 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Global Neural Architecture Search
Feb 05, 2025
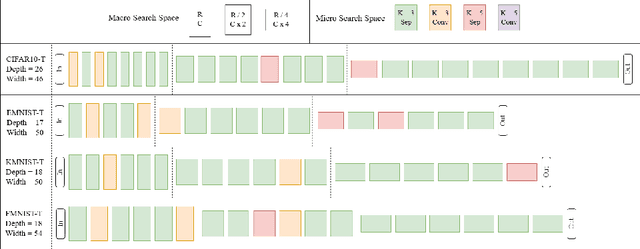

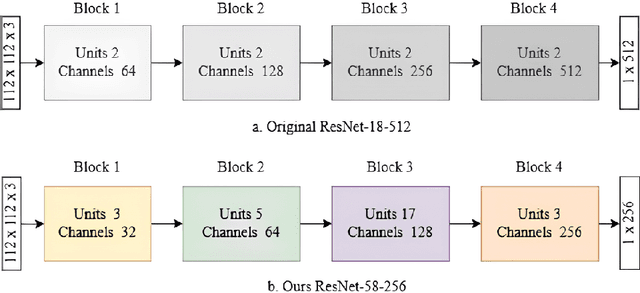
Neural architecture search (NAS) has shown promise towards automating neural network design for a given task, but it is computationally demanding due to training costs associated with evaluating a large number of architectures to find the optimal one. To speed up NAS, recent works limit the search to network building blocks (modular search) instead of searching the entire architecture (global search), approximate candidates' performance evaluation in lieu of complete training, and use gradient descent rather than naturally suitable discrete optimization approaches. However, modular search does not determine network's macro architecture i.e. depth and width, demanding manual trial and error post-search, hence lacking automation. In this work, we revisit NAS and design a navigable, yet architecturally diverse, macro-micro search space. In addition, to determine relative rankings of candidates, existing methods employ consistent approximations across entire search spaces, whereas different networks may not be fairly comparable under one training protocol. Hence, we propose an architecture-aware approximation with variable training schemes for different networks. Moreover, we develop an efficient search strategy by disjoining macro-micro network design that yields competitive architectures in terms of both accuracy and size. Our proposed framework achieves a new state-of-the-art on EMNIST and KMNIST, while being highly competitive on the CIFAR-10, CIFAR-100, and FashionMNIST datasets and being 2-4x faster than the fastest global search methods. Lastly, we demonstrate the transferability of our framework to real-world computer vision problems by discovering competitive architectures for face recognition applications.
Spatiotemporal Object Detection for Improved Aerial Vehicle Detection in Traffic Monitoring
Oct 17, 2024



This work presents advancements in multi-class vehicle detection using UAV cameras through the development of spatiotemporal object detection models. The study introduces a Spatio-Temporal Vehicle Detection Dataset (STVD) containing 6, 600 annotated sequential frame images captured by UAVs, enabling comprehensive training and evaluation of algorithms for holistic spatiotemporal perception. A YOLO-based object detection algorithm is enhanced to incorporate temporal dynamics, resulting in improved performance over single frame models. The integration of attention mechanisms into spatiotemporal models is shown to further enhance performance. Experimental validation demonstrates significant progress, with the best spatiotemporal model exhibiting a 16.22% improvement over single frame models, while it is demonstrated that attention mechanisms hold the potential for additional performance gains.
* 13 pages
DiRecNetV2: A Transformer-Enhanced Network for Aerial Disaster Recognition
Oct 17, 2024The integration of Unmanned Aerial Vehicles (UAVs) with artificial intelligence (AI) models for aerial imagery processing in disaster assessment, necessitates models that demonstrate exceptional accuracy, computational efficiency, and real-time processing capabilities. Traditionally Convolutional Neural Networks (CNNs), demonstrate efficiency in local feature extraction but are limited by their potential for global context interpretation. On the other hand, Vision Transformers (ViTs) show promise for improved global context interpretation through the use of attention mechanisms, although they still remain underinvestigated in UAV-based disaster response applications. Bridging this research gap, we introduce DiRecNetV2, an improved hybrid model that utilizes convolutional and transformer layers. It merges the inductive biases of CNNs for robust feature extraction with the global context understanding of Transformers, maintaining a low computational load ideal for UAV applications. Additionally, we introduce a new, compact multi-label dataset of disasters, to set an initial benchmark for future research, exploring how models trained on single-label data perform in a multi-label test set. The study assesses lightweight CNNs and ViTs on the AIDERSv2 dataset, based on the frames per second (FPS) for efficiency and the weighted F1 scores for classification performance. DiRecNetV2 not only achieves a weighted F1 score of 0.964 on a single-label test set but also demonstrates adaptability, with a score of 0.614 on a complex multi-label test set, while functioning at 176.13 FPS on the Nvidia Orin Jetson device.
* 23 pages
Toward Efficient Convolutional Neural Networks With Structured Ternary Patterns
Jul 20, 2024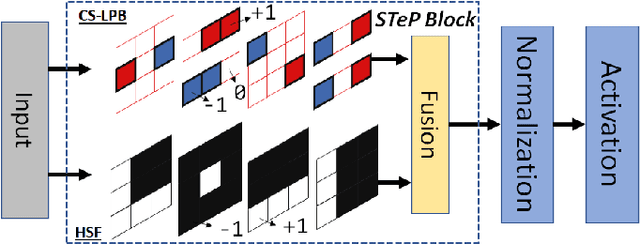

