecutive stages. In the first stage, it performs coarse-grain KV cache eviction on the input sequence tokens with SnapKV++, a method improved upon SnapKV by introducing adaptive pooling size and full compatibility with grouped-query attention. In the second stage, it adopts a hybrid attention method to conduct fine-grain top-k sparse attention, approximating the attention scores by leveraging both head and sequence dimensional reductions. Combining these two stages, RocketKV achieves significant KV cache fetching bandwidth and storage savings while maintaining comparable accuracy to full KV cache attention. We show that RocketKV provides end-to-end speedup by up to 3$\times$ as well as peak memory reduction by up to 31% in the decode phase on an NVIDIA H100 GPU compared to the full KV cache baseline, while achieving negligible accuracy loss on a variety of long-context tasks.
Post-Training Quantization for 3D Medical Image Segmentation: A Practical Study on Real Inference Engines
Jan 28, 2025Quantizing deep neural networks ,reducing the precision (bit-width) of their computations, can remarkably decrease memory usage and accelerate processing, making these models more suitable for large-scale medical imaging applications with limited computational resources. However, many existing methods studied "fake quantization", which simulates lower precision operations during inference, but does not actually reduce model size or improve real-world inference speed. Moreover, the potential of deploying real 3D low-bit quantization on modern GPUs is still unexplored. In this study, we introduce a real post-training quantization (PTQ) framework that successfully implements true 8-bit quantization on state-of-the-art (SOTA) 3D medical segmentation models, i.e., U-Net, SegResNet, SwinUNETR, nnU-Net, UNesT, TransUNet, ST-UNet,and VISTA3D. Our approach involves two main steps. First, we use TensorRT to perform fake quantization for both weights and activations with unlabeled calibration dataset. Second, we convert this fake quantization into real quantization via TensorRT engine on real GPUs, resulting in real-world reductions in model size and inference latency. Extensive experiments demonstrate that our framework effectively performs 8-bit quantization on GPUs without sacrificing model performance. This advancement enables the deployment of efficient deep learning models in medical imaging applications where computational resources are constrained. The code and models have been released, including U-Net, TransUNet pretrained on the BTCV dataset for abdominal (13-label) segmentation, UNesT pretrained on the Whole Brain Dataset for whole brain (133-label) segmentation, and nnU-Net, SegResNet, SwinUNETR and VISTA3D pretrained on TotalSegmentator V2 for full body (104-label) segmentation. https://github.com/hrlblab/PTQ.
Microscaling Data Formats for Deep Learning
Oct 19, 2023



Narrow bit-width data formats are key to reducing the computational and storage costs of modern deep learning applications. This paper evaluates Microscaling (MX) data formats that combine a per-block scaling factor with narrow floating-point and integer types for individual elements. MX formats balance the competing needs of hardware efficiency, model accuracy, and user friction. Empirical results on over two dozen benchmarks demonstrate practicality of MX data formats as a drop-in replacement for baseline FP32 for AI inference and training with low user friction. We also show the first instance of training generative language models at sub-8-bit weights, activations, and gradients with minimal accuracy loss and no modifications to the training recipe.
Shared Microexponents: A Little Shifting Goes a Long Way
Feb 16, 2023



This paper introduces Block Data Representations (BDR), a framework for exploring and evaluating a wide spectrum of narrow-precision formats for deep learning. It enables comparison of popular quantization standards, and through BDR, new formats based on shared microexponents (MX) are identified, which outperform other state-of-the-art quantization approaches, including narrow-precision floating-point and block floating-point. MX utilizes multiple levels of quantization scaling with ultra-fine scaling factors based on shared microexponents in the hardware. The effectiveness of MX is demonstrated on real-world models including large-scale generative pretraining and inferencing, and production-scale recommendation systems.
