 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoss Landscape Analysis for Reliable Quantized ML Models for Scientific Sensing
Feb 12, 2025In this paper, we propose a method to perform empirical analysis of the loss landscape of machine learning (ML) models. The method is applied to two ML models for scientific sensing, which necessitates quantization to be deployed and are subject to noise and perturbations due to experimental conditions. Our method allows assessing the robustness of ML models to such effects as a function of quantization precision and under different regularization techniques -- two crucial concerns that remained underexplored so far. By investigating the interplay between performance, efficiency, and robustness by means of loss landscape analysis, we both established a strong correlation between gently-shaped landscapes and robustness to input and weight perturbations and observed other intriguing and non-obvious phenomena. Our method allows a systematic exploration of such trade-offs a priori, i.e., without training and testing multiple models, leading to more efficient development workflows. This work also highlights the importance of incorporating robustness into the Pareto optimization of ML models, enabling more reliable and adaptive scientific sensing systems.
Reliable edge machine learning hardware for scientific applications
Jun 27, 2024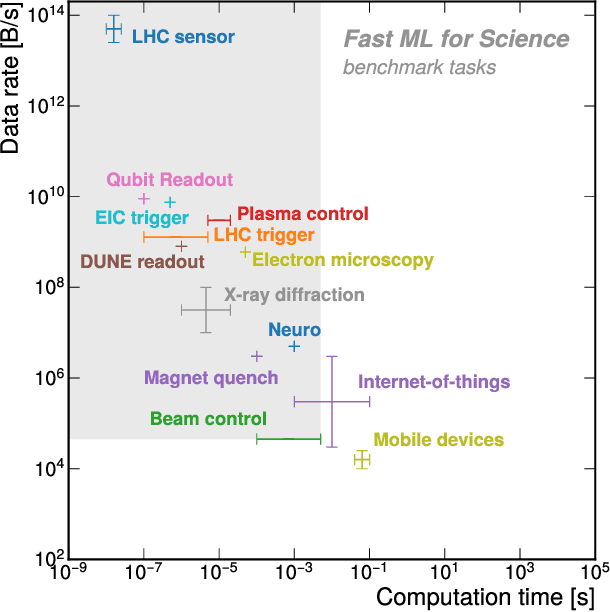
Extreme data rate scientific experiments create massive amounts of data that require efficient ML edge processing. This leads to unique validation challenges for VLSI implementations of ML algorithms: enabling bit-accurate functional simulations for performance validation in experimental software frameworks, verifying those ML models are robust under extreme quantization and pruning, and enabling ultra-fine-grained model inspection for efficient fault tolerance. We discuss approaches to developing and validating reliable algorithms at the scientific edge under such strict latency, resource, power, and area requirements in extreme experimental environments. We study metrics for developing robust algorithms, present preliminary results and mitigation strategies, and conclude with an outlook of these and future directions of research towards the longer-term goal of developing autonomous scientific experimentation methods for accelerated scientific discovery.
Architectural Implications of Neural Network Inference for High Data-Rate, Low-Latency Scientific Applications
Mar 13, 2024


With more scientific fields relying on neural networks (NNs) to process data incoming at extreme throughputs and latencies, it is crucial to develop NNs with all their parameters stored on-chip. In many of these applications, there is not enough time to go off-chip and retrieve weights. Even more so, off-chip memory such as DRAM does not have the bandwidth required to process these NNs as fast as the data is being produced (e.g., every 25 ns). As such, these extreme latency and bandwidth requirements have architectural implications for the hardware intended to run these NNs: 1) all NN parameters must fit on-chip, and 2) codesigning custom/reconfigurable logic is often required to meet these latency and bandwidth constraints. In our work, we show that many scientific NN applications must run fully on chip, in the extreme case requiring a custom chip to meet such stringent constraints.