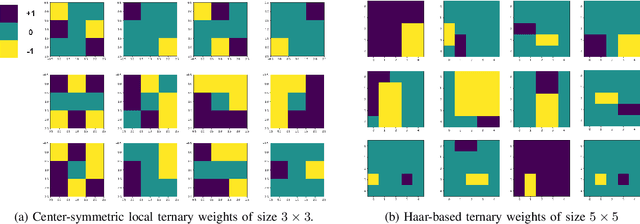
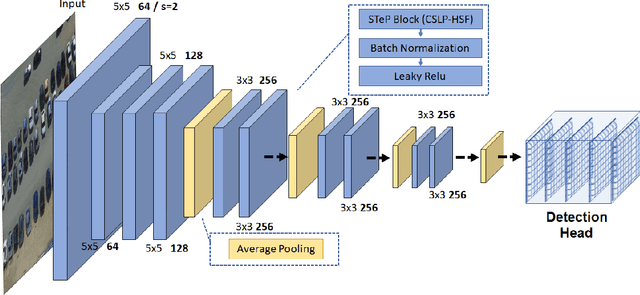
High-efficiency deep learning (DL) models are necessary not only to facilitate their use in devices with limited resources but also to improve resources required for training. Convolutional neural networks (ConvNets) typically exert severe demands on local device resources and this conventionally limits their adoption within mobile and embedded platforms. This brief presents work toward utilizing static convolutional filters generated from the space of local binary patterns (LBPs) and Haar features to design efficient ConvNet architectures. These are referred to as Structured Ternary Patterns (STePs) and can be generated during network initialization in a systematic way instead of having learnable weight parameters thus reducing the total weight updates. The ternary values require significantly less storage and with the appropriate low-level implementation, can also lead to inference improvements. The proposed approach is validated using four image classification datasets, demonstrating that common network backbones can be made more efficient and provide competitive results. It is also demonstrated that it is possible to generate completely custom STeP-based networks that provide good trade-offs for on-device applications such as unmanned aerial vehicle (UAV)-based aerial vehicle detection. The experimental results show that the proposed method maintains high detection accuracy while reducing the trainable parameters by 40-80%. This work motivates further research toward good priors for non-learnable weights that can make DL architectures more efficient without having to alter the network during or after training.
Convolutional Channel-wise Competitive Learning for the Forward-Forward Algorithm
Dec 19, 2023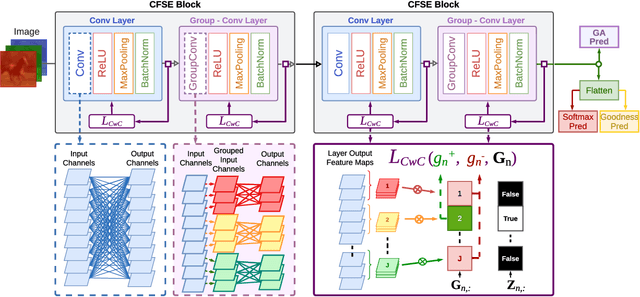
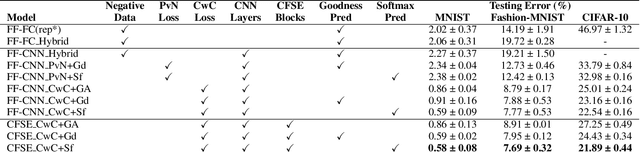

