 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexLLM: Composable HLS Library for Flexible Hybrid LLM Accelerator Design
Jan 22, 2026We present FlexLLM, a composable High-Level Synthesis (HLS) library for rapid development of domain-specific LLM accelerators. FlexLLM exposes key architectural degrees of freedom for stage-customized inference, enabling hybrid designs that tailor temporal reuse and spatial dataflow differently for prefill and decode, and provides a comprehensive quantization suite to support accurate low-bit deployment. Using FlexLLM, we build a complete inference system for the Llama-3.2 1B model in under two months with only 1K lines of code. The system includes: (1) a stage-customized accelerator with hardware-efficient quantization (12.68 WikiText-2 PPL) surpassing SpinQuant baseline, and (2) a Hierarchical Memory Transformer (HMT) plug-in for efficient long-context processing. On the AMD U280 FPGA at 16nm, the accelerator achieves 1.29$\times$ end-to-end speedup, 1.64$\times$ higher decode throughput, and 3.14$\times$ better energy efficiency than an NVIDIA A100 GPU (7nm) running BF16 inference; projected results on the V80 FPGA at 7nm reach 4.71$\times$, 6.55$\times$, and 4.13$\times$, respectively. In long-context scenarios, integrating the HMT plug-in reduces prefill latency by 23.23$\times$ and extends the context window by 64$\times$, delivering 1.10$\times$/4.86$\times$ lower end-to-end latency and 5.21$\times$/6.27$\times$ higher energy efficiency on the U280/V80 compared to the A100 baseline. FlexLLM thus bridges algorithmic innovation in LLM inference and high-performance accelerators with minimal manual effort.
FINN-GL: Generalized Mixed-Precision Extensions for FPGA-Accelerated LSTMs
Jun 25, 2025Recurrent neural networks (RNNs), particularly LSTMs, are effective for time-series tasks like sentiment analysis and short-term stock prediction. However, their computational complexity poses challenges for real-time deployment in resource constrained environments. While FPGAs offer a promising platform for energy-efficient AI acceleration, existing tools mainly target feed-forward networks, and LSTM acceleration typically requires full custom implementation. In this paper, we address this gap by leveraging the open-source and extensible FINN framework to enable the generalized deployment of LSTMs on FPGAs. Specifically, we leverage the Scan operator from the Open Neural Network Exchange (ONNX) specification to model the recurrent nature of LSTM computations, enabling support for mixed quantisation within them and functional verification of LSTM-based models. Furthermore, we introduce custom transformations within the FINN compiler to map the quantised ONNX computation graph to hardware blocks from the HLS kernel library of the FINN compiler and Vitis HLS. We validate the proposed tool-flow by training a quantised ConvLSTM model for a mid-price stock prediction task using the widely used dataset and generating a corresponding hardware IP of the model using our flow, targeting the XCZU7EV device. We show that the generated quantised ConvLSTM accelerator through our flow achieves a balance between performance (latency) and resource consumption, while matching (or bettering) inference accuracy of state-of-the-art models with reduced precision. We believe that the generalisable nature of the proposed flow will pave the way for resource-efficient RNN accelerator designs on FPGAs.
ACCL+: an FPGA-Based Collective Engine for Distributed Applications
Dec 18, 2023FPGAs are increasingly prevalent in cloud deployments, serving as Smart NICs or network-attached accelerators. Despite their potential, developing distributed FPGA-accelerated applications remains cumbersome due to the lack of appropriate infrastructure and communication abstractions. To facilitate the development of distributed applications with FPGAs, in this paper we propose ACCL+, an open-source versatile FPGA-based collective communication library. Portable across different platforms and supporting UDP, TCP, as well as RDMA, ACCL+ empowers FPGA applications to initiate direct FPGA-to-FPGA collective communication. Additionally, it can serve as a collective offload engine for CPU applications, freeing the CPU from networking tasks. It is user-extensible, allowing new collectives to be implemented and deployed without having to re-synthesize the FPGA circuit. We evaluated ACCL+ on an FPGA cluster with 100 Gb/s networking, comparing its performance against software MPI over RDMA. The results demonstrate ACCL+'s significant advantages for FPGA-based distributed applications and highly competitive performance for CPU applications. We showcase ACCL+'s dual role with two use cases: seamlessly integrating as a collective offload engine to distribute CPU-based vector-matrix multiplication, and serving as a crucial and efficient component in designing fully FPGA-based distributed deep-learning recommendation inference.