Tailor: Altering Skip Connections for Resource-Efficient Inference
Jan 18, 2023



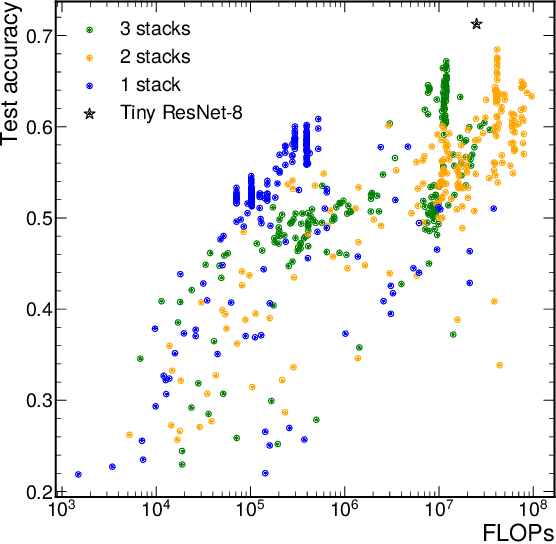
Deep neural networks use skip connections to improve training convergence. However, these skip connections are costly in hardware, requiring extra buffers and increasing on- and off-chip memory utilization and bandwidth requirements. In this paper, we show that skip connections can be optimized for hardware when tackled with a hardware-software codesign approach. We argue that while a network's skip connections are needed for the network to learn, they can later be removed or shortened to provide a more hardware efficient implementation with minimal to no accuracy loss. We introduce Tailor, a codesign tool whose hardware-aware training algorithm gradually removes or shortens a fully trained network's skip connections to lower their hardware cost. The optimized hardware designs improve resource utilization by up to 34% for BRAMs, 13% for FFs, and 16% for LUTs.
Open-source FPGA-ML codesign for the MLPerf Tiny Benchmark
Jun 23, 2022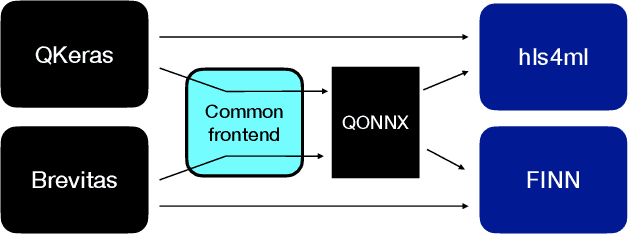
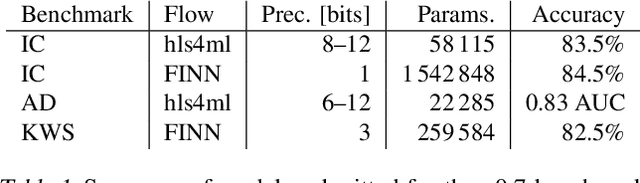
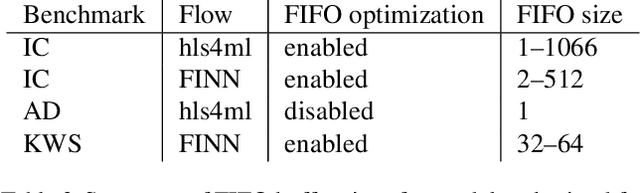
We present our development experience and recent results for the MLPerf Tiny Inference Benchmark on field-programmable gate array (FPGA) platforms. We use the open-source hls4ml and FINN workflows, which aim to democratize AI-hardware codesign of optimized neural networks on FPGAs. We present the design and implementation process for the keyword spotting, anomaly detection, and image classification benchmark tasks. The resulting hardware implementations are quantized, configurable, spatial dataflow architectures tailored for speed and efficiency and introduce new generic optimizations and common workflows developed as a part of this work. The full workflow is presented from quantization-aware training to FPGA implementation. The solutions are deployed on system-on-chip (Pynq-Z2) and pure FPGA (Arty A7-100T) platforms. The resulting submissions achieve latencies as low as 20 $\mu$s and energy consumption as low as 30 $\mu$J per inference. We demonstrate how emerging ML benchmarks on heterogeneous hardware platforms can catalyze collaboration and the development of new techniques and more accessible tools.
