 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Global Neural Architecture Search
Paper and Code

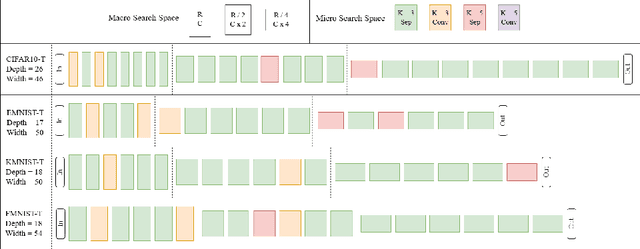

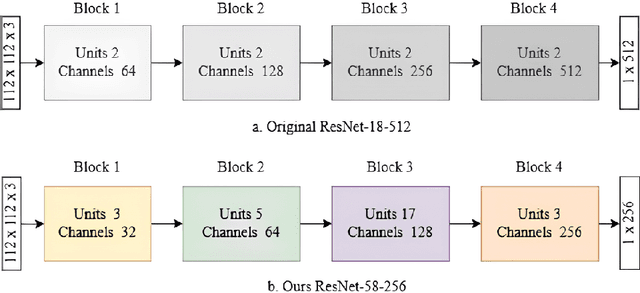
Neural architecture search (NAS) has shown promise towards automating neural network design for a given task, but it is computationally demanding due to training costs associated with evaluating a large number of architectures to find the optimal one. To speed up NAS, recent works limit the search to network building blocks (modular search) instead of searching the entire architecture (global search), approximate candidates' performance evaluation in lieu of complete training, and use gradient descent rather than naturally suitable discrete optimization approaches. However, modular search does not determine network's macro architecture i.e. depth and width, demanding manual trial and error post-search, hence lacking automation. In this work, we revisit NAS and design a navigable, yet architecturally diverse, macro-micro search space. In addition, to determine relative rankings of candidates, existing methods employ consistent approximations across entire search spaces, whereas different networks may not be fairly comparable under one training protocol. Hence, we propose an architecture-aware approximation with variable training schemes for different networks. Moreover, we develop an efficient search strategy by disjoining macro-micro network design that yields competitive architectures in terms of both accuracy and size. Our proposed framework achieves a new state-of-the-art on EMNIST and KMNIST, while being highly competitive on the CIFAR-10, CIFAR-100, and FashionMNIST datasets and being 2-4x faster than the fastest global search methods. Lastly, we demonstrate the transferability of our framework to real-world computer vision problems by discovering competitive architectures for face recognition applications.