 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAthena: Synergizing Data Prefetching and Off-Chip Prediction via Online Reinforcement Learning
Jan 24, 2026Prefetching and off-chip prediction are two techniques proposed to hide long memory access latencies in high-performance processors. In this work, we demonstrate that: (1) prefetching and off-chip prediction often provide complementary performance benefits, yet (2) naively combining them often fails to realize their full performance potential, and (3) existing prefetcher control policies leave significant room for performance improvement behind. Our goal is to design a holistic framework that can autonomously learn to coordinate an off-chip predictor with multiple prefetchers employed at various cache levels. To this end, we propose a new technique called Athena, which models the coordination between prefetchers and off-chip predictor (OCP) as a reinforcement learning (RL) problem. Athena acts as the RL agent that observes multiple system-level features (e.g., prefetcher/OCP accuracy, bandwidth usage) over an epoch of program execution, and uses them as state information to select a coordination action (i.e., enabling the prefetcher and/or OCP, and adjusting prefetcher aggressiveness). At the end of every epoch, Athena receives a numerical reward that measures the change in multiple system-level metrics (e.g., number of cycles taken to execute an epoch). Athena uses this reward to autonomously and continuously learn a policy to coordinate prefetchers with OCP. Our extensive evaluation using a diverse set of memory-intensive workloads shows that Athena consistently outperforms prior state-of-the-art coordination policies across a wide range of system configurations with various combinations of underlying prefetchers, OCPs, and main memory bandwidths, while incurring only modest storage overhead. Athena is freely available at https://github.com/CMU-SAFARI/Athena.
EcoFlow: Efficient Convolutional Dataflows for Low-Power Neural Network Accelerators
Feb 04, 2022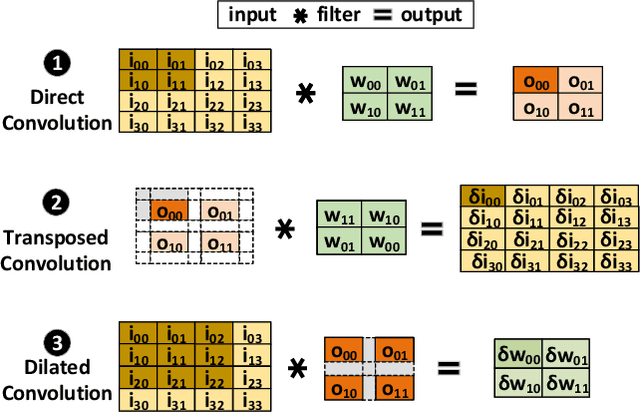

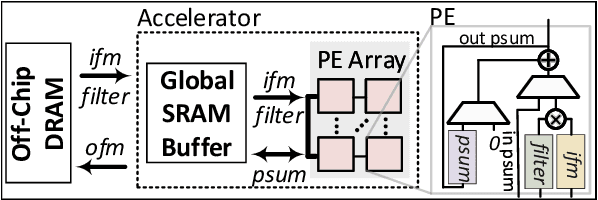
Dilated and transposed convolutions are widely used in modern convolutional neural networks (CNNs). These kernels are used extensively during CNN training and inference of applications such as image segmentation and high-resolution image generation. Although these kernels have grown in popularity, they stress current compute systems due to their high memory intensity, exascale compute demands, and large energy consumption. We find that commonly-used low-power CNN inference accelerators based on spatial architectures are not optimized for both of these convolutional kernels. Dilated and transposed convolutions introduce significant zero padding when mapped to the underlying spatial architecture, significantly degrading performance and energy efficiency. Existing approaches that address this issue require significant design changes to the otherwise simple, efficient, and well-adopted architectures used to compute direct convolutions. To address this challenge, we propose EcoFlow, a new set of dataflows and mapping algorithms for dilated and transposed convolutions. These algorithms are tailored to execute efficiently on existing low-cost, small-scale spatial architectures and requires minimal changes to the network-on-chip of existing accelerators. EcoFlow eliminates zero padding through careful dataflow orchestration and data mapping tailored to the spatial architecture. EcoFlow enables flexible and high-performance transpose and dilated convolutions on architectures that are otherwise optimized for CNN inference. We evaluate the efficiency of EcoFlow on CNN training workloads and Generative Adversarial Network (GAN) training workloads. Experiments in our new cycle-accurate simulator show that EcoFlow 1) reduces end-to-end CNN training time between 7-85%, and 2) improves end-to-end GAN training performance between 29-42%, compared to state-of-the-art CNN inference accelerators.
