 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEON: Enabling Efficient Support for Nonlinear Operations in Resistive RAM-based Neural Network Accelerators
Nov 10, 2022Resistive Random-Access Memory (RRAM) is well-suited to accelerate neural network (NN) workloads as RRAM-based Processing-in-Memory (PIM) architectures natively support highly-parallel multiply-accumulate (MAC) operations that form the backbone of most NN workloads. Unfortunately, NN workloads such as transformers require support for non-MAC operations (e.g., softmax) that RRAM cannot provide natively. Consequently, state-of-the-art works either integrate additional digital logic circuits to support the non-MAC operations or offload the non-MAC operations to CPU/GPU, resulting in significant performance and energy efficiency overheads due to data movement. In this work, we propose NEON, a novel compiler optimization to enable the end-to-end execution of the NN workload in RRAM. The key idea of NEON is to transform each non-MAC operation into a lightweight yet highly-accurate neural network. Utilizing neural networks to approximate the non-MAC operations provides two advantages: 1) We can exploit the key strength of RRAM, i.e., highly-parallel MAC operation, to flexibly and efficiently execute non-MAC operations in memory. 2) We can simplify RRAM's microarchitecture by eliminating the additional digital logic circuits while reducing the data movement overheads. Acceleration of the non-MAC operations in memory enables NEON to achieve a 2.28x speedup compared to an idealized digital logic-based RRAM. We analyze the trade-offs associated with the transformation and demonstrate feasible use cases for NEON across different substrates.
EcoFlow: Efficient Convolutional Dataflows for Low-Power Neural Network Accelerators
Feb 04, 2022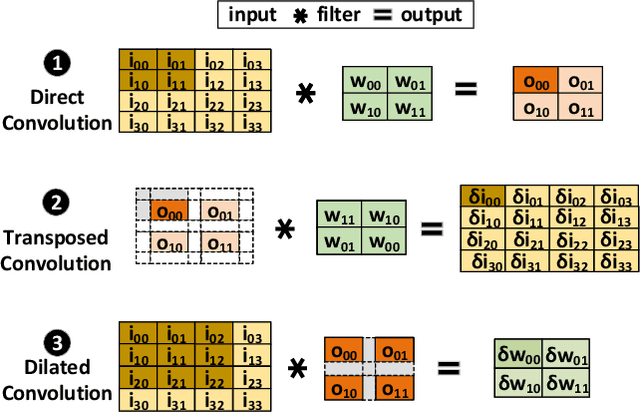

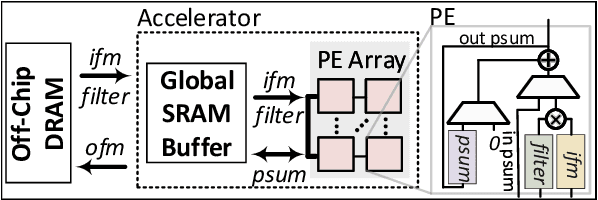
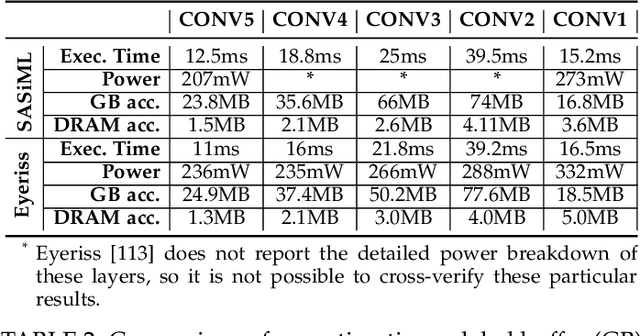
Dilated and transposed convolutions are widely used in modern convolutional neural networks (CNNs). These kernels are used extensively during CNN training and inference of applications such as image segmentation and high-resolution image generation. Although these kernels have grown in popularity, they stress current compute systems due to their high memory intensity, exascale compute demands, and large energy consumption. We find that commonly-used low-power CNN inference accelerators based on spatial architectures are not optimized for both of these convolutional kernels. Dilated and transposed convolutions introduce significant zero padding when mapped to the underlying spatial architecture, significantly degrading performance and energy efficiency. Existing approaches that address this issue require significant design changes to the otherwise simple, efficient, and well-adopted architectures used to compute direct convolutions. To address this challenge, we propose EcoFlow, a new set of dataflows and mapping algorithms for dilated and transposed convolutions. These algorithms are tailored to execute efficiently on existing low-cost, small-scale spatial architectures and requires minimal changes to the network-on-chip of existing accelerators. EcoFlow eliminates zero padding through careful dataflow orchestration and data mapping tailored to the spatial architecture. EcoFlow enables flexible and high-performance transpose and dilated convolutions on architectures that are otherwise optimized for CNN inference. We evaluate the efficiency of EcoFlow on CNN training workloads and Generative Adversarial Network (GAN) training workloads. Experiments in our new cycle-accurate simulator show that EcoFlow 1) reduces end-to-end CNN training time between 7-85%, and 2) improves end-to-end GAN training performance between 29-42%, compared to state-of-the-art CNN inference accelerators.
