 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentMoE: Toward Optimal Accuracy per FLOP and Parameter in Mixture of Experts
Jan 26, 2026Mixture of Experts (MoEs) have become a central component of many state-of-the-art open-source and proprietary large language models. Despite their widespread adoption, it remains unclear how close existing MoE architectures are to optimal with respect to inference cost, as measured by accuracy per floating-point operation and per parameter. In this work, we revisit MoE design from a hardware-software co-design perspective, grounded in empirical and theoretical considerations. We characterize key performance bottlenecks across diverse deployment regimes, spanning offline high-throughput execution and online, latency-critical inference. Guided by these insights, we introduce LatentMoE, a new model architecture resulting from systematic design exploration and optimized for maximal accuracy per unit of compute. Empirical design space exploration at scales of up to 95B parameters and over a 1T-token training horizon, together with supporting theoretical analysis, shows that LatentMoE consistently outperforms standard MoE architectures in terms of accuracy per FLOP and per parameter. Given its strong performance, the LatentMoE architecture has been adopted by the flagship Nemotron-3 Super and Ultra models and scaled to substantially larger regimes, including longer token horizons and larger model sizes, as reported in Nvidia et al. (arXiv:2512.20856).
Beyond the Buzz: A Pragmatic Take on Inference Disaggregation
Jun 05, 2025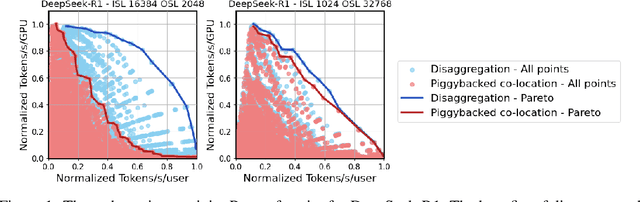

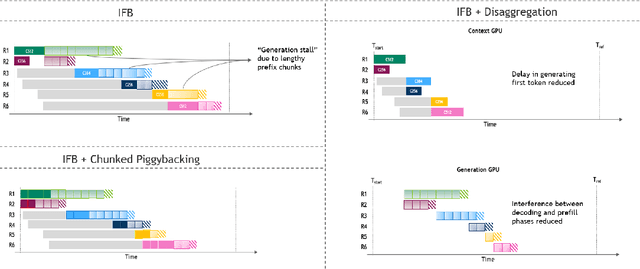
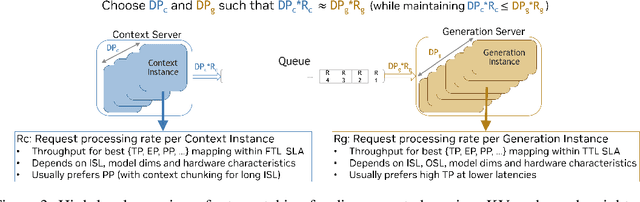
As inference scales to multi-node deployments, disaggregation - splitting inference into distinct phases - offers a promising path to improving the throughput-interactivity Pareto frontier. Despite growing enthusiasm and a surge of open-source efforts, practical deployment of disaggregated serving remains limited due to the complexity of the optimization search space and system-level coordination. In this paper, we present the first systematic study of disaggregated inference at scale, evaluating hundreds of thousands of design points across diverse workloads and hardware configurations. We find that disaggregation is most effective for prefill-heavy traffic patterns and larger models. Our results highlight the critical role of dynamic rate matching and elastic scaling in achieving Pareto-optimal performance. Our findings offer actionable insights for efficient disaggregated deployments to navigate the trade-off between system throughput and interactivity.
Shaping Human-AI Collaboration: Varied Scaffolding Levels in Co-writing with Language Models
Feb 18, 2024
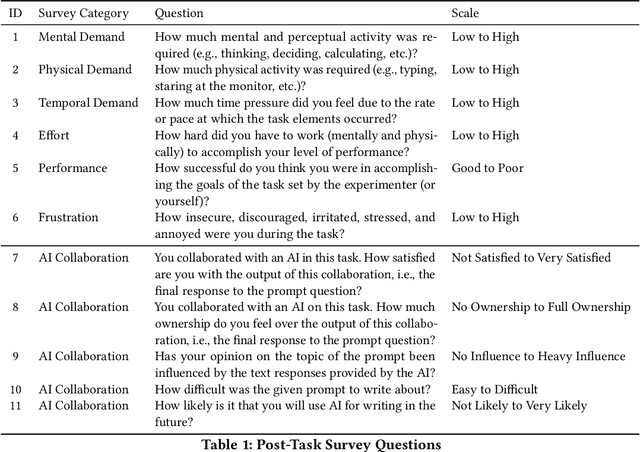