Post-Training Quantization with Low-precision Minifloats and Integers on FPGAs
Nov 21, 2023



Post-Training Quantization (PTQ) is a powerful technique for model compression, reducing the precision of neural networks without additional training overhead. Recent works have investigated adopting 8-bit floating-point quantization (FP8) in the context of PTQ for model inference. However, the exploration of floating-point formats smaller than 8 bits and their comparison with integer quantization remains relatively limited. In this work, we present minifloats, which are reduced-precision floating-point formats capable of further reducing the memory footprint, latency, and energy cost of a model while approaching full-precision model accuracy. Our work presents a novel PTQ design-space exploration, comparing minifloat and integer quantization schemes across a range of 3 to 8 bits for both weights and activations. We examine the applicability of various PTQ techniques to minifloats, including weight equalization, bias correction, SmoothQuant, gradient-based learned rounding, and the GPTQ method. Our experiments validate the effectiveness of low-precision minifloats when compared to their integer counterparts across a spectrum of accuracy-precision trade-offs on a set of reference deep learning vision workloads. Finally, we evaluate our results against an FPGA-based hardware cost model, showing that integer quantization often remains the Pareto-optimal option, given its relatively smaller hardware resource footprint.
Implementing Neural Network-Based Equalizers in a Coherent Optical Transmission System Using Field-Programmable Gate Arrays
Dec 09, 2022



In this work, we demonstrate the offline FPGA realization of both recurrent and feedforward neural network (NN)-based equalizers for nonlinearity compensation in coherent optical transmission systems. First, we present a realization pipeline showing the conversion of the models from Python libraries to the FPGA chip synthesis and implementation. Then, we review the main alternatives for the hardware implementation of nonlinear activation functions. The main results are divided into three parts: a performance comparison, an analysis of how activation functions are implemented, and a report on the complexity of the hardware. The performance in Q-factor is presented for the cases of bidirectional long-short-term memory coupled with convolutional NN (biLSTM + CNN) equalizer, CNN equalizer, and standard 1-StpS digital back-propagation (DBP) for the simulation and experiment propagation of a single channel dual-polarization (SC-DP) 16QAM at 34 GBd along 17x70km of LEAF. The biLSTM+CNN equalizer provides a similar result to DBP and a 1.7 dB Q-factor gain compared with the chromatic dispersion compensation baseline in the experimental dataset. After that, we assess the Q-factor and the impact of hardware utilization when approximating the activation functions of NN using Taylor series, piecewise linear, and look-up table (LUT) approximations. We also show how to mitigate the approximation errors with extra training and provide some insights into possible gradient problems in the LUT approximation. Finally, to evaluate the complexity of hardware implementation to achieve 400G throughput, fixed-point NN-based equalizers with approximated activation functions are developed and implemented in an FPGA.