Robust Machine Learning Systems: Challenges, Current Trends, Perspectives, and the Road Ahead
Jan 04, 2021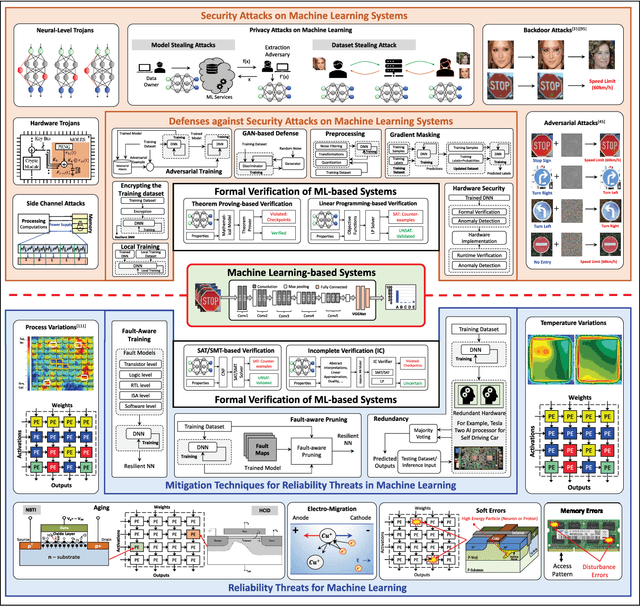

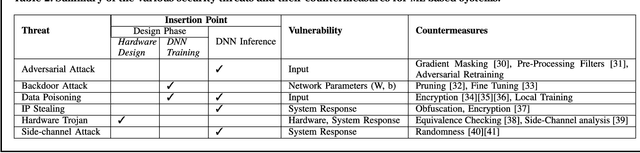
Machine Learning (ML) techniques have been rapidly adopted by smart Cyber-Physical Systems (CPS) and Internet-of-Things (IoT) due to their powerful decision-making capabilities. However, they are vulnerable to various security and reliability threats, at both hardware and software levels, that compromise their accuracy. These threats get aggravated in emerging edge ML devices that have stringent constraints in terms of resources (e.g., compute, memory, power/energy), and that therefore cannot employ costly security and reliability measures. Security, reliability, and vulnerability mitigation techniques span from network security measures to hardware protection, with an increased interest towards formal verification of trained ML models. This paper summarizes the prominent vulnerabilities of modern ML systems, highlights successful defenses and mitigation techniques against these vulnerabilities, both at the cloud (i.e., during the ML training phase) and edge (i.e., during the ML inference stage), discusses the implications of a resource-constrained design on the reliability and security of the system, identifies verification methodologies to ensure correct system behavior, and describes open research challenges for building secure and reliable ML systems at both the edge and the cloud.