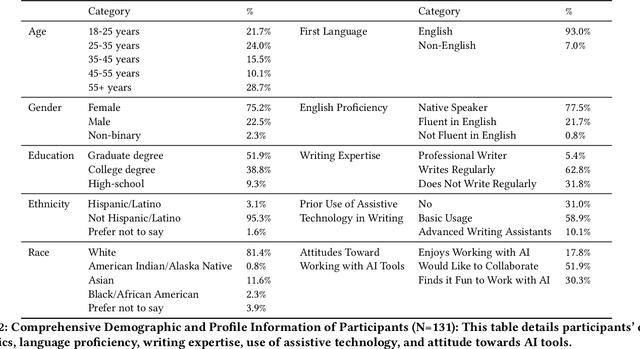
Advances in language modeling have paved the way for novel human-AI co-writing experiences. This paper explores how varying levels of scaffolding from large language models (LLMs) shape the co-writing process. Employing a within-subjects field experiment with a Latin square design, we asked participants (N=131) to respond to argumentative writing prompts under three randomly sequenced conditions: no AI assistance (control), next-sentence suggestions (low scaffolding), and next-paragraph suggestions (high scaffolding). Our findings reveal a U-shaped impact of scaffolding on writing quality and productivity (words/time). While low scaffolding did not significantly improve writing quality or productivity, high scaffolding led to significant improvements, especially benefiting non-regular writers and less tech-savvy users. No significant cognitive burden was observed while using the scaffolded writing tools, but a moderate decrease in text ownership and satisfaction was noted. Our results have broad implications for the design of AI-powered writing tools, including the need for personalized scaffolding mechanisms.
Microscaling Data Formats for Deep Learning
Oct 19, 2023



Narrow bit-width data formats are key to reducing the computational and storage costs of modern deep learning applications. This paper evaluates Microscaling (MX) data formats that combine a per-block scaling factor with narrow floating-point and integer types for individual elements. MX formats balance the competing needs of hardware efficiency, model accuracy, and user friction. Empirical results on over two dozen benchmarks demonstrate practicality of MX data formats as a drop-in replacement for baseline FP32 for AI inference and training with low user friction. We also show the first instance of training generative language models at sub-8-bit weights, activations, and gradients with minimal accuracy loss and no modifications to the training recipe.
Shared Microexponents: A Little Shifting Goes a Long Way
Feb 16, 2023



This paper introduces Block Data Representations (BDR), a framework for exploring and evaluating a wide spectrum of narrow-precision formats for deep learning. It enables comparison of popular quantization standards, and through BDR, new formats based on shared microexponents (MX) are identified, which outperform other state-of-the-art quantization approaches, including narrow-precision floating-point and block floating-point. MX utilizes multiple levels of quantization scaling with ultra-fine scaling factors based on shared microexponents in the hardware. The effectiveness of MX is demonstrated on real-world models including large-scale generative pretraining and inferencing, and production-scale recommendation systems.
Procrustes: a Dataflow and Accelerator for Sparse Deep Neural Network Training
Sep 23, 2020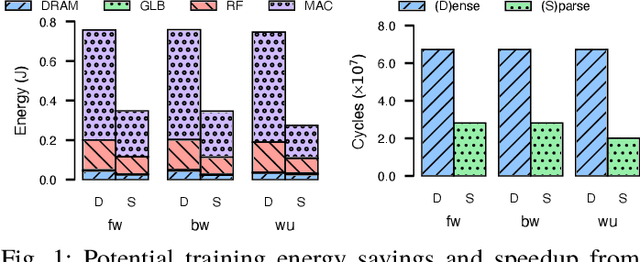
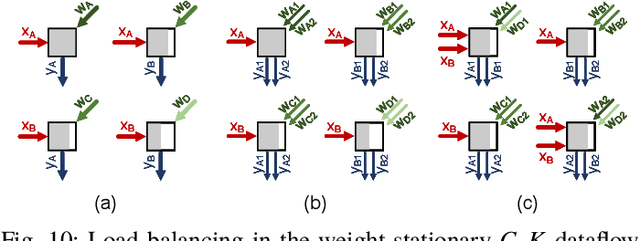

