 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmonia: A Multi-Agent Reinforcement Learning Approach to Data Placement and Migration in Hybrid Storage Systems
Mar 26, 2025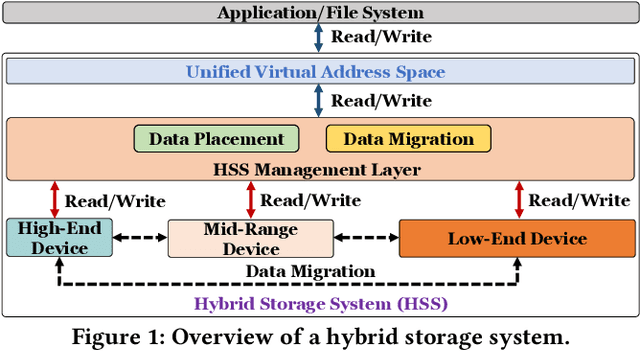
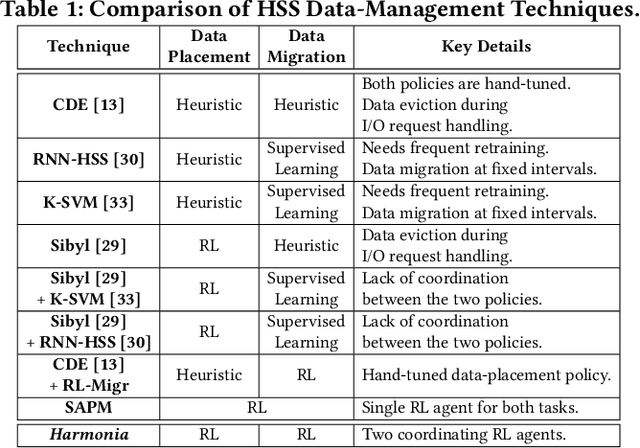
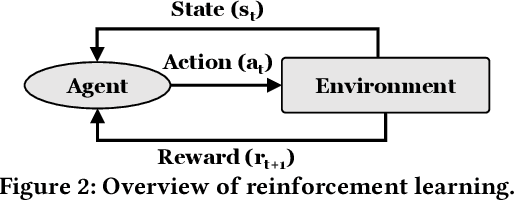

Hybrid storage systems (HSS) combine multiple storage devices with diverse characteristics to achieve high performance and capacity at low cost. The performance of an HSS highly depends on the effectiveness of two key policies: (1) the data-placement policy, which determines the best-fit storage device for incoming data, and (2) the data-migration policy, which rearranges stored data across the devices to sustain high HSS performance. Prior works focus on improving only data placement or only data migration in HSS, which leads to sub-optimal HSS performance. Unfortunately, no prior work tries to optimize both policies together. Our goal is to design a holistic data-management technique for HSS that optimizes both data-placement and data-migration policies to fully exploit the potential of an HSS. We propose Harmonia, a multi-agent reinforcement learning (RL)-based data-management technique that employs two light-weight autonomous RL agents, a data-placement agent and a data-migration agent, which adapt their policies for the current workload and HSS configuration, and coordinate with each other to improve overall HSS performance. We evaluate Harmonia on a real HSS with up to four heterogeneous storage devices with diverse characteristics. Our evaluation using 17 data-intensive workloads on performance-optimized (cost-optimized) HSS with two storage devices shows that, on average, Harmonia (1) outperforms the best-performing prior approach by 49.5% (31.7%), (2) bridges the performance gap between the best-performing prior work and Oracle by 64.2% (64.3%). On an HSS with three (four) devices, Harmonia outperforms the best-performing prior work by 37.0% (42.0%). Harmonia's performance benefits come with low latency (240ns for inference) and storage overheads (206 KiB for both RL agents together). We plan to open-source Harmonia's implementation to aid future research on HSS.