* Final version appears in https://ieeexplore.ieee.org/document/8979377
EDEN: Enabling Energy-Efficient, High-Performance Deep Neural Network Inference Using Approximate DRAM
Oct 12, 2019
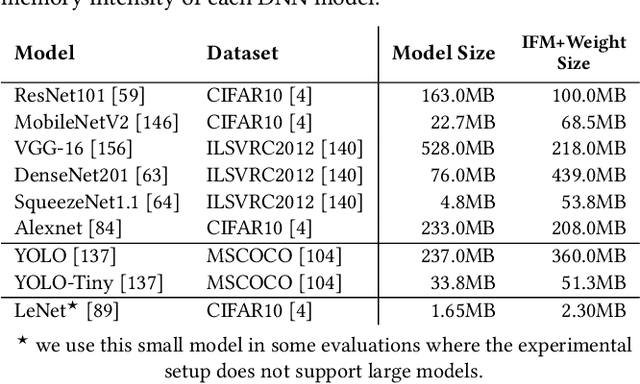
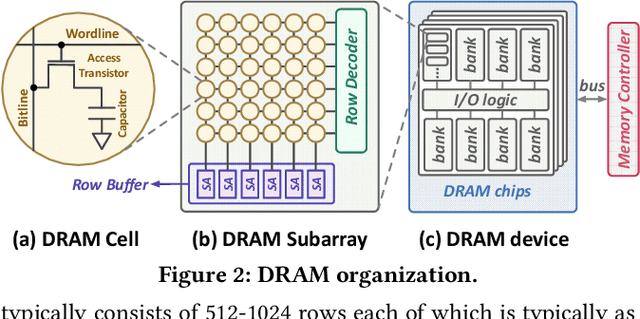
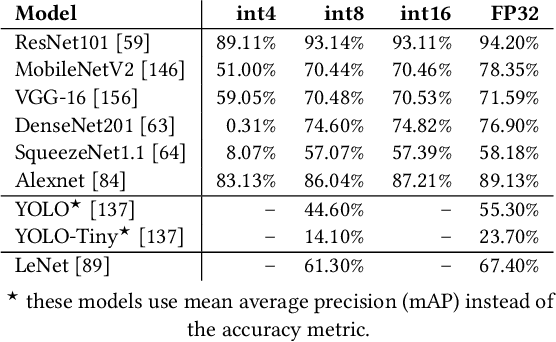
The effectiveness of deep neural networks (DNN) in vision, speech, and language processing has prompted a tremendous demand for energy-efficient high-performance DNN inference systems. Due to the increasing memory intensity of most DNN workloads, main memory can dominate the system's energy consumption and stall time. One effective way to reduce the energy consumption and increase the performance of DNN inference systems is by using approximate memory, which operates with reduced supply voltage and reduced access latency parameters that violate standard specifications. Using approximate memory reduces reliability, leading to higher bit error rates. Fortunately, neural networks have an intrinsic capacity to tolerate increased bit errors. This can enable energy-efficient and high-performance neural network inference using approximate DRAM devices. Based on this observation, we propose EDEN, a general framework that reduces DNN energy consumption and DNN evaluation latency by using approximate DRAM devices, while strictly meeting a user-specified target DNN accuracy. EDEN relies on two key ideas: 1) retraining the DNN for a target approximate DRAM device to increase the DNN's error tolerance, and 2) efficient mapping of the error tolerance of each individual DNN data type to a corresponding approximate DRAM partition in a way that meets the user-specified DNN accuracy requirements. We evaluate EDEN on multi-core CPUs, GPUs, and DNN accelerators with error models obtained from real approximate DRAM devices. For a target accuracy within 1% of the original DNN, our results show that EDEN enables 1) an average DRAM energy reduction of 21%, 37%, 31%, and 32% in CPU, GPU, and two DNN accelerator architectures, respectively, across a variety of DNNs, and 2) an average (maximum) speedup of 8% (17%) and 2.7% (5.5%) in CPU and GPU architectures, respectively, when evaluating latency-bound DNNs.