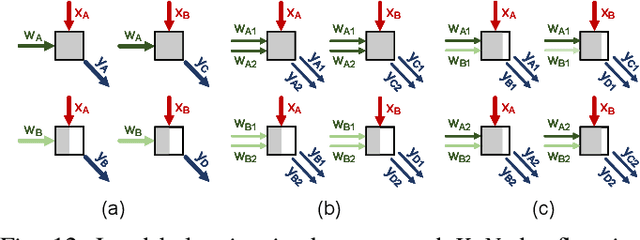
The success of DNN pruning has led to the development of energy-efficient inference accelerators that support pruned models with sparse weight and activation tensors. Because the memory layouts and dataflows in these architectures are optimized for the access patterns during $\mathit{inference}$, however, they do not efficiently support the emerging sparse $\mathit{training}$ techniques. In this paper, we demonstrate (a) that accelerating sparse training requires a co-design approach where algorithms are adapted to suit the constraints of hardware, and (b) that hardware for sparse DNN training must tackle constraints that do not arise in inference accelerators. As proof of concept, we adapt a sparse training algorithm to be amenable to hardware acceleration; we then develop dataflow, data layout, and load-balancing techniques to accelerate it. The resulting system is a sparse DNN training accelerator that produces pruned models with the same accuracy as dense models without first training, then pruning, and finally retraining, a dense model. Compared to training the equivalent unpruned models using a state-of-the-art DNN accelerator without sparse training support, Procrustes consumes up to 3.26$\times$ less energy and offers up to 4$\times$ speedup across a range of models, while pruning weights by an order of magnitude and maintaining unpruned accuracy.
DropBack: Continuous Pruning During Training
Jun 11, 2018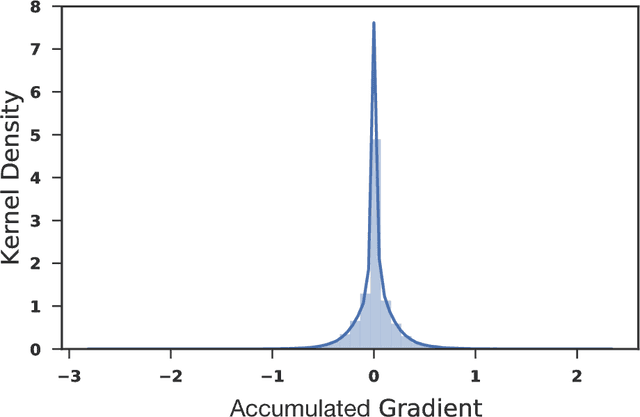
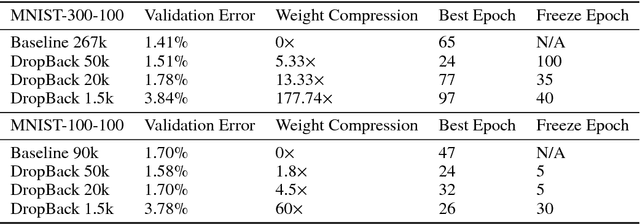
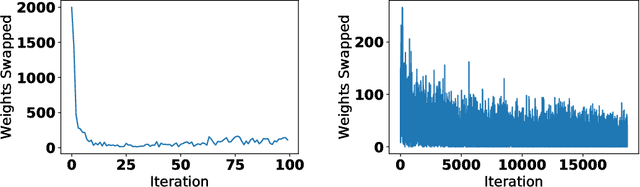
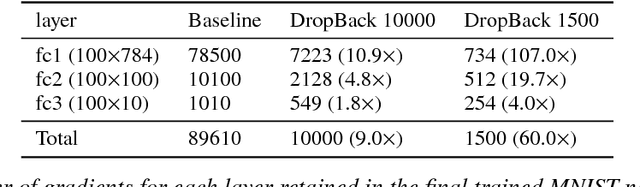
We introduce a technique that compresses deep neural networks both during and after training by constraining the total number of weights updated during backpropagation to those with the highest total gradients. The remaining weights are forgotten and their initial value is regenerated at every access to avoid storing them in memory. This dramatically reduces the number of off-chip memory accesses during both training and inference, a key component of the energy needs of DNN accelerators. By ensuring that the total weight diffusion remains close to that of baseline unpruned SGD, networks pruned using DropBack are able to maintain high accuracy across network architectures. We observe weight compression of 25x with LeNet-300-100 on MNIST while maintaining accuracy. On CIFAR-10, we see an approximately 5x weight compression on 3 models: an already 9x-reduced VGG-16, Densenet, and WRN-28-10 - all with zero or negligible accuracy loss. On Densenet and WRN, which are particularly challenging to compress, Both Densenet and WRN improve on the state of the art, achieving higher compression with better accuracy than prior pruning techniques.