 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcoFlow: Efficient Convolutional Dataflows for Low-Power Neural Network Accelerators
Feb 04, 2022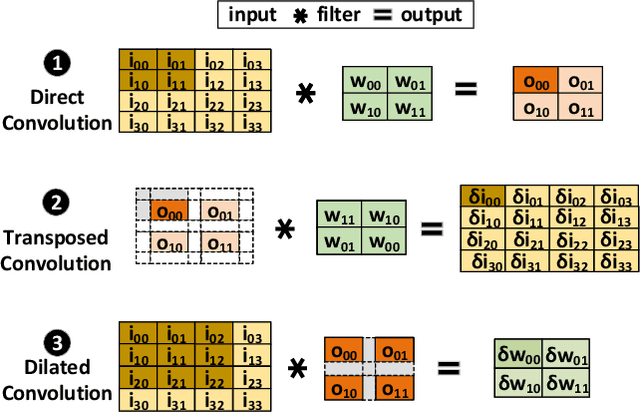

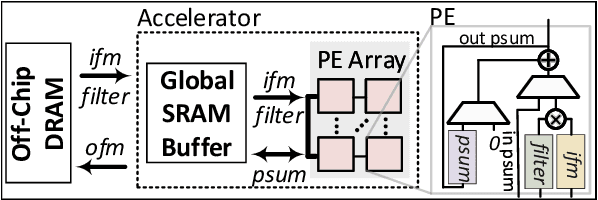
Dilated and transposed convolutions are widely used in modern convolutional neural networks (CNNs). These kernels are used extensively during CNN training and inference of applications such as image segmentation and high-resolution image generation. Although these kernels have grown in popularity, they stress current compute systems due to their high memory intensity, exascale compute demands, and large energy consumption. We find that commonly-used low-power CNN inference accelerators based on spatial architectures are not optimized for both of these convolutional kernels. Dilated and transposed convolutions introduce significant zero padding when mapped to the underlying spatial architecture, significantly degrading performance and energy efficiency. Existing approaches that address this issue require significant design changes to the otherwise simple, efficient, and well-adopted architectures used to compute direct convolutions. To address this challenge, we propose EcoFlow, a new set of dataflows and mapping algorithms for dilated and transposed convolutions. These algorithms are tailored to execute efficiently on existing low-cost, small-scale spatial architectures and requires minimal changes to the network-on-chip of existing accelerators. EcoFlow eliminates zero padding through careful dataflow orchestration and data mapping tailored to the spatial architecture. EcoFlow enables flexible and high-performance transpose and dilated convolutions on architectures that are otherwise optimized for CNN inference. We evaluate the efficiency of EcoFlow on CNN training workloads and Generative Adversarial Network (GAN) training workloads. Experiments in our new cycle-accurate simulator show that EcoFlow 1) reduces end-to-end CNN training time between 7-85%, and 2) improves end-to-end GAN training performance between 29-42%, compared to state-of-the-art CNN inference accelerators.