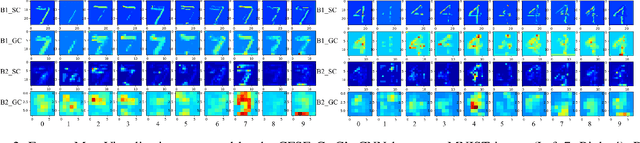
The Forward-Forward (FF) Algorithm has been recently proposed to alleviate the issues of backpropagation (BP) commonly used to train deep neural networks. However, its current formulation exhibits limitations such as the generation of negative data, slower convergence, and inadequate performance on complex tasks. In this paper, we take the main ideas of FF and improve them by leveraging channel-wise competitive learning in the context of convolutional neural networks for image classification tasks. A layer-wise loss function is introduced that promotes competitive learning and eliminates the need for negative data construction. To enhance both the learning of compositional features and feature space partitioning, a channel-wise feature separator and extractor block is proposed that complements the competitive learning process. Our method outperforms recent FF-based models on image classification tasks, achieving testing errors of 0.58%, 7.69%, 21.89%, and 48.77% on MNIST, Fashion-MNIST, CIFAR-10 and CIFAR-100 respectively. Our approach bridges the performance gap between FF learning and BP methods, indicating the potential of our proposed approach to learn useful representations in a layer-wise modular fashion, enabling more efficient and flexible learning.
DriveGuard: Robustification of Automated Driving Systems with Deep Spatio-Temporal Convolutional Autoencoder
Nov 05, 2021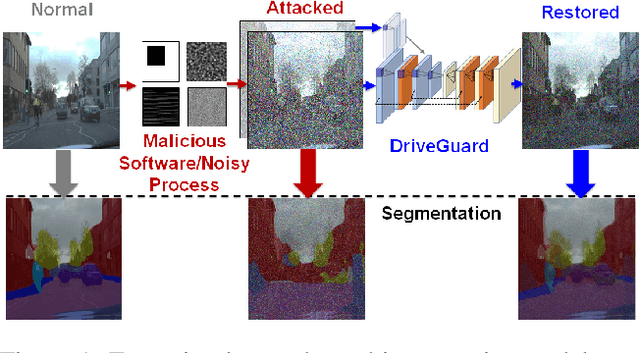
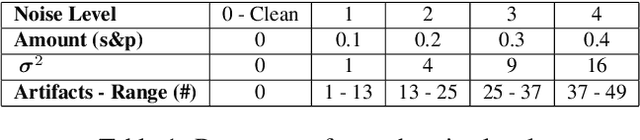
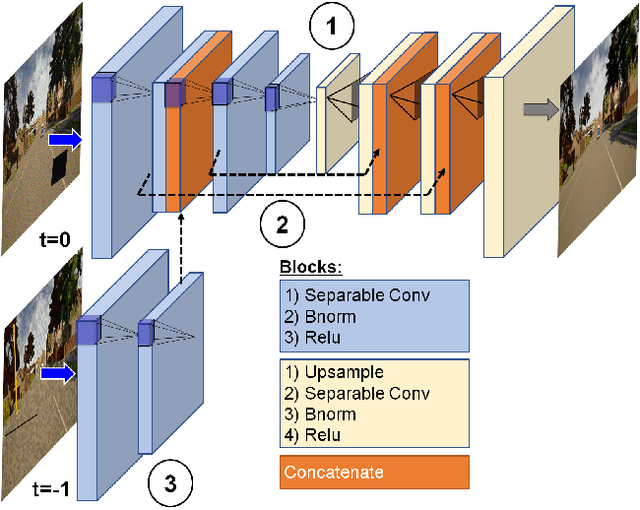

Autonomous vehicles increasingly rely on cameras to provide the input for perception and scene understanding and the ability of these models to classify their environment and objects, under adverse conditions and image noise is crucial. When the input is, either unintentionally or through targeted attacks, deteriorated, the reliability of autonomous vehicle is compromised. In order to mitigate such phenomena, we propose DriveGuard, a lightweight spatio-temporal autoencoder, as a solution to robustify the image segmentation process for autonomous vehicles. By first processing camera images with DriveGuard, we offer a more universal solution than having to re-train each perception model with noisy input. We explore the space of different autoencoder architectures and evaluate them on a diverse dataset created with real and synthetic images demonstrating that by exploiting spatio-temporal information combined with multi-component loss we significantly increase robustness against adverse image effects reaching within 5-6% of that of the original model on clean images.
C^3Net: End-to-End deep learning for efficient real-time visual active camera control
Jul 28, 2021
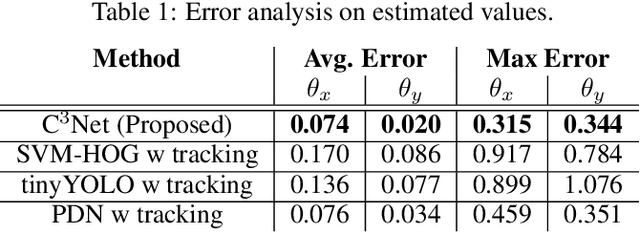


