 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError Diffusion: Post Training Quantization with Block-Scaled Number Formats for Neural Networks
Oct 15, 2024



Quantization reduces the model's hardware costs, such as data movement, storage, and operations like multiply and addition. It also affects the model's behavior by degrading the output quality. Therefore, there is a need for methods that preserve the model's behavior when quantizing model parameters. More exotic numerical encodings, such as block-scaled number formats, have shown advantages for utilizing a fixed bit budget to encode model parameters. This paper presents error diffusion (ED), a hyperparameter-free method for post-training quantization with support for block-scaled data formats. Our approach does not rely on backpropagation or Hessian information. We describe how to improve the quantization process by viewing the neural model as a composite function and diffusing the quantization error in every layer. In addition, we introduce TensorCast, an open-source library based on PyTorch to emulate a variety of number formats, including the block-scaled ones, to aid the research in neural model quantization. We demonstrate the efficacy of our algorithm through rigorous testing on various architectures, including vision and large language models (LLMs), where it consistently delivers competitive results. Our experiments confirm that block-scaled data formats provide a robust choice for post-training quantization and could be used effectively to enhance the practical deployment of advanced neural networks.
Microscaling Data Formats for Deep Learning
Oct 19, 2023



Narrow bit-width data formats are key to reducing the computational and storage costs of modern deep learning applications. This paper evaluates Microscaling (MX) data formats that combine a per-block scaling factor with narrow floating-point and integer types for individual elements. MX formats balance the competing needs of hardware efficiency, model accuracy, and user friction. Empirical results on over two dozen benchmarks demonstrate practicality of MX data formats as a drop-in replacement for baseline FP32 for AI inference and training with low user friction. We also show the first instance of training generative language models at sub-8-bit weights, activations, and gradients with minimal accuracy loss and no modifications to the training recipe.
Tailor: Altering Skip Connections for Resource-Efficient Inference
Jan 18, 2023Deep neural networks use skip connections to improve training convergence. However, these skip connections are costly in hardware, requiring extra buffers and increasing on- and off-chip memory utilization and bandwidth requirements. In this paper, we show that skip connections can be optimized for hardware when tackled with a hardware-software codesign approach. We argue that while a network's skip connections are needed for the network to learn, they can later be removed or shortened to provide a more hardware efficient implementation with minimal to no accuracy loss. We introduce Tailor, a codesign tool whose hardware-aware training algorithm gradually removes or shortens a fully trained network's skip connections to lower their hardware cost. The optimized hardware designs improve resource utilization by up to 34% for BRAMs, 13% for FFs, and 16% for LUTs.
Hardware-efficient Residual Networks for FPGAs
Feb 02, 2021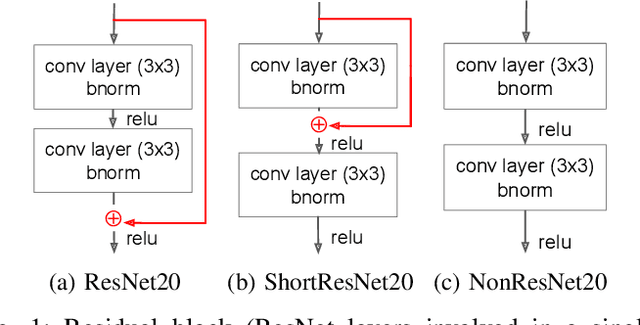
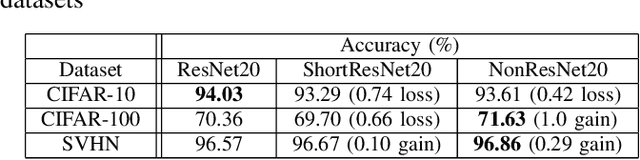
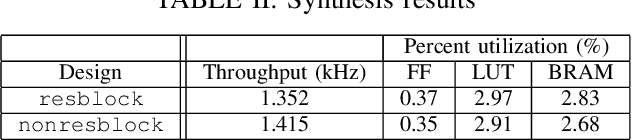
Residual networks (ResNets) employ skip connections in their networks -- reusing activations from previous layers -- to improve training convergence, but these skip connections create challenges for hardware implementations of ResNets. The hardware must either wait for skip connections to be processed before processing more incoming data or buffer them elsewhere. Without skip connections, ResNets would be more hardware-efficient. Thus, we present the teacher-student learning method to gradually prune away all of a ResNet's skip connections, constructing a network we call NonResNet. We show that when implemented for FPGAs, NonResNet decreases ResNet's BRAM utilization by 9% and LUT utilization by 3% and increases throughput by 5%.