Neural Network Quantization for Efficient Inference: A Survey
Dec 08, 2021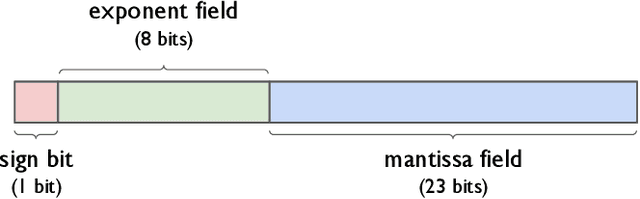
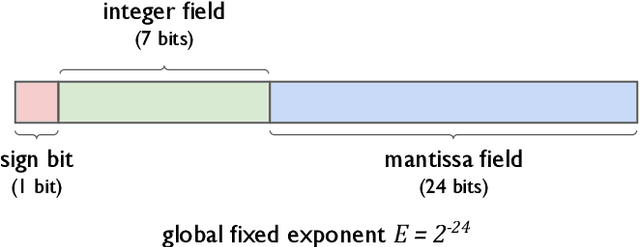
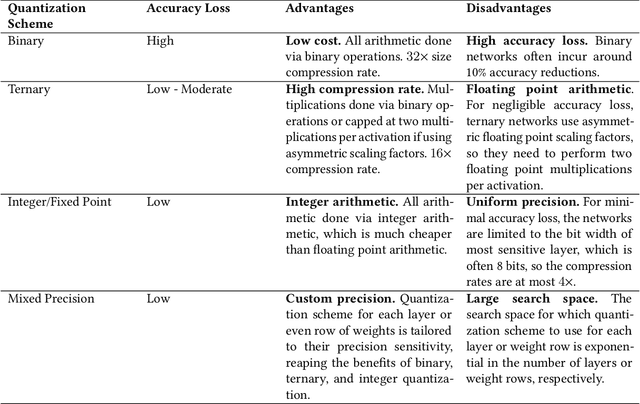
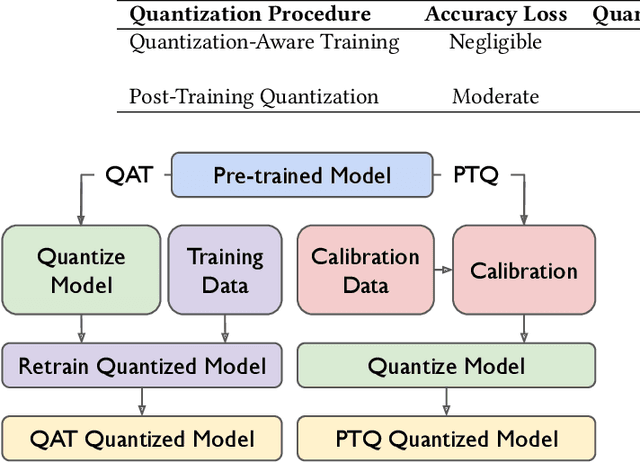
As neural networks have become more powerful, there has been a rising desire to deploy them in the real world; however, the power and accuracy of neural networks is largely due to their depth and complexity, making them difficult to deploy, especially in resource-constrained devices. Neural network quantization has recently arisen to meet this demand of reducing the size and complexity of neural networks by reducing the precision of a network. With smaller and simpler networks, it becomes possible to run neural networks within the constraints of their target hardware. This paper surveys the many neural network quantization techniques that have been developed in the last decade. Based on this survey and comparison of neural network quantization techniques, we propose future directions of research in the area.
Applications and Techniques for Fast Machine Learning in Science
Oct 25, 2021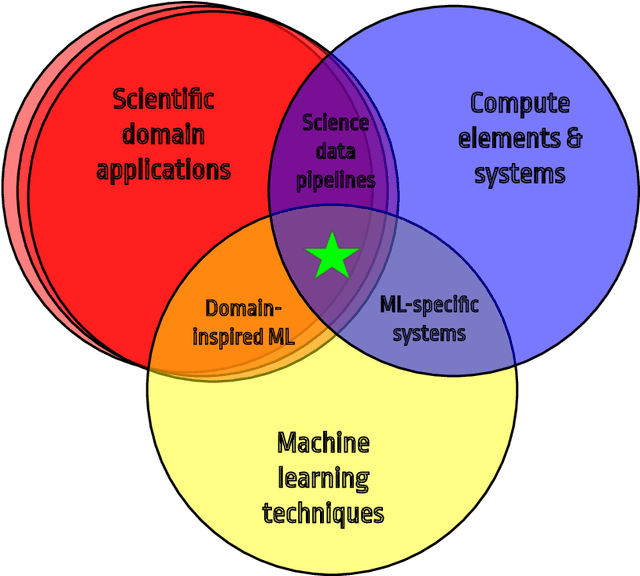
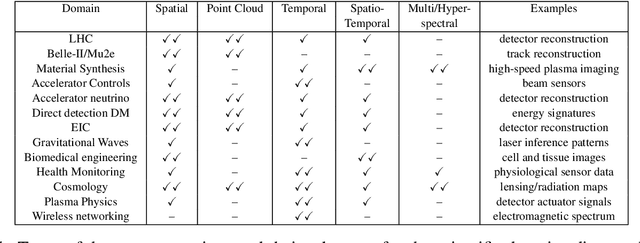
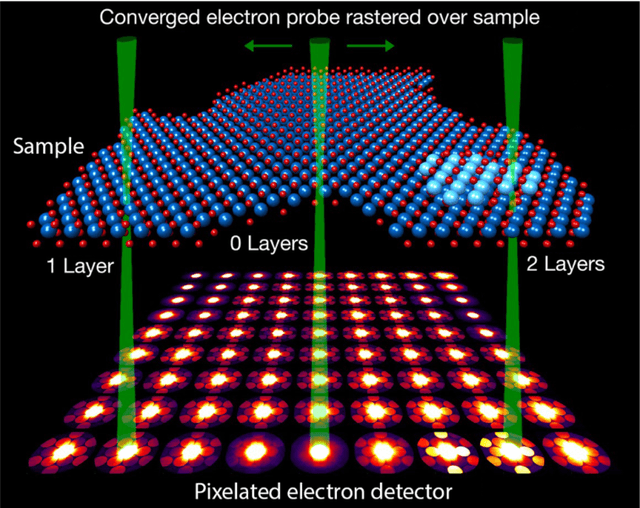
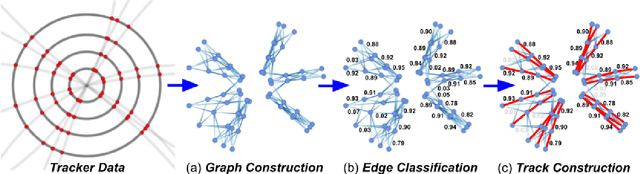
In this community review report, we discuss applications and techniques for fast machine learning (ML) in science -- the concept of integrating power ML methods into the real-time experimental data processing loop to accelerate scientific discovery. The material for the report builds on two workshops held by the Fast ML for Science community