FAT: Training Neural Networks for Reliable Inference Under Hardware Faults
Nov 11, 2020
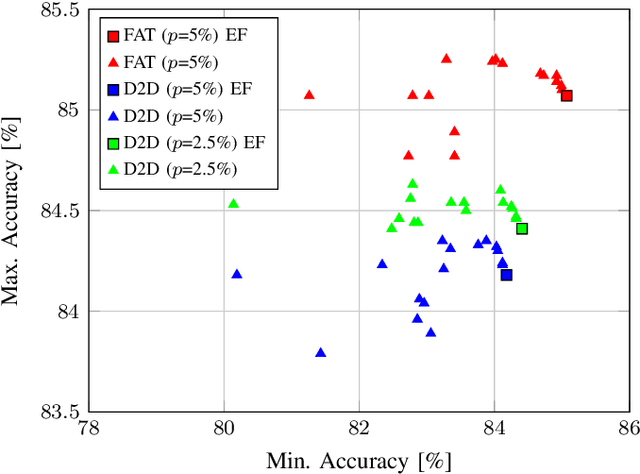
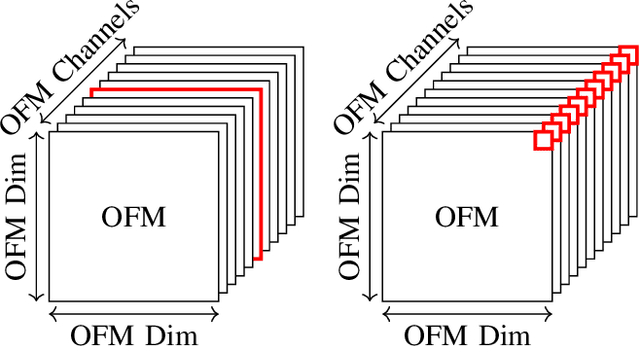
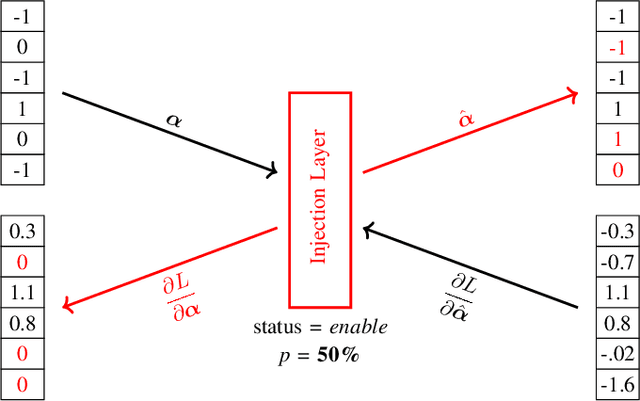
Deep neural networks (DNNs) are state-of-the-art algorithms for multiple applications, spanning from image classification to speech recognition. While providing excellent accuracy, they often have enormous compute and memory requirements. As a result of this, quantized neural networks (QNNs) are increasingly being adopted and deployed especially on embedded devices, thanks to their high accuracy, but also since they have significantly lower compute and memory requirements compared to their floating point equivalents. QNN deployment is also being evaluated for safety-critical applications, such as automotive, avionics, medical or industrial. These systems require functional safety, guaranteeing failure-free behaviour even in the presence of hardware faults. In general fault tolerance can be achieved by adding redundancy to the system, which further exacerbates the overall computational demands and makes it difficult to meet the power and performance requirements. In order to decrease the hardware cost for achieving functional safety, it is vital to explore domain-specific solutions which can exploit the inherent features of DNNs. In this work we present a novel methodology called fault-aware training (FAT), which includes error modeling during neural network (NN) training, to make QNNs resilient to specific fault models on the device. Our experiments show that by injecting faults in the convolutional layers during training, highly accurate convolutional neural networks (CNNs) can be trained which exhibits much better error tolerance compared to the original. Furthermore, we show that redundant systems which are built from QNNs trained with FAT achieve higher worse-case accuracy at lower hardware cost. This has been validated for numerous classification tasks including CIFAR10, GTSRB, SVHN and ImageNet.