LL-GNN: Low Latency Graph Neural Networks on FPGAs for Particle Detectors
Oct 11, 2022
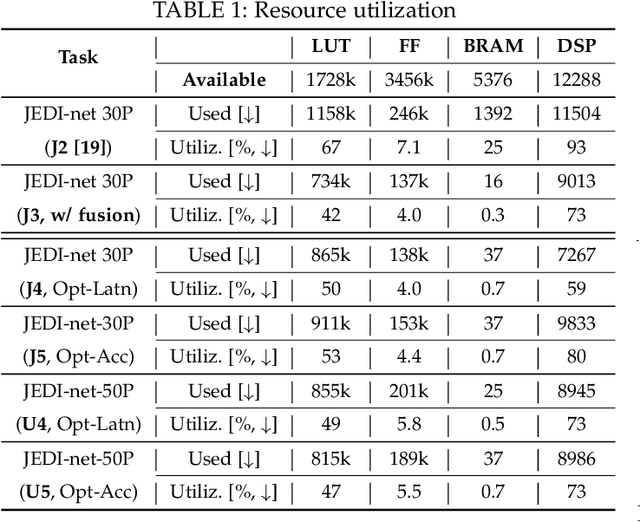
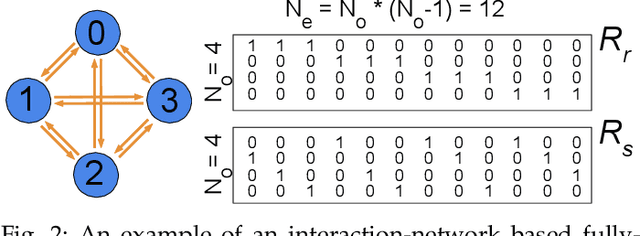
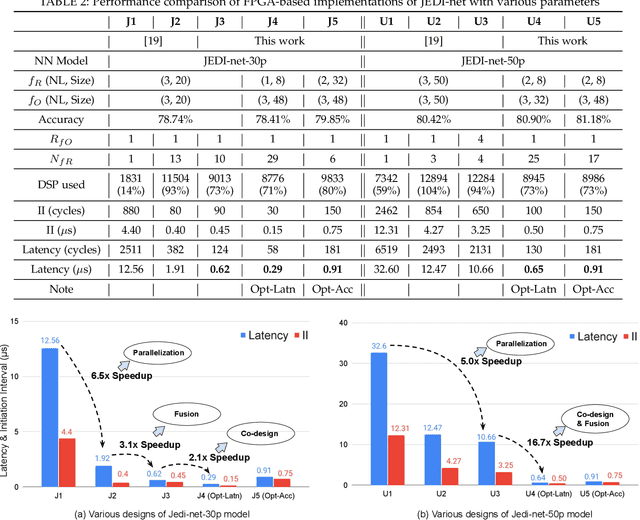
This work proposes a novel reconfigurable architecture for low latency Graph Neural Network (GNN) design specifically for particle detectors. Adopting FPGA-based GNNs for particle detectors is challenging since it requires sub-microsecond latency to deploy the networks for online event selection in the Level-1 triggers for the CERN Large Hadron Collider experiments. This paper proposes a custom code transformation with strength reduction for the matrix multiplication operations in the interaction-network based GNNs with fully connected graphs, which avoids the costly multiplication. It exploits sparsity patterns as well as binary adjacency matrices, and avoids irregular memory access, leading to a reduction in latency and improvement in hardware efficiency. In addition, we introduce an outer-product based matrix multiplication approach which is enhanced by the strength reduction for low latency design. Also, a fusion step is introduced to further reduce the design latency. Furthermore, an GNN-specific algorithm-hardware co-design approach is presented which not only finds a design with a much better latency but also finds a high accuracy design under a given latency constraint. Finally, a customizable template for this low latency GNN hardware architecture has been designed and open-sourced, which enables the generation of low-latency FPGA designs with efficient resource utilization using a high-level synthesis tool. Evaluation results show that our FPGA implementation is up to 24 times faster and consumes up to 45 times less power than a GPU implementation. Compared to our previous FPGA implementations, this work achieves 6.51 to 16.7 times lower latency. Moreover, the latency of our FPGA design is sufficiently low to enable deployment of GNNs in a sub-microsecond, real-time collider trigger system, enabling it to benefit from improved accuracy.
Towards FPGA Implementation of Neural Network-Based Nonlinearity Mitigation Equalizers in Coherent Optical Transmission Systems
Jun 24, 2022
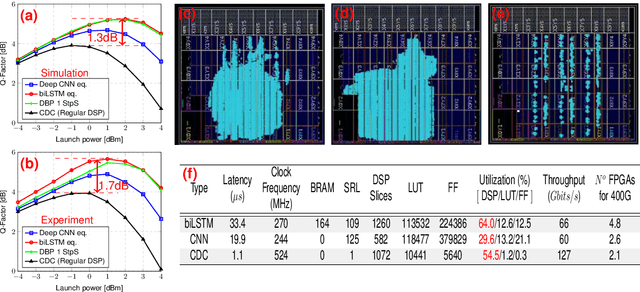
For the first time, recurrent and feedforward neural network-based equalizers for nonlinearity compensation are implemented in an FPGA, with a level of complexity comparable to that of a dispersion equalizer. We demonstrate that the NN-based equalizers can outperform a 1 step-per-span DBP.
