 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Channel-wise Competitive Learning for the Forward-Forward Algorithm
Dec 19, 2023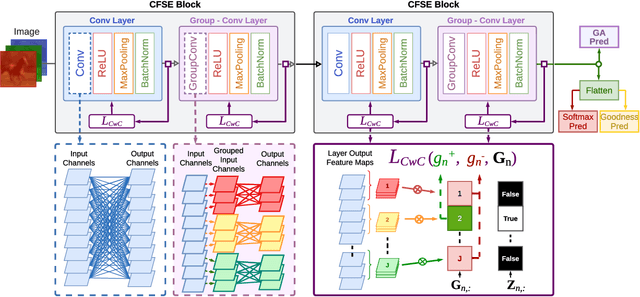
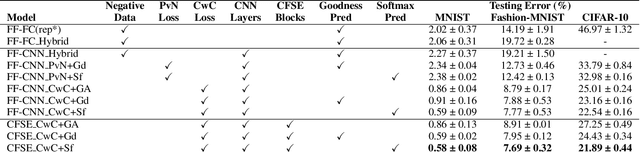

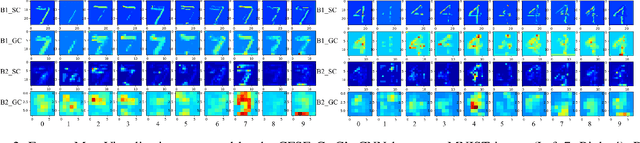
The Forward-Forward (FF) Algorithm has been recently proposed to alleviate the issues of backpropagation (BP) commonly used to train deep neural networks. However, its current formulation exhibits limitations such as the generation of negative data, slower convergence, and inadequate performance on complex tasks. In this paper, we take the main ideas of FF and improve them by leveraging channel-wise competitive learning in the context of convolutional neural networks for image classification tasks. A layer-wise loss function is introduced that promotes competitive learning and eliminates the need for negative data construction. To enhance both the learning of compositional features and feature space partitioning, a channel-wise feature separator and extractor block is proposed that complements the competitive learning process. Our method outperforms recent FF-based models on image classification tasks, achieving testing errors of 0.58%, 7.69%, 21.89%, and 48.77% on MNIST, Fashion-MNIST, CIFAR-10 and CIFAR-100 respectively. Our approach bridges the performance gap between FF learning and BP methods, indicating the potential of our proposed approach to learn useful representations in a layer-wise modular fashion, enabling more efficient and flexible learning.
DriveGuard: Robustification of Automated Driving Systems with Deep Spatio-Temporal Convolutional Autoencoder
Nov 05, 2021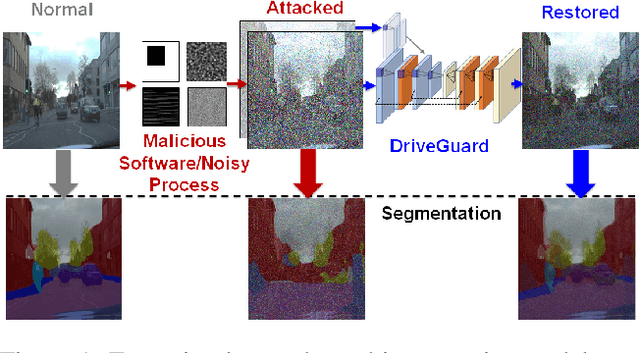
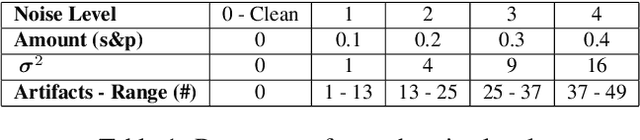
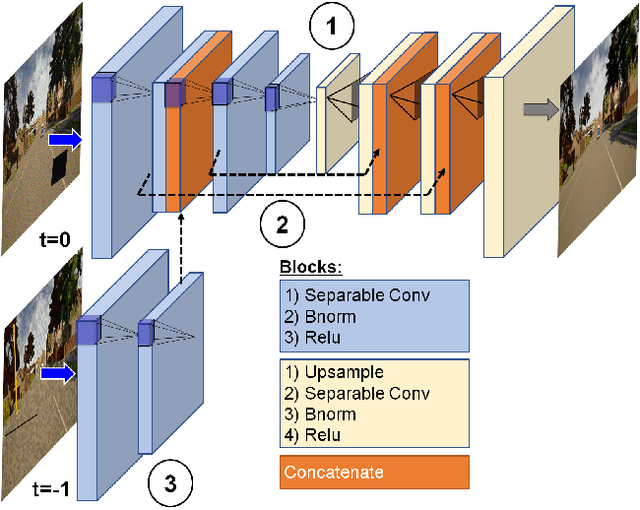

Autonomous vehicles increasingly rely on cameras to provide the input for perception and scene understanding and the ability of these models to classify their environment and objects, under adverse conditions and image noise is crucial. When the input is, either unintentionally or through targeted attacks, deteriorated, the reliability of autonomous vehicle is compromised. In order to mitigate such phenomena, we propose DriveGuard, a lightweight spatio-temporal autoencoder, as a solution to robustify the image segmentation process for autonomous vehicles. By first processing camera images with DriveGuard, we offer a more universal solution than having to re-train each perception model with noisy input. We explore the space of different autoencoder architectures and evaluate them on a diverse dataset created with real and synthetic images demonstrating that by exploiting spatio-temporal information combined with multi-component loss we significantly increase robustness against adverse image effects reaching within 5-6% of that of the original model on clean images.