Efficient Error-Tolerant Quantized Neural Network Accelerators
Dec 16, 2019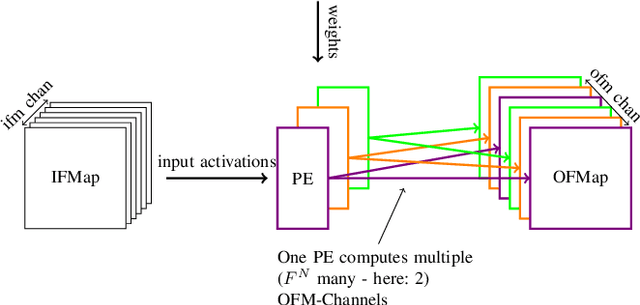
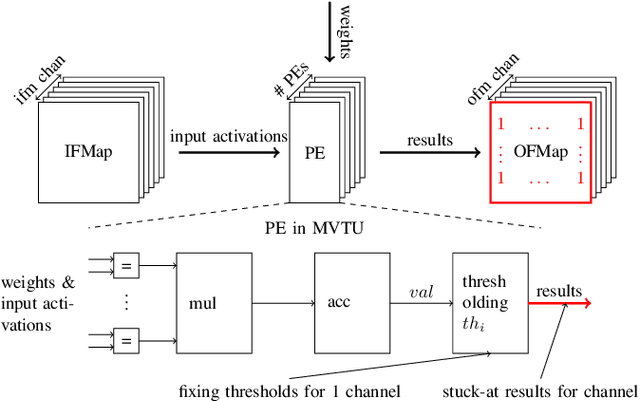
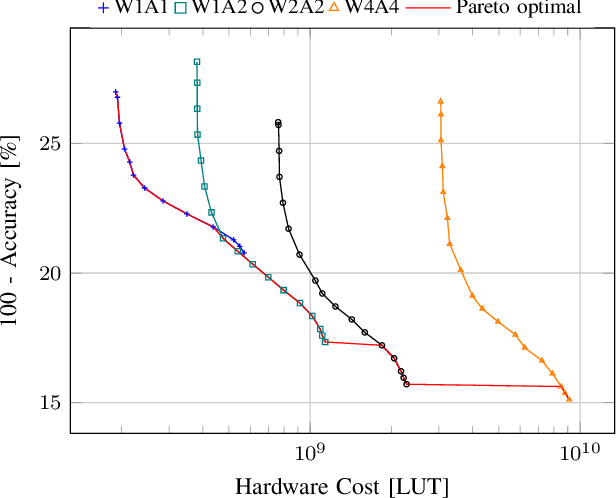
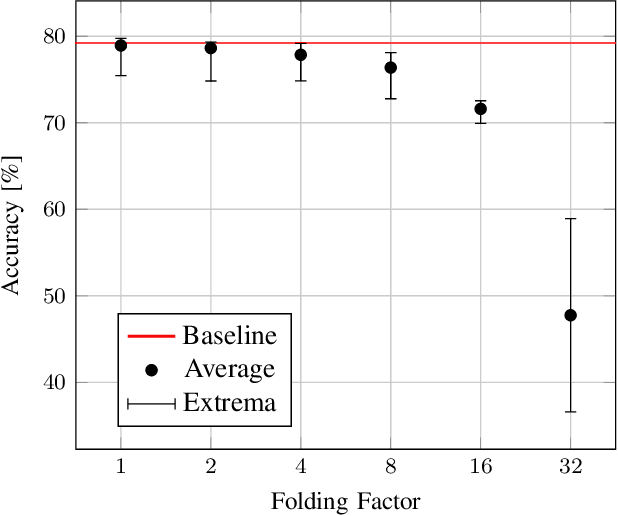
Neural Networks are currently one of the most widely deployed machine learning algorithms. In particular, Convolutional Neural Networks (CNNs), are gaining popularity and are evaluated for deployment in safety critical applications such as self driving vehicles. Modern CNNs feature enormous memory bandwidth and high computational needs, challenging existing hardware platforms to meet throughput, latency and power requirements. Functional safety and error tolerance need to be considered as additional requirement in safety critical systems. In general, fault tolerant operation can be achieved by adding redundancy to the system, which is further exacerbating the computational demands. Furthermore, the question arises whether pruning and quantization methods for performance scaling turn out to be counterproductive with regards to fail safety requirements. In this work we present a methodology to evaluate the impact of permanent faults affecting Quantized Neural Networks (QNNs) and how to effectively decrease their effects in hardware accelerators. We use FPGA-based hardware accelerated error injection, in order to enable the fast evaluation. A detailed analysis is presented showing that QNNs containing convolutional layers are by far not as robust to faults as commonly believed and can lead to accuracy drops of up to 10%. To circumvent that, we propose two different methods to increase their robustness: 1) selective channel replication which adds significantly less redundancy than used by the common triple modular redundancy and 2) a fault-aware scheduling of processing elements for folded implementations