Open-source FPGA-ML codesign for the MLPerf Tiny Benchmark
Jun 23, 2022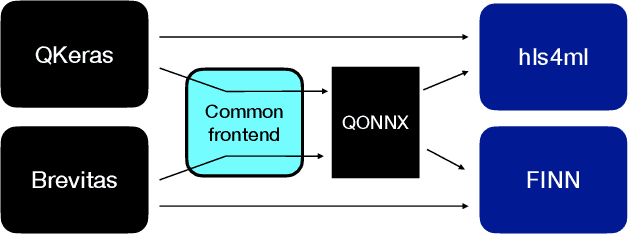
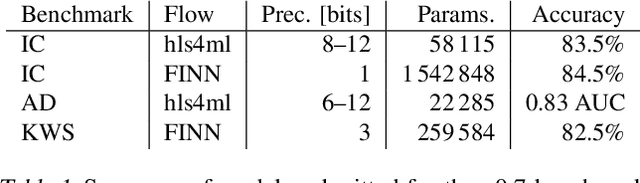
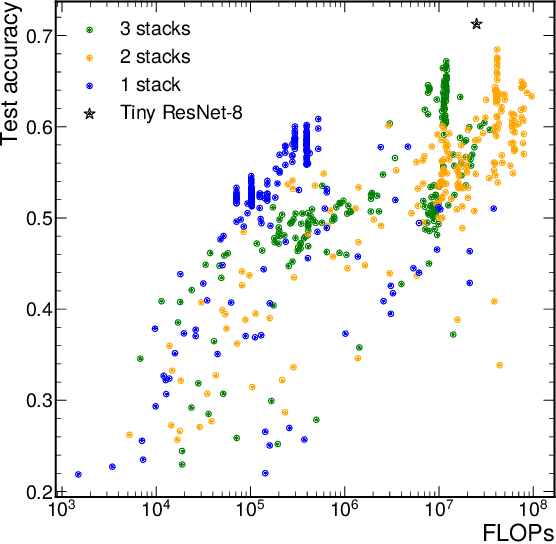
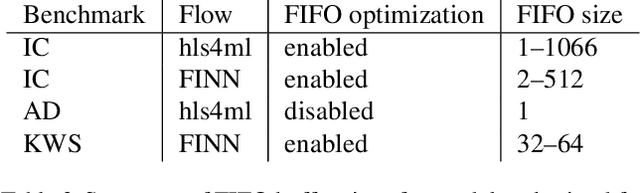
We present our development experience and recent results for the MLPerf Tiny Inference Benchmark on field-programmable gate array (FPGA) platforms. We use the open-source hls4ml and FINN workflows, which aim to democratize AI-hardware codesign of optimized neural networks on FPGAs. We present the design and implementation process for the keyword spotting, anomaly detection, and image classification benchmark tasks. The resulting hardware implementations are quantized, configurable, spatial dataflow architectures tailored for speed and efficiency and introduce new generic optimizations and common workflows developed as a part of this work. The full workflow is presented from quantization-aware training to FPGA implementation. The solutions are deployed on system-on-chip (Pynq-Z2) and pure FPGA (Arty A7-100T) platforms. The resulting submissions achieve latencies as low as 20 $\mu$s and energy consumption as low as 30 $\mu$J per inference. We demonstrate how emerging ML benchmarks on heterogeneous hardware platforms can catalyze collaboration and the development of new techniques and more accessible tools.
QONNX: Representing Arbitrary-Precision Quantized Neural Networks
Jun 17, 2022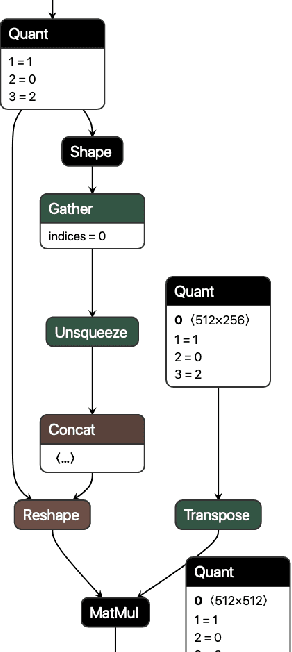
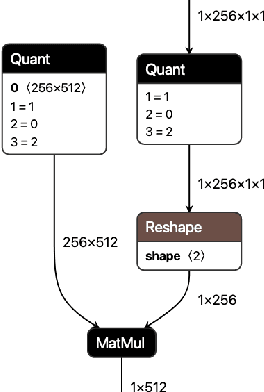
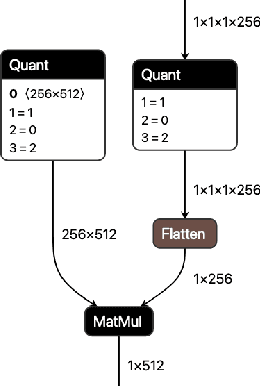
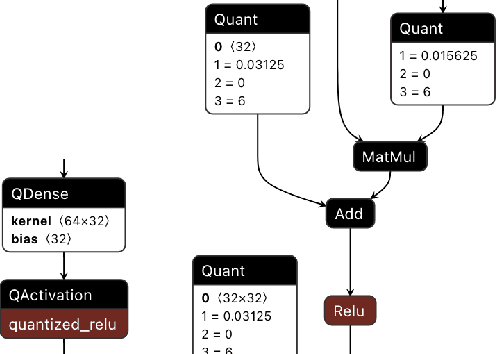
We present extensions to the Open Neural Network Exchange (ONNX) intermediate representation format to represent arbitrary-precision quantized neural networks. We first introduce support for low precision quantization in existing ONNX-based quantization formats by leveraging integer clipping, resulting in two new backward-compatible variants: the quantized operator format with clipping and quantize-clip-dequantize (QCDQ) format. We then introduce a novel higher-level ONNX format called quantized ONNX (QONNX) that introduces three new operators -- Quant, BipolarQuant, and Trunc -- in order to represent uniform quantization. By keeping the QONNX IR high-level and flexible, we enable targeting a wider variety of platforms. We also present utilities for working with QONNX, as well as examples of its usage in the FINN and hls4ml toolchains. Finally, we introduce the QONNX model zoo to share low-precision quantized neural networks.