Precision Gating: Improving Neural Network Efficiency with Dynamic Dual-Precision Activations
Feb 17, 2020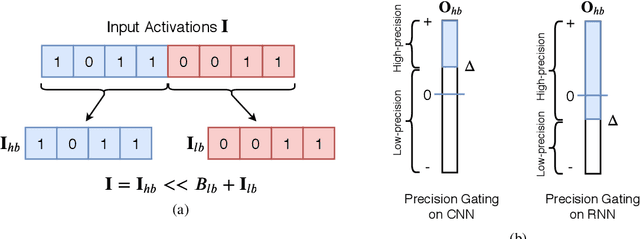
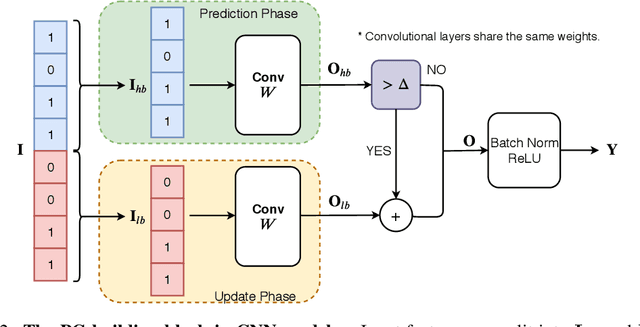
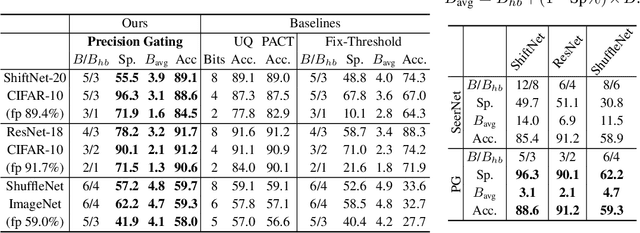
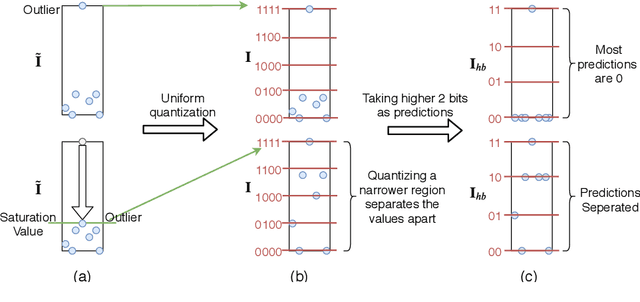
We propose precision gating (PG), an end-to-end trainable dynamic dual-precision quantization technique for deep neural networks. PG computes most features in a low precision and only a small proportion of important features in a higher precision to preserve accuracy. The proposed approach is applicable to a variety of DNN architectures and significantly reduces the computational cost of DNN execution with almost no accuracy loss. Our experiments indicate that PG achieves excellent results on CNNs, including statically compressed mobile-friendly networks such as ShuffleNet. Compared to the state-of-the-art prediction-based quantization schemes, PG achieves the same or higher accuracy with 2.4$\times$ less compute on ImageNet. PG furthermore applies to RNNs. Compared to 8-bit uniform quantization, PG obtains a 1.2% improvement in perplexity per word with 2.7$\times$ computational cost reduction on LSTM on the Penn Tree Bank dataset.
Overwrite Quantization: Opportunistic Outlier Handling for Neural Network Accelerators
Oct 13, 2019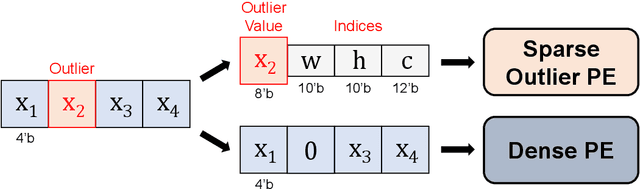
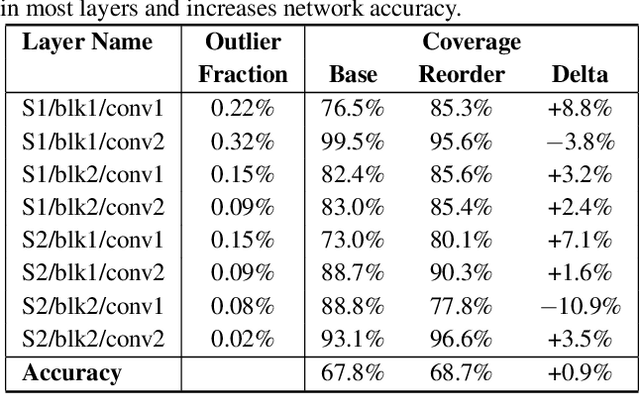
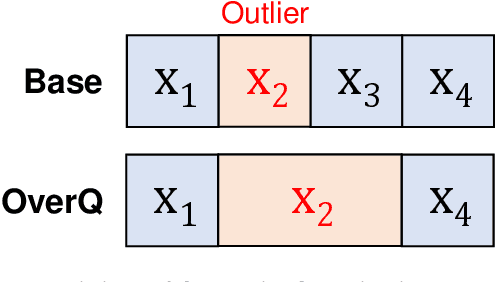
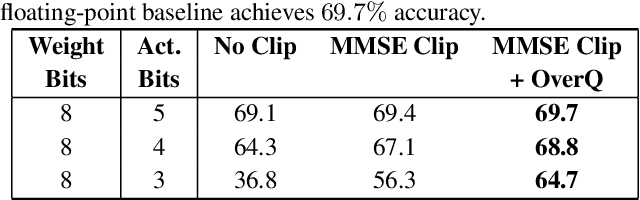
Outliers in weights and activations pose a key challenge for fixed-point quantization of neural networks. While outliers can be addressed by fine-tuning, this is not practical for machine learning (ML) service providers (e.g., Google, Microsoft) who often receive customers' models without the training data. Specialized hardware for handling outliers can enable low-precision DNNs, but incurs nontrivial area overhead. In this paper, we propose overwrite quantization (OverQ), a novel hardware technique which opportunistically increases bitwidth for outliers by letting them overwrite adjacent values. An FPGA prototype shows OverQ can significantly improve ResNet-18 accuracy at 4 bits while incurring relatively little increase in resource utilization.