The need for automated real-time visual systems in applications such as smart camera surveillance, smart environments, and drones necessitates the improvement of methods for visual active monitoring and control. Traditionally, the active monitoring task has been handled through a pipeline of modules such as detection, filtering, and control. However, such methods are difficult to jointly optimize and tune their various parameters for real-time processing in resource constraint systems. In this paper a deep Convolutional Camera Controller Neural Network is proposed to go directly from visual information to camera movement to provide an efficient solution to the active vision problem. It is trained end-to-end without bounding box annotations to control a camera and follow multiple targets from raw pixel values. Evaluation through both a simulation framework and real experimental setup, indicate that the proposed solution is robust to varying conditions and able to achieve better monitoring performance than traditional approaches both in terms of number of targets monitored as well as in effective monitoring time. The advantage of the proposed approach is that it is computationally less demanding and can run at over 10 FPS (~4x speedup) on an embedded smart camera providing a practical and affordable solution to real-time active monitoring.
Fast and Accurate Quantized Camera Scene Detection on Smartphones, Mobile AI 2021 Challenge: Report
May 17, 2021
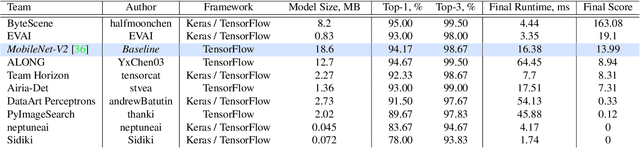
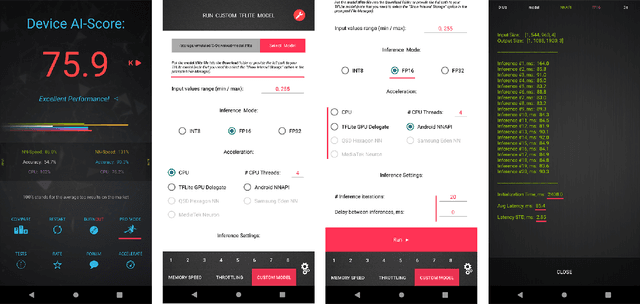

Camera scene detection is among the most popular computer vision problem on smartphones. While many custom solutions were developed for this task by phone vendors, none of the designed models were available publicly up until now. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop quantized deep learning-based camera scene classification solutions that can demonstrate a real-time performance on smartphones and IoT platforms. For this, the participants were provided with a large-scale CamSDD dataset consisting of more than 11K images belonging to the 30 most important scene categories. The runtime of all models was evaluated on the popular Apple Bionic A11 platform that can be found in many iOS devices. The proposed solutions are fully compatible with all major mobile AI accelerators and can demonstrate more than 100-200 FPS on the majority of recent smartphone platforms while achieving a top-3 accuracy of more than 98%. A detailed description of all models developed in the challenge is provided in this paper.
EmergencyNet: Efficient Aerial Image Classification for Drone-Based Emergency Monitoring Using Atrous Convolutional Feature Fusion
Apr 28, 2021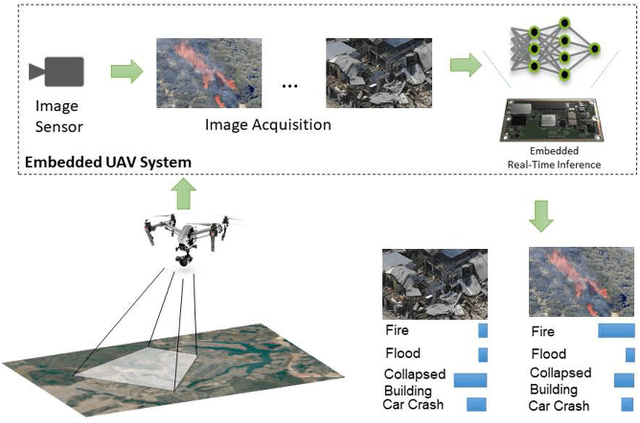