Pythia: A Customizable Hardware Prefetching Framework Using Online Reinforcement Learning
Oct 19, 2021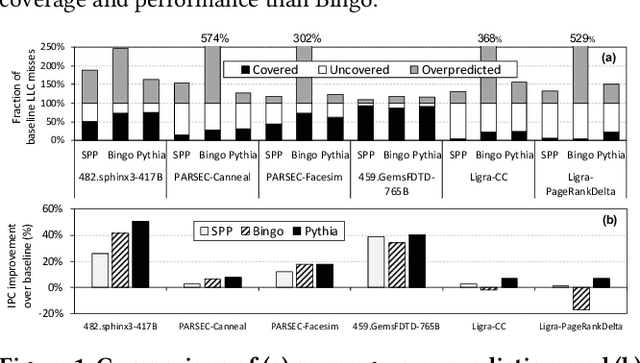
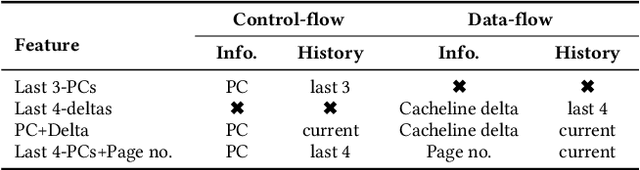

Past research has proposed numerous hardware prefetching techniques, most of which rely on exploiting one specific type of program context information (e.g., program counter, cacheline address) to predict future memory accesses. These techniques either completely neglect a prefetcher's undesirable effects (e.g., memory bandwidth usage) on the overall system, or incorporate system-level feedback as an afterthought to a system-unaware prefetch algorithm. We show that prior prefetchers often lose their performance benefit over a wide range of workloads and system configurations due to their inherent inability to take multiple different types of program context and system-level feedback information into account while prefetching. In this paper, we make a case for designing a holistic prefetch algorithm that learns to prefetch using multiple different types of program context and system-level feedback information inherent to its design. To this end, we propose Pythia, which formulates the prefetcher as a reinforcement learning agent. For every demand request, Pythia observes multiple different types of program context information to make a prefetch decision. For every prefetch decision, Pythia receives a numerical reward that evaluates prefetch quality under the current memory bandwidth usage. Pythia uses this reward to reinforce the correlation between program context information and prefetch decision to generate highly accurate, timely, and system-aware prefetch requests in the future. Our extensive evaluations using simulation and hardware synthesis show that Pythia outperforms multiple state-of-the-art prefetchers over a wide range of workloads and system configurations, while incurring only 1.03% area overhead over a desktop-class processor and no software changes in workloads. The source code of Pythia can be freely downloaded from https://github.com/CMU-SAFARI/Pythia.
EDEN: Enabling Energy-Efficient, High-Performance Deep Neural Network Inference Using Approximate DRAM
Oct 12, 2019
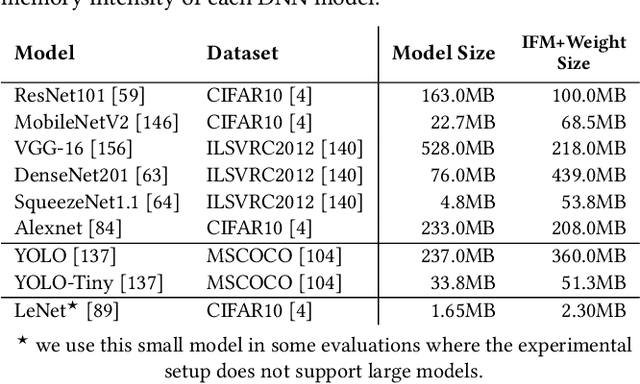
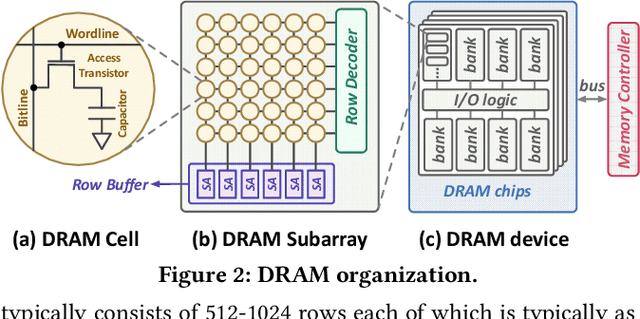
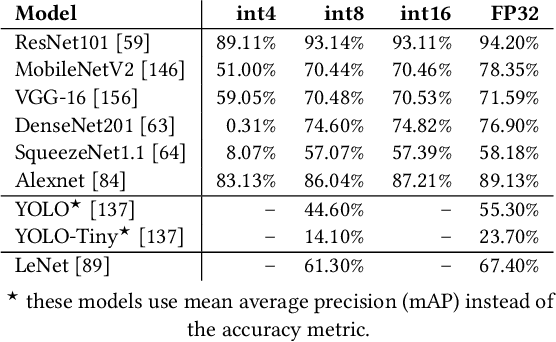
The effectiveness of deep neural networks (DNN) in vision, speech, and language processing has prompted a tremendous demand for energy-efficient high-performance DNN inference systems. Due to the increasing memory intensity of most DNN workloads, main memory can dominate the system's energy consumption and stall time. One effective way to reduce the energy consumption and increase the performance of DNN inference systems is by using approximate memory, which operates with reduced supply voltage and reduced access latency parameters that violate standard specifications. Using approximate memory reduces reliability, leading to higher bit error rates. Fortunately, neural networks have an intrinsic capacity to tolerate increased bit errors. This can enable energy-efficient and high-performance neural network inference using approximate DRAM devices. Based on this observation, we propose EDEN, a general framework that reduces DNN energy consumption and DNN evaluation latency by using approximate DRAM devices, while strictly meeting a user-specified target DNN accuracy. EDEN relies on two key ideas: 1) retraining the DNN for a target approximate DRAM device to increase the DNN's error tolerance, and 2) efficient mapping of the error tolerance of each individual DNN data type to a corresponding approximate DRAM partition in a way that meets the user-specified DNN accuracy requirements. We evaluate EDEN on multi-core CPUs, GPUs, and DNN accelerators with error models obtained from real approximate DRAM devices. For a target accuracy within 1% of the original DNN, our results show that EDEN enables 1) an average DRAM energy reduction of 21%, 37%, 31%, and 32% in CPU, GPU, and two DNN accelerator architectures, respectively, across a variety of DNNs, and 2) an average (maximum) speedup of 8% (17%) and 2.7% (5.5%) in CPU and GPU architectures, respectively, when evaluating latency-bound DNNs.