 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH2PIPE: High throughput CNN Inference on FPGAs with High-Bandwidth Memory
Aug 17, 2024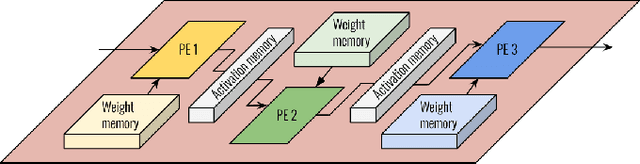
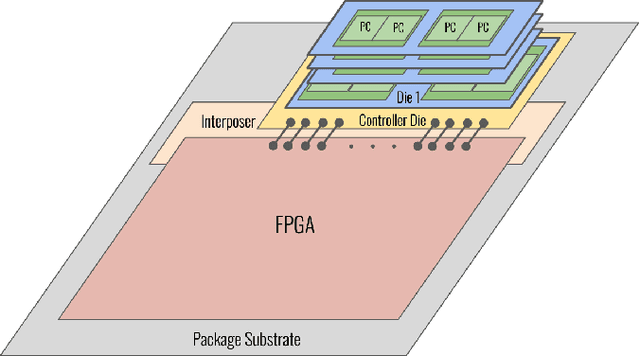
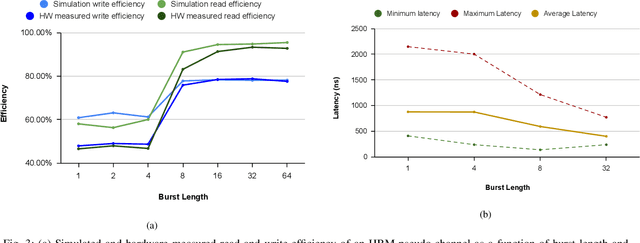
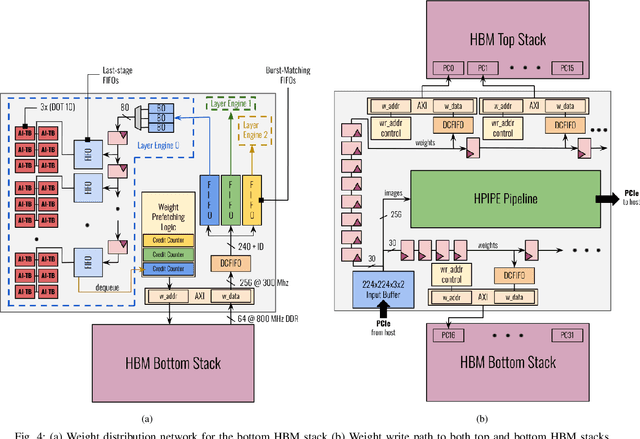
Convolutional Neural Networks (CNNs) combine large amounts of parallelizable computation with frequent memory access. Field Programmable Gate Arrays (FPGAs) can achieve low latency and high throughput CNN inference by implementing dataflow accelerators that pipeline layer-specific hardware to implement an entire network. By implementing a different processing element for each CNN layer, these layer-pipelined accelerators can achieve high compute density, but having all layers processing in parallel requires high memory bandwidth. Traditionally this has been satisfied by storing all weights on chip, but this is infeasible for the largest CNNs, which are often those most in need of acceleration. In this work we augment a state-of-the-art dataflow accelerator (HPIPE) to leverage both High-Bandwidth Memory (HBM) and on-chip storage, enabling high performance layer-pipelined dataflow acceleration of large CNNs. Based on profiling results of HBM's latency and throughput against expected address patterns, we develop an algorithm to choose which weight buffers should be moved off chip and how deep the on-chip FIFOs to HBM should be to minimize compute unit stalling. We integrate the new hardware generation within the HPIPE domain-specific CNN compiler and demonstrate good bandwidth efficiency against theoretical limits. Compared to the best prior work we obtain speed-ups of at least 19.4x, 5.1x and 10.5x on ResNet-18, ResNet-50 and VGG-16 respectively.
Microscaling Data Formats for Deep Learning
Oct 19, 2023



Narrow bit-width data formats are key to reducing the computational and storage costs of modern deep learning applications. This paper evaluates Microscaling (MX) data formats that combine a per-block scaling factor with narrow floating-point and integer types for individual elements. MX formats balance the competing needs of hardware efficiency, model accuracy, and user friction. Empirical results on over two dozen benchmarks demonstrate practicality of MX data formats as a drop-in replacement for baseline FP32 for AI inference and training with low user friction. We also show the first instance of training generative language models at sub-8-bit weights, activations, and gradients with minimal accuracy loss and no modifications to the training recipe.
Shared Microexponents: A Little Shifting Goes a Long Way
Feb 16, 2023



This paper introduces Block Data Representations (BDR), a framework for exploring and evaluating a wide spectrum of narrow-precision formats for deep learning. It enables comparison of popular quantization standards, and through BDR, new formats based on shared microexponents (MX) are identified, which outperform other state-of-the-art quantization approaches, including narrow-precision floating-point and block floating-point. MX utilizes multiple levels of quantization scaling with ultra-fine scaling factors based on shared microexponents in the hardware. The effectiveness of MX is demonstrated on real-world models including large-scale generative pretraining and inferencing, and production-scale recommendation systems.
Neighbors From Hell: Voltage Attacks Against Deep Learning Accelerators on Multi-Tenant FPGAs
Dec 14, 2020



Field-programmable gate arrays (FPGAs) are becoming widely used accelerators for a myriad of datacenter applications due to their flexibility and energy efficiency. Among these applications, FPGAs have shown promising results in accelerating low-latency real-time deep learning (DL) inference, which is becoming an indispensable component of many end-user applications. With the emerging research direction towards virtualized cloud FPGAs that can be shared by multiple users, the security aspect of FPGA-based DL accelerators requires careful consideration. In this work, we evaluate the security of DL accelerators against voltage-based integrity attacks in a multitenant FPGA scenario. We first demonstrate the feasibility of such attacks on a state-of-the-art Stratix 10 card using different attacker circuits that are logically and physically isolated in a separate attacker role, and cannot be flagged as malicious circuits by conventional bitstream checkers. We show that aggressive clock gating, an effective power-saving technique, can also be a potential security threat in modern FPGAs. Then, we carry out the attack on a DL accelerator running ImageNet classification in the victim role to evaluate the inherent resilience of DL models against timing faults induced by the adversary. We find that even when using the strongest attacker circuit, the prediction accuracy of the DL accelerator is not compromised when running at its safe operating frequency. Furthermore, we can achieve 1.18-1.31x higher inference performance by over-clocking the DL accelerator without affecting its prediction accuracy.