Deep learning-based algorithms can provide state-of-the-art accuracy for remote sensing technologies such as unmanned aerial vehicles (UAVs)/drones, potentially enhancing their remote sensing capabilities for many emergency response and disaster management applications. In particular, UAVs equipped with camera sensors can operating in remote and difficult to access disaster-stricken areas, analyze the image and alert in the presence of various calamities such as collapsed buildings, flood, or fire in order to faster mitigate their effects on the environment and on human population. However, the integration of deep learning introduces heavy computational requirements, preventing the deployment of such deep neural networks in many scenarios that impose low-latency constraints on inference, in order to make mission-critical decisions in real time. To this end, this article focuses on the efficient aerial image classification from on-board a UAV for emergency response/monitoring applications. Specifically, a dedicated Aerial Image Database for Emergency Response applications is introduced and a comparative analysis of existing approaches is performed. Through this analysis a lightweight convolutional neural network architecture is proposed, referred to as EmergencyNet, based on atrous convolutions to process multiresolution features and capable of running efficiently on low-power embedded platforms achieving upto 20x higher performance compared to existing models with minimal memory requirements with less than 1% accuracy drop compared to state-of-the-art models.
* C.Kyrkou and T. Theocharides, "EmergencyNet: Efficient Aerial Image Classification for Drone-Based Emergency Monitoring Using Atrous Convolutional Feature Fusion," in IEEE J Sel Top Appl Earth Obs Remote Sens. (JSTARS), vol. 13, pp. 1687-1699, 2020. arXiv admin note: substantial text overlap with arXiv:1906.08716
Robust Machine Learning Systems: Challenges, Current Trends, Perspectives, and the Road Ahead
Jan 04, 2021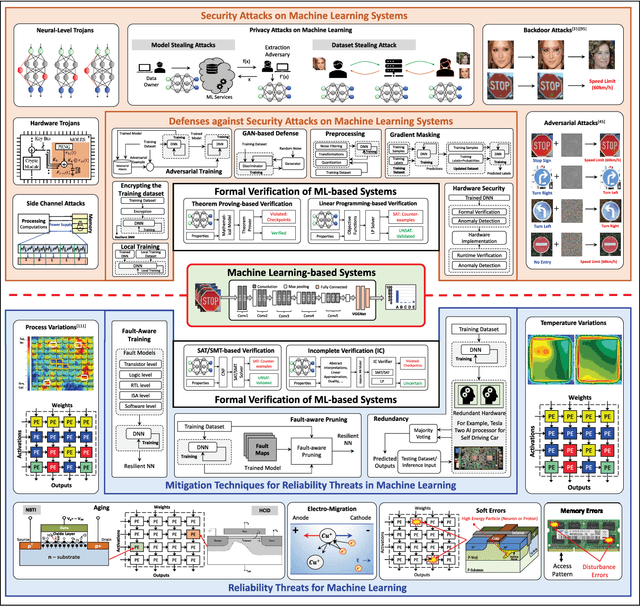

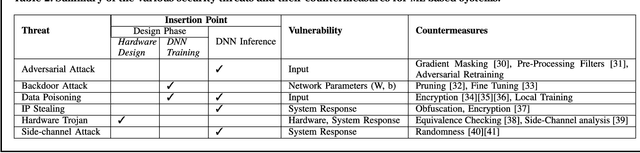
Machine Learning (ML) techniques have been rapidly adopted by smart Cyber-Physical Systems (CPS) and Internet-of-Things (IoT) due to their powerful decision-making capabilities. However, they are vulnerable to various security and reliability threats, at both hardware and software levels, that compromise their accuracy. These threats get aggravated in emerging edge ML devices that have stringent constraints in terms of resources (e.g., compute, memory, power/energy), and that therefore cannot employ costly security and reliability measures. Security, reliability, and vulnerability mitigation techniques span from network security measures to hardware protection, with an increased interest towards formal verification of trained ML models. This paper summarizes the prominent vulnerabilities of modern ML systems, highlights successful defenses and mitigation techniques against these vulnerabilities, both at the cloud (i.e., during the ML training phase) and edge (i.e., during the ML inference stage), discusses the implications of a resource-constrained design on the reliability and security of the system, identifies verification methodologies to ensure correct system behavior, and describes open research challenges for building secure and reliable ML systems at both the edge and the cloud.
* Final version appears in https://ieeexplore.ieee.org/document/8979377