EcoFlow: Efficient Convolutional Dataflows for Low-Power Neural Network Accelerators
Feb 04, 2022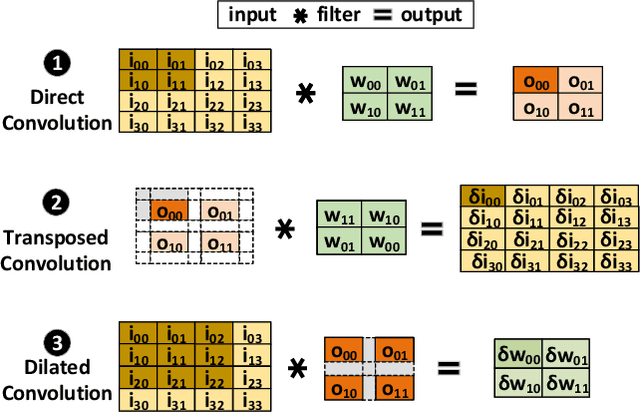

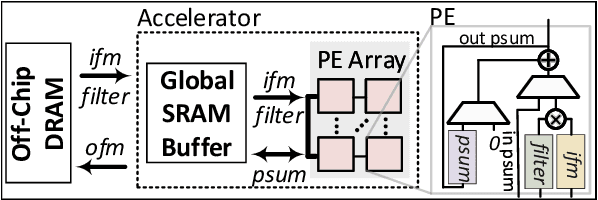
Dilated and transposed convolutions are widely used in modern convolutional neural networks (CNNs). These kernels are used extensively during CNN training and inference of applications such as image segmentation and high-resolution image generation. Although these kernels have grown in popularity, they stress current compute systems due to their high memory intensity, exascale compute demands, and large energy consumption. We find that commonly-used low-power CNN inference accelerators based on spatial architectures are not optimized for both of these convolutional kernels. Dilated and transposed convolutions introduce significant zero padding when mapped to the underlying spatial architecture, significantly degrading performance and energy efficiency. Existing approaches that address this issue require significant design changes to the otherwise simple, efficient, and well-adopted architectures used to compute direct convolutions. To address this challenge, we propose EcoFlow, a new set of dataflows and mapping algorithms for dilated and transposed convolutions. These algorithms are tailored to execute efficiently on existing low-cost, small-scale spatial architectures and requires minimal changes to the network-on-chip of existing accelerators. EcoFlow eliminates zero padding through careful dataflow orchestration and data mapping tailored to the spatial architecture. EcoFlow enables flexible and high-performance transpose and dilated convolutions on architectures that are otherwise optimized for CNN inference. We evaluate the efficiency of EcoFlow on CNN training workloads and Generative Adversarial Network (GAN) training workloads. Experiments in our new cycle-accurate simulator show that EcoFlow 1) reduces end-to-end CNN training time between 7-85%, and 2) improves end-to-end GAN training performance between 29-42%, compared to state-of-the-art CNN inference accelerators.