ApHMM: Accelerating Profile Hidden Markov Models for Fast and Energy-Efficient Genome Analysis
Jul 20, 2022
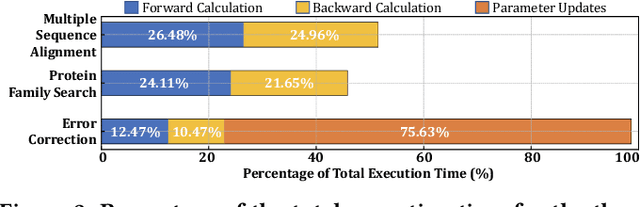
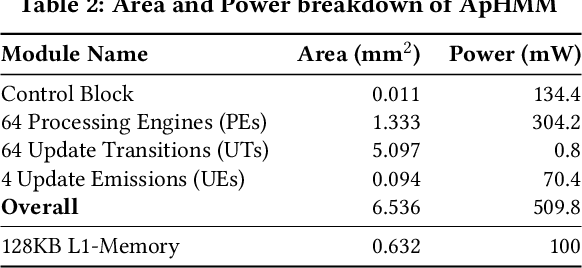
Profile hidden Markov models (pHMMs) are widely used in many bioinformatics applications to accurately identify similarities between biological sequences (e.g., DNA or protein sequences). PHMMs use a commonly-adopted and highly-accurate method, called the Baum-Welch algorithm, to calculate these similarities. However, the Baum-Welch algorithm is computationally expensive, and existing works provide either software- or hardware-only solutions for a fixed pHMM design. When we analyze the state-of-the-art works, we find that there is a pressing need for a flexible, high-performant, and energy-efficient hardware-software co-design to efficiently and effectively solve all the major inefficiencies in the Baum-Welch algorithm for pHMMs. We propose ApHMM, the first flexible acceleration framework that can significantly reduce computational and energy overheads of the Baum-Welch algorithm for pHMMs. ApHMM leverages hardware-software co-design to solve the major inefficiencies in the Baum-Welch algorithm by 1) designing a flexible hardware to support different pHMMs designs, 2) exploiting the predictable data dependency pattern in an on-chip memory with memoization techniques, 3) quickly eliminating negligible computations with a hardware-based filter, and 4) minimizing the redundant computations. We implement our 1) hardware-software optimizations on a specialized hardware and 2) software optimizations for GPUs to provide the first flexible Baum-Welch accelerator for pHMMs. ApHMM provides significant speedups of 15.55x-260.03x, 1.83x-5.34x, and 27.97x compared to CPU, GPU, and FPGA implementations of the Baum-Welch algorithm, respectively. ApHMM outperforms the state-of-the-art CPU implementations of three important bioinformatics applications, 1) error correction, 2) protein family search, and 3) multiple sequence alignment, by 1.29x-59.94x, 1.03x-1.75x, and 1.03x-1.95x, respectively.
Pythia: A Customizable Hardware Prefetching Framework Using Online Reinforcement Learning
Oct 19, 2021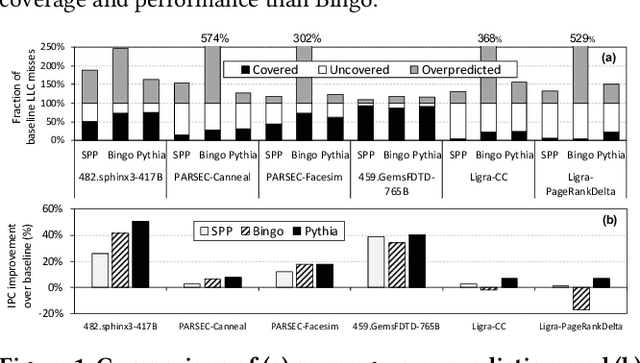
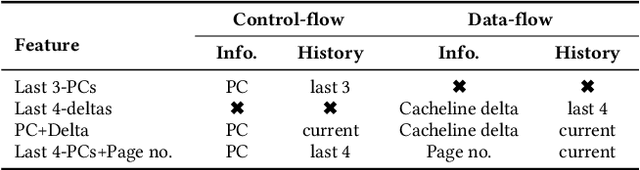
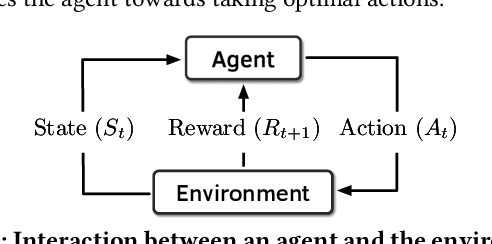

Past research has proposed numerous hardware prefetching techniques, most of which rely on exploiting one specific type of program context information (e.g., program counter, cacheline address) to predict future memory accesses. These techniques either completely neglect a prefetcher's undesirable effects (e.g., memory bandwidth usage) on the overall system, or incorporate system-level feedback as an afterthought to a system-unaware prefetch algorithm. We show that prior prefetchers often lose their performance benefit over a wide range of workloads and system configurations due to their inherent inability to take multiple different types of program context and system-level feedback information into account while prefetching. In this paper, we make a case for designing a holistic prefetch algorithm that learns to prefetch using multiple different types of program context and system-level feedback information inherent to its design. To this end, we propose Pythia, which formulates the prefetcher as a reinforcement learning agent. For every demand request, Pythia observes multiple different types of program context information to make a prefetch decision. For every prefetch decision, Pythia receives a numerical reward that evaluates prefetch quality under the current memory bandwidth usage. Pythia uses this reward to reinforce the correlation between program context information and prefetch decision to generate highly accurate, timely, and system-aware prefetch requests in the future. Our extensive evaluations using simulation and hardware synthesis show that Pythia outperforms multiple state-of-the-art prefetchers over a wide range of workloads and system configurations, while incurring only 1.03% area overhead over a desktop-class processor and no software changes in workloads. The source code of Pythia can be freely downloaded from https://github.com/CMU-SAFARI/Pythia.