and covers three main areas: applications for fast ML across a number of scientific domains; techniques for training and implementing performant and resource-efficient ML algorithms; and computing architectures, platforms, and technologies for deploying these algorithms. We also present overlapping challenges across the multiple scientific domains where common solutions can be found. This community report is intended to give plenty of examples and inspiration for scientific discovery through integrated and accelerated ML solutions. This is followed by a high-level overview and organization of technical advances, including an abundance of pointers to source material, which can enable these breakthroughs.
Hardware-efficient Residual Networks for FPGAs
Feb 02, 2021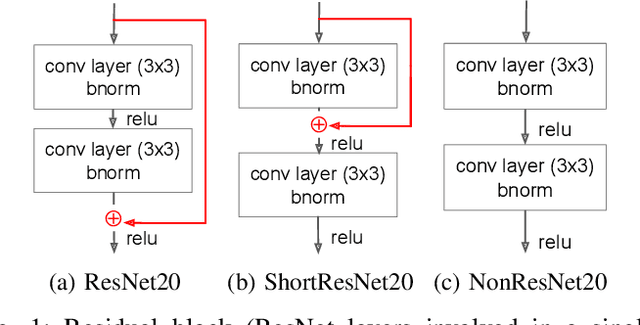
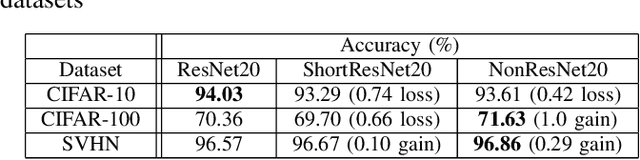
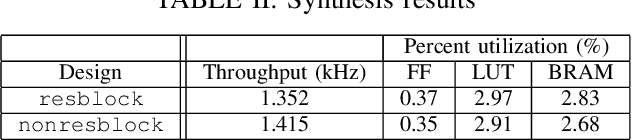
Residual networks (ResNets) employ skip connections in their networks -- reusing activations from previous layers -- to improve training convergence, but these skip connections create challenges for hardware implementations of ResNets. The hardware must either wait for skip connections to be processed before processing more incoming data or buffer them elsewhere. Without skip connections, ResNets would be more hardware-efficient. Thus, we present the teacher-student learning method to gradually prune away all of a ResNet's skip connections, constructing a network we call NonResNet. We show that when implemented for FPGAs, NonResNet decreases ResNet's BRAM utilization by 9% and LUT utilization by 3% and increases throughput by 5%.