Improving Neural Network Quantization without Retraining using Outlier Channel Splitting
Jan 30, 2019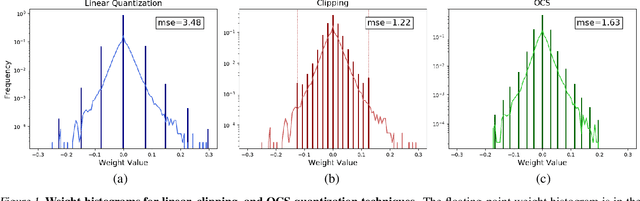
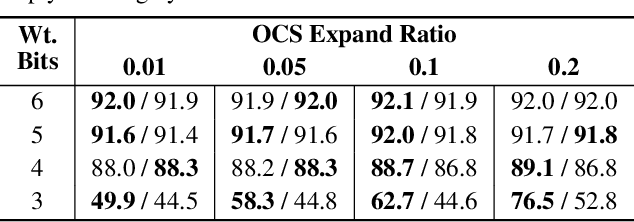
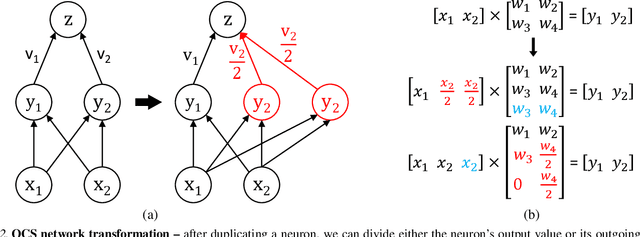
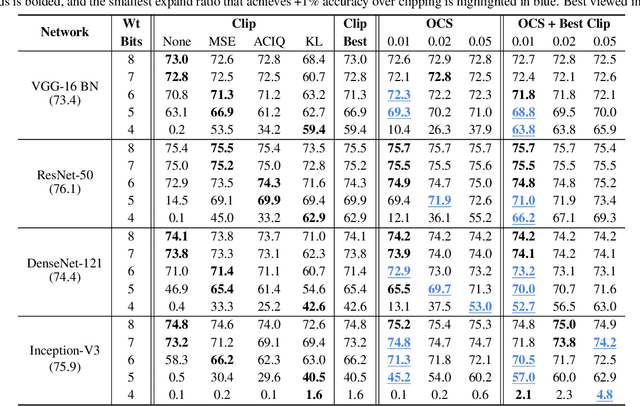
Quantization can improve the execution latency and energy efficiency of neural networks on both commodity GPUs and specialized accelerators. The majority of existing literature focuses on training quantized DNNs, while this work examines the less-studied topic of quantizing a floating-point model without (re)training. DNN weights and activations follow a bell-shaped distribution post-training, while practical hardware uses a linear quantization grid. This leads to challenges in dealing with outliers in the distribution. Prior work has addressed this by clipping the outliers or using specialized hardware. In this work, we propose outlier channel splitting (OCS), which duplicates channels containing outliers, then halves the channel values. The network remains functionally identical, but affected outliers are moved toward the center of the distribution. OCS requires no additional training and works on commodity hardware. Experimental evaluation on ImageNet classification and language modeling shows that OCS can outperform state-of-the-art clipping techniques with only minor overhead.