EDEN: Enabling Energy-Efficient, High-Performance Deep Neural Network Inference Using Approximate DRAM
Oct 12, 2019
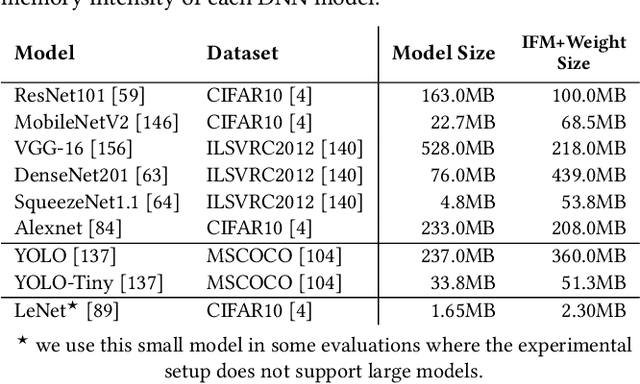
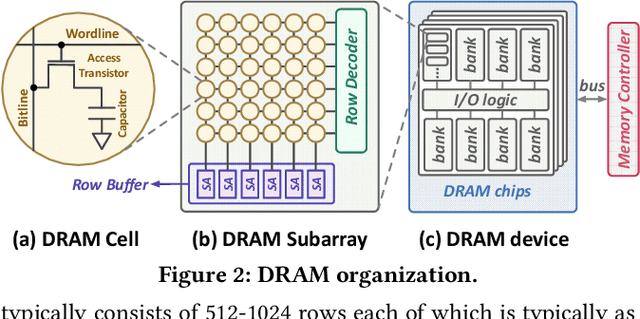
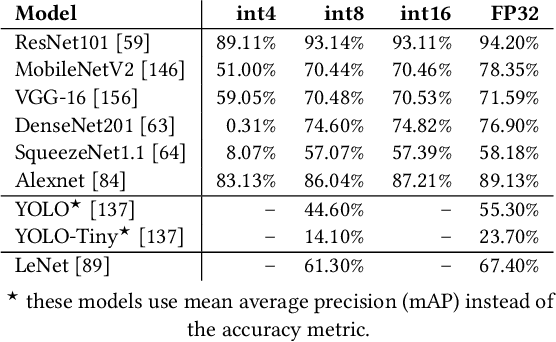
The effectiveness of deep neural networks (DNN) in vision, speech, and language processing has prompted a tremendous demand for energy-efficient high-performance DNN inference systems. Due to the increasing memory intensity of most DNN workloads, main memory can dominate the system's energy consumption and stall time. One effective way to reduce the energy consumption and increase the performance of DNN inference systems is by using approximate memory, which operates with reduced supply voltage and reduced access latency parameters that violate standard specifications. Using approximate memory reduces reliability, leading to higher bit error rates. Fortunately, neural networks have an intrinsic capacity to tolerate increased bit errors. This can enable energy-efficient and high-performance neural network inference using approximate DRAM devices. Based on this observation, we propose EDEN, a general framework that reduces DNN energy consumption and DNN evaluation latency by using approximate DRAM devices, while strictly meeting a user-specified target DNN accuracy. EDEN relies on two key ideas: 1) retraining the DNN for a target approximate DRAM device to increase the DNN's error tolerance, and 2) efficient mapping of the error tolerance of each individual DNN data type to a corresponding approximate DRAM partition in a way that meets the user-specified DNN accuracy requirements. We evaluate EDEN on multi-core CPUs, GPUs, and DNN accelerators with error models obtained from real approximate DRAM devices. For a target accuracy within 1% of the original DNN, our results show that EDEN enables 1) an average DRAM energy reduction of 21%, 37%, 31%, and 32% in CPU, GPU, and two DNN accelerator architectures, respectively, across a variety of DNNs, and 2) an average (maximum) speedup of 8% (17%) and 2.7% (5.5%) in CPU and GPU architectures, respectively, when evaluating latency-bound DNNs.