* 6 pages, 5 figures
Synetgy: Algorithm-hardware Co-design for ConvNet Accelerators on Embedded FPGAs
Nov 21, 2018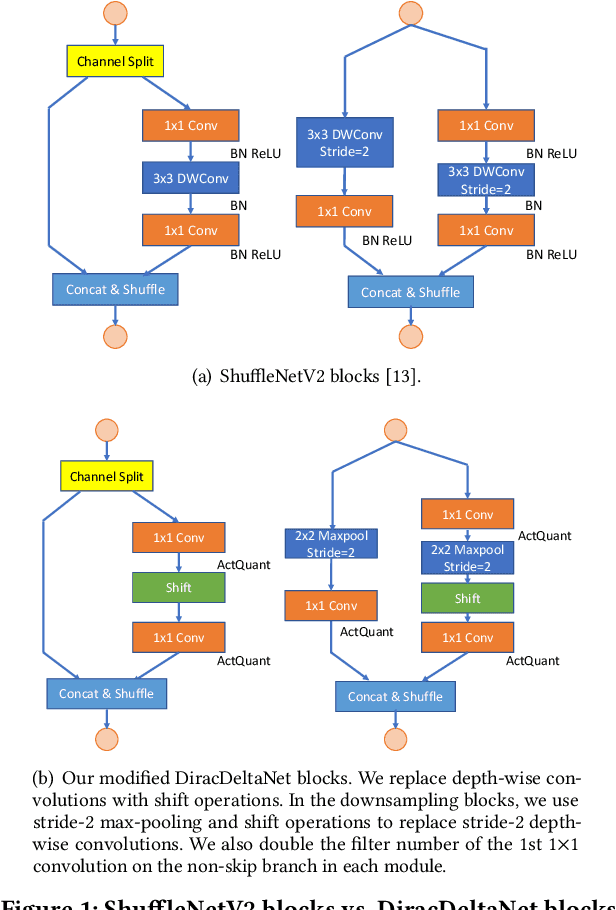
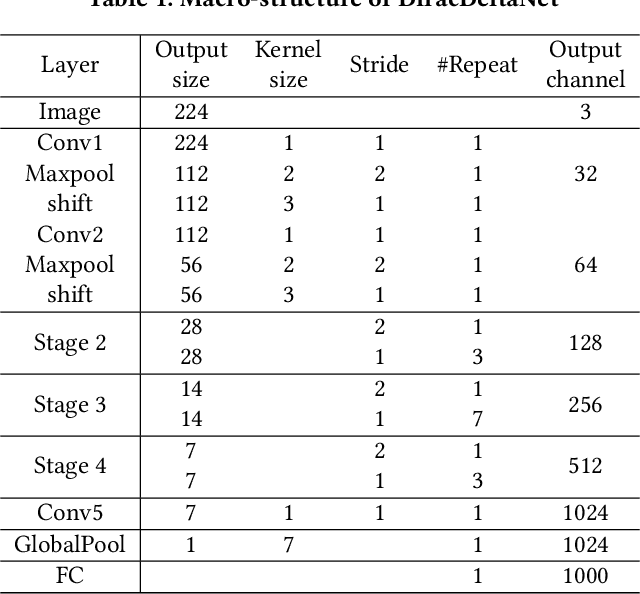
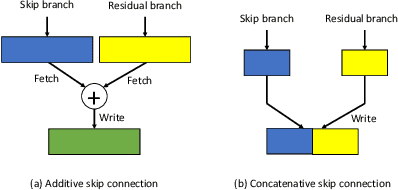
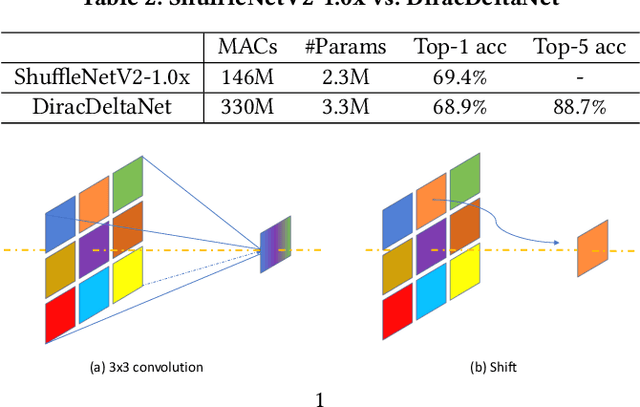
Using FPGAs to accelerate ConvNets has attracted significant attention in recent years. However, FPGA accelerator design has not leveraged the latest progress of ConvNets. As a result, the key application characteristics such as frames-per-second (FPS) are ignored in favor of simply counting GOPs, and results on accuracy, which is critical to application success, are often not even reported. In this work, we adopt an algorithm-hardware co-design approach to develop a ConvNet accelerator called Synetgy and a novel ConvNet model called DiracNet. Both the accelerator and ConvNet are tailored to FPGA requirements. DiractNet, as the name suggests, is a ConvNet with only 1x1 convolutions while spatial convolutions are replaced by more efficient shift operations. DiracNet achieves competitive accuracy on ImageNet (89.0% top-5), but with 48x fewer parameters and 65x fewer OPs than VGG16. We further quantize DiracNet's weights to 1-bit and activations to 4-bits, with less than 1% accuracy loss. These quantizations exploit well the nature of FPGA hardware. In short, DiracNet's small model size, low computational OP count, ultra-low precision and simplified operators allow us to co-design a highly customized computing unit for an FPGA. We implement the computing units for DiracNet on an Ultra96 SoC system through high-level synthesis. The implementation only took 2 people 1 month to complete. Our accelerator's final top-5 accuracy of 88.3% on ImageNet, is higher than all the previously reported embedded FPGA accelerators. In addition, the accelerator reaches an inference speed of 72.8 FPS on the ImageNet classification task, surpassing prior works with similar accuracy by at least 12.8x.
Scaling Binarized Neural Networks on Reconfigurable Logic
Jan 27, 2017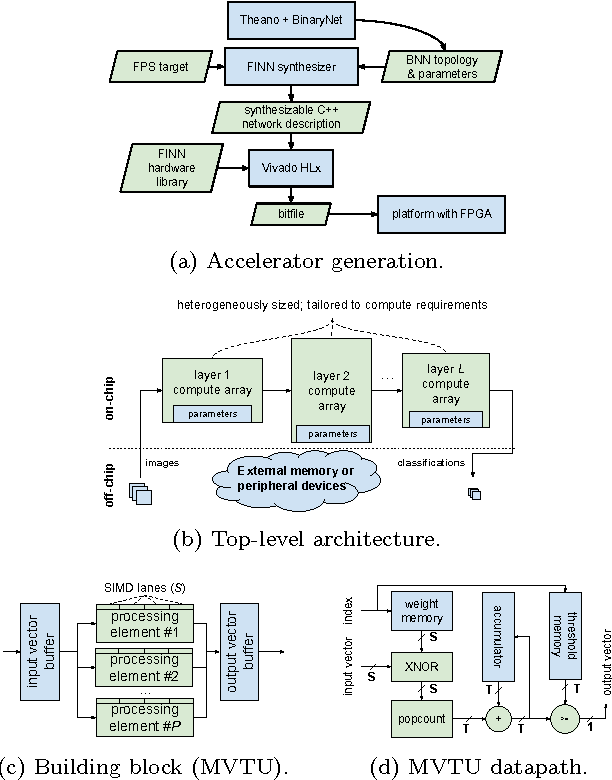

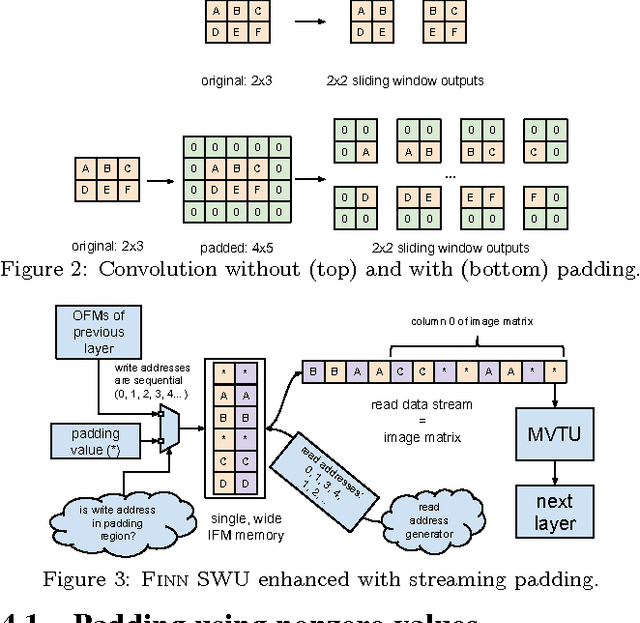
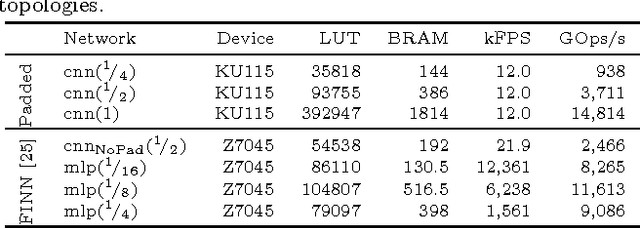
Binarized neural networks (BNNs) are gaining interest in the deep learning community due to their significantly lower computational and memory cost. They are particularly well suited to reconfigurable logic devices, which contain an abundance of fine-grained compute resources and can result in smaller, lower power implementations, or conversely in higher classification rates. Towards this end, the Finn framework was recently proposed for building fast and flexible field programmable gate array (FPGA) accelerators for BNNs. Finn utilized a novel set of optimizations that enable efficient mapping of BNNs to hardware and implemented fully connected, non-padded convolutional and pooling layers, with per-layer compute resources being tailored to user-provided throughput requirements. However, FINN was not evaluated on larger topologies due to the size of the chosen FPGA, and exhibited decreased accuracy due to lack of padding. In this paper, we improve upon Finn to show how padding can be employed on BNNs while still maintaining a 1-bit datapath and high accuracy. Based on this technique, we demonstrate numerous experiments to illustrate flexibility and scalability of the approach. In particular, we show that a large BNN requiring 1.2 billion operations per frame running on an ADM-PCIE-8K5 platform can classify images at 12 kFPS with 671 us latency while drawing less than 41 W board power and classifying CIFAR-10 images at 88.7% accuracy. Our implementation of this network achieves 14.8 trillion operations per second. We believe this is the fastest classification rate reported to date on this benchmark at this level of accuracy.
FINN: A Framework for Fast, Scalable Binarized Neural Network Inference
Dec 01, 2016

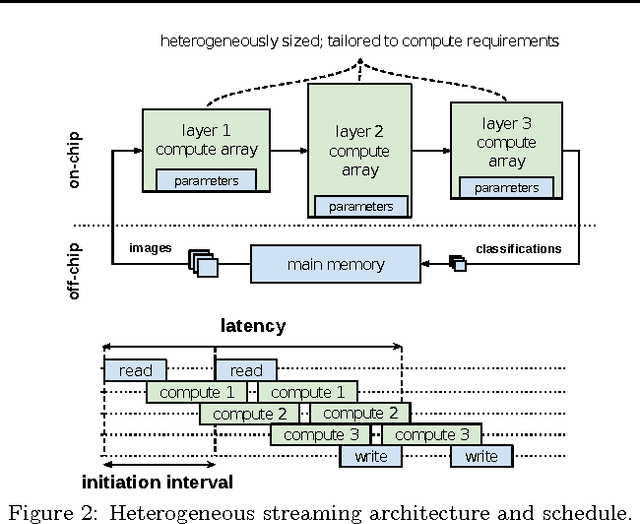
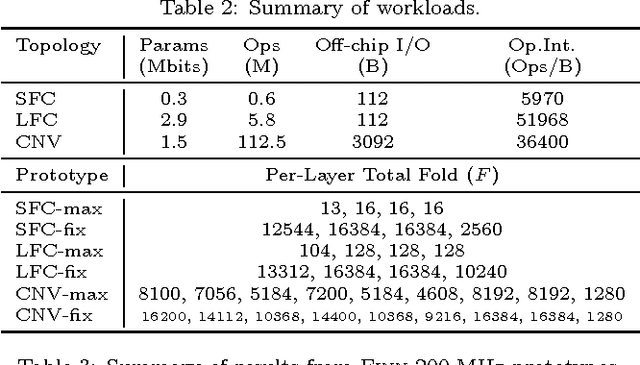
Research has shown that convolutional neural networks contain significant redundancy, and high classification accuracy can be obtained even when weights and activations are reduced from floating point to binary values. In this paper, we present FINN, a framework for building fast and flexible FPGA accelerators using a flexible heterogeneous streaming architecture. By utilizing a novel set of optimizations that enable efficient mapping of binarized neural networks to hardware, we implement fully connected, convolutional and pooling layers, with per-layer compute resources being tailored to user-provided throughput requirements. On a ZC706 embedded FPGA platform drawing less than 25 W total system power, we demonstrate up to 12.3 million image classifications per second with 0.31 {\mu}s latency on the MNIST dataset with 95.8% accuracy, and 21906 image classifications per second with 283 {\mu}s latency on the CIFAR-10 and SVHN datasets with respectively 80.1% and 94.9% accuracy. To the best of our knowledge, ours are the fastest classification rates reported